视觉模态革新:Qwen2.5-VL-72B-Instruct和Gemma3-27B亮相PPIO!

Qwen2.5-VL-72B-Instruct 以更精确的视觉解析特性横扫 OCR、长视频理解、工业图表解析;Gemma3-27B 则主打高算力性价比,用极简算力撬动顶尖视觉 LLM。
从影像的精微解析到海量文档的秒级结构化,PPIO派欧云上新的「视觉+语言」超能LLM组合将突破传统 AI 应用效能边界。
模型简介
1. Qwen/Qwen2.5-VL-72B-Instruct
Qwen2.5-VL 是 Qwen2.5 系列中的视觉语言模型。从最新的实测数据测评来看,Qwen2.5-VL 在文档解析、视觉问答、视频理解及智能体测试四大场景均展现全方位领先优势,其中 OCR 精度超越主流方案 30% 以上,AITZ智能体任务以绝对优势领跑行业。
