
为什么主流大模型的上下文窗口都是128k?| 深度


近期 AI 圈正在流行一个新的概念——Context Engineering(上下文工程),它被 AI 专家安德烈·卡帕西称为“在上下文窗口中填充下一步所需的恰到好处的信息的精细艺术与科学”。
上下文工程的前提是大模型充足的上下文窗口。如果梳理大模型的上下文窗口会发现,今天主流模型基本都把 128k 作为上下文的标准长度。
在闭源模型阵营中,GPT-4-Turbo、GPT-4o 都支持 128k 上下文窗口,Gemini 1.5 Pro 也以 128k 作为标准窗口(企业版可选更高);在开源模型阵营中,Qwen3 系列将 128k 作为上下文标配,DeepSeek V3/R1 的官方最大上下文长度是128k,近期刚刚发布的 Kimi K2 的上下文长度也是 128k 。
当然,很多模型也在尝试把上下文拓展到更大的长度。比如,PPIO 将 DeepSeek V3/R1 的上下文窗口的最大输入、最大输出拓展到了 160k,Gemini 2.5 Pro、MiniMax-M1 以及 GPT-4.1 已经开始探索百万上下文长度。
不过,相比而言,128k 仍然是业务最成熟、最主流的长度。背后的原因是什么呢?
# 01
上下文是大模型研究的核心问题
上下文为什么很重要?因为上下文就是大模型的“记忆”。记忆与智力本就一体两面,上下文窗口越大,模型一次能记住的内容就越多,也就越聪明、越连贯。
大模型的发展史,本身也是上下文窗口的扩展史。
实际上,当 2017 年《Attention is all you need》这篇论文发布的时候,它要解决的最核心的问题,就是传统 RNN 模型的上下文窗口的局限。这篇论文提到,“建模远距离依赖”是序列建模研究的核心问题,而 Transformer 就是为了解决它。
简单来说,RNN 模型的“阅读”文本信息的习惯跟人相似,是从前往后依次阅读,读得越久,就越容易忘记前面的内容。当文本信息越来越长时,RNN 就无法学习到长距离文本之间的信息关联。而且,这种串行的计算方式,效率也很低。
但 Transformer 从模型架构上做了一次“改头换面”的改变。它提出的自注意力机制(Self-Attention),在“阅读”文本信息时并非从前往后依次阅读,而是能一次性阅读整个上下文,并根据上下文的相关性赋予不同的权重。比如“苹果”一词,在有的上下文里是水果,有的上下文里是手机。同时,Transformer 通过并行计算的方式提高了处理效率。
由于 Transformer 能够高效地处理长文本、长音频等复杂数据,从而在自然语言处理、机器翻译、文本生成等众多领域取得了显著的性能提升。从 GPT 到 Claude,从 Kimi 到 DeepSeek,全都选了 Transformer 作为底层架构。
Transformer 的出现彻底解锁了模型上下文长度的局限。
传统 RNN 模型通常只能处理 几十到上百 tokens 的文本,而基于 Transformer 架构的初代 GPT-1,上下文已经达到 512 tokens,随后每一代模型都比前一代拥有更长的上下文。到 OpenAI 发布 GPT-4 Turbo 时,上下文已达到 128k,一口气可以读完一本《三体》,比初代 GPT-1 提升了 250 倍。
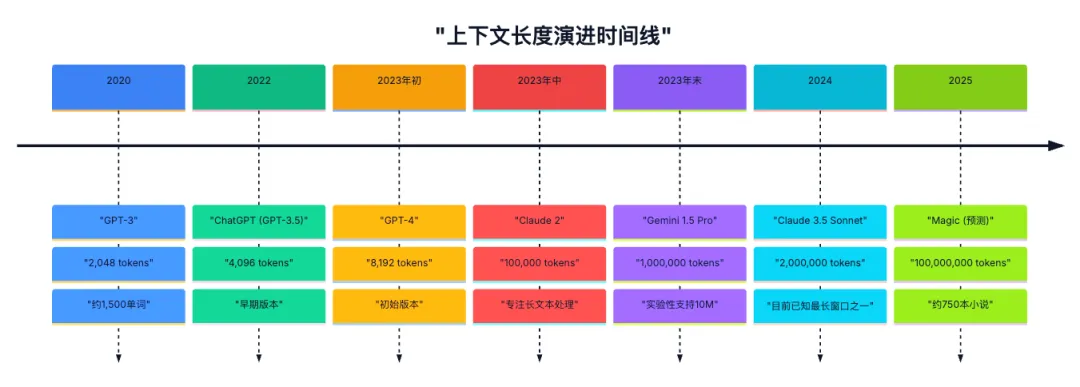
今天,一些大模型的上下文的长度已经触探到了 100万 tokens,比如 GPT-4.1、Gemini 2.5 Pro 以及 MiniMax-M1。不过,百万上下文长度的模型尚未大规模普及,128k 才是最常见的标配长度。OpenAI 的主力模型 GPT-4o、阿里最新发布的 Qwen 3 系列、DeepSeek V3/R1、月之暗面最新发布的 Kimi K2 等模型,都把 128k 作为最大标配上下文。
为什么更大的 100 万上下文反而没有更小的 128k 上下文更加普及?这背后,实际上是技术与成本的一场博弈。
# 02
为什么 128k 成为上下文标配?
上下文窗口的拓展并非没有代价,这与 Transformer 架构的原生限制有关系。
由于 Transformer 的自注意力机制需要计算序列中任意两个位置之间的相关性,其计算和内存复杂度与序列长度呈二次关系(O(n²))。也就是说,当上下文窗口从 4k 增加到 128k(32倍)时,理论上的计算量和内存需求的增长不是 32 倍,而是 1024 倍,这为GPU的计算能力和显存带来了巨大的挑战。
当处理一个 128k 的 token 序列,即使是像 LLaMA 70B 这样的模型,也需要将近 80GB 的 GPU 显存,这几乎耗尽了一块 NVIDIA A100 80GB GPU 的全部资源。
对于更大规模的模型,单一 GPU 无法承载,必须依赖多 GPU 并行计算,这进一步增加了系统复杂性和通信开销。如果要对 128k 上下文进行训练或推理,团队可能需要 8 张 A100 80GB GPU(总显存 ∼480GB)来存储 KV 缓存和中间激活。相比之下,32k 上下文只需大约 2 张 A100 卡即可运行。
在延迟方面,处理更长上下文自然更慢。OpenAI 在 GPT-4.1 系列评测中报告:在优化后的推理系统下,用 128k tokens 上下文时,大约需要 15 秒能输出第一个 token,而同样处理 1M tokens 时则接近 60 秒。也就是说,在同样硬件下,从 128k 增加到百万级上下文,响应时间约增长 4 倍以上。
除了成本限制,从实用性考量来看,128k 上下文(约等于 200 页的文本)已经能满足许多实际场景。
在法律、科研或企业数据分析等文档问答和检索增强(RAG)场景中,经常需要对多份长文档进行问答。128k 上下文可以一次性将多本法律条文、政策文档或大量会话记录提供给模型。
在代码理解与软件工程中,软件项目通常包含多文件和库,单一文件可能已超过几万行。GPT-4o mini 博客提到,可以把“整个代码库”传给模型处理。
在客户服务、虚拟助手或复杂的多轮人机交互中,保持对话的连贯性和记住早期的关键信息至关重要。一个 128k 的上下文窗口足以容纳数小时甚至数天的对话历史,使得模型能够更好地理解用户的意图、偏好和上下文,从而提供更个性化、更相关的回复,避免重复提问或给出前后矛盾的答案。
然而,并非所有应用都需要如此长的上下文。对于一些简单的任务,如短文本分类、情感分析或基础的问答,一个较小的上下文窗口(如 4k 或 8k)可能已经足够,使用过长的窗口反而会增加不必要的计算开销和延迟 。
从 4k 到 128k,用户能感知的体验提升是巨大的,许多之前无法实现的任务变得可能。但从 128k 继续向上增加,对于大部分普通用户和常规任务而言,其带来的边际效用是递减的。只有少数特定领域的专业用户(如基因序列分析、超长篇巨著研究)才对百万级上下文有刚性需求。
因此,128k 就成为了目前最广泛应用的上下文长度。
# 03
哪些技术引领上下文革命?
长文本上下文能力的提升并非单一技术突破的结果,而是模型架构、注意力机制、训练策略以及工程优化等多个层面协同创新的产物。这些技术共同作用,使得模型能够更有效地处理和理解更长的输入序列,同时在一定程度上缓解了随之而来的计算和内存开销问题。
首先是模型架构的演进。
2017 年 Transformer 架构创新性提出了“自注意力机制”以及“并行计算”,为后来的模型架构改进奠定了基础。2019年,Transformer XL 架构引入段级循环机制和相对位置编码两个关键技术,突破了固定长度上下文的限制,能够更好地捕捉长距离依赖关系。
2023 年,OpenAI 发布的 GPT-4 后来被证实采用了混合专家系统(MoE)架构,这一架构通过在模型内部引入多个专家子网络,并根据输入动态激活部分专家,实现模型的稀疏激活,在保持模型能力的同时显著降低计算量。MoE 架构使得构建参数量更大、能力更强的模型成为可能,而这些大规模模型通常也具备更强的长上下文处理能力。
其次是注意力机制的优化。注意力机制是 Transformer 架构的核心,也是处理长上下文的关键。
标准的全注意力机制(Full Attention)具有 O(n²)的时间和空间复杂度,这严重限制了其在超长序列上的应用。因此,对注意力机制进行优化,以降低其计算和内存开销,同时尽可能保留其捕捉长距离依赖的能力,成为了推动长上下文发展的重中之重。
降低计算复杂度的优化算法,主要在于各种注意力机制的变体,包括稀疏注意力机制(Sparse Attention)、滑动窗口注意力(Sliding Window Attention)、全局注意力(Global Attention)、随机注意力(Random Attention)等。比如,DeepSeek 发布的 Native Sparse Attention(NSA),就是一种硬件对齐且可原生训练的稀疏注意力机制。
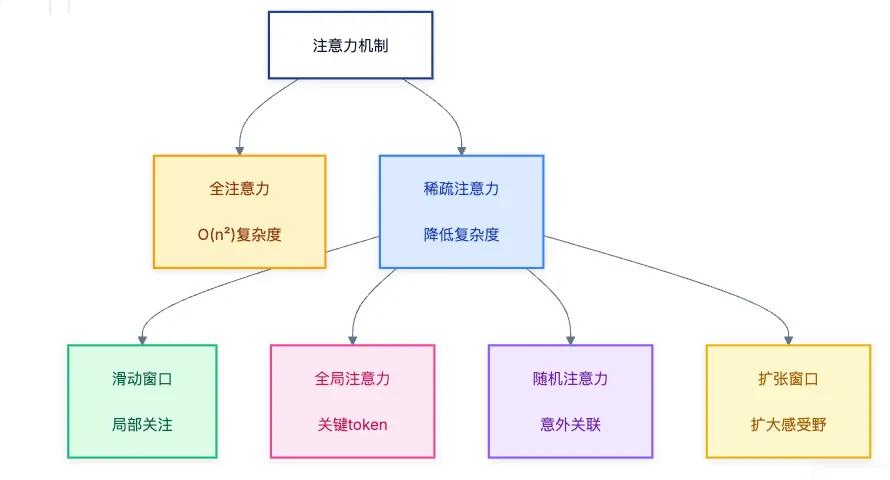
降低内存开销的优化算法,主要在于 KV Cache 优化与动态稀疏化。比如谷歌提出的多头注意力MHA,以及其多种变体MQA、GQA,以及 DeepSeek 提出的 MLA,都是为了降低 KV Cache。
除了模型架构和注意力机制的革新,工程层面的优化也是推动长上下文能力发展不可或缺的一环。这些创新主要集中在提升计算效率、降低内存占用以及优化训练和推理过程。
例如,DeepSeek 的 NSA 注意力机制就特别强调了硬件对齐优化,通过内存高效的内核设计、平衡的算术强度以及 SRAM 缓存利用,实现了显著的加速效果;月之暗面发布的 Mooncake 采用以 KVCache 为中心的解耦架构,将预填充集群和解码集群分离,并充分利用 GPU 集群中未充分利用的 CPU、DRAM 和 SSD 资源,实现 KVCache 的解耦缓存。
面对不断增长的需求,业内正在探索实现更大甚至无限上下文的技术路径。
比如,PPIO 率先完成 DeepSeek V3/R1 的推理服务能力升级,将上下文窗口长度拓展至 160k,最大输出 tokens 拓展至 160k。可满足多轮超长对话、Agent 深度分析、Coding 生成等场景长输出应用需求。
谷歌提出的 Infini-Attention 通过在注意力机制中引入压缩记忆(compressive memory),同时结合局部和长程线性注意,使模型能够以有限的内存和计算处理理论上“无限长的输入”。
总之,上下文的探索还远未看到尽头,128k 是一个重要的里程碑,但绝非终点。未来,竞争的焦点将从单纯的“窗口长度”转向“信息利用效率”,最终目标是让 AI 模型能够像人类一样,在面对海量信息时,能够高效、准确地理解、推理和生成,真正实现通用人工智能的愿景。



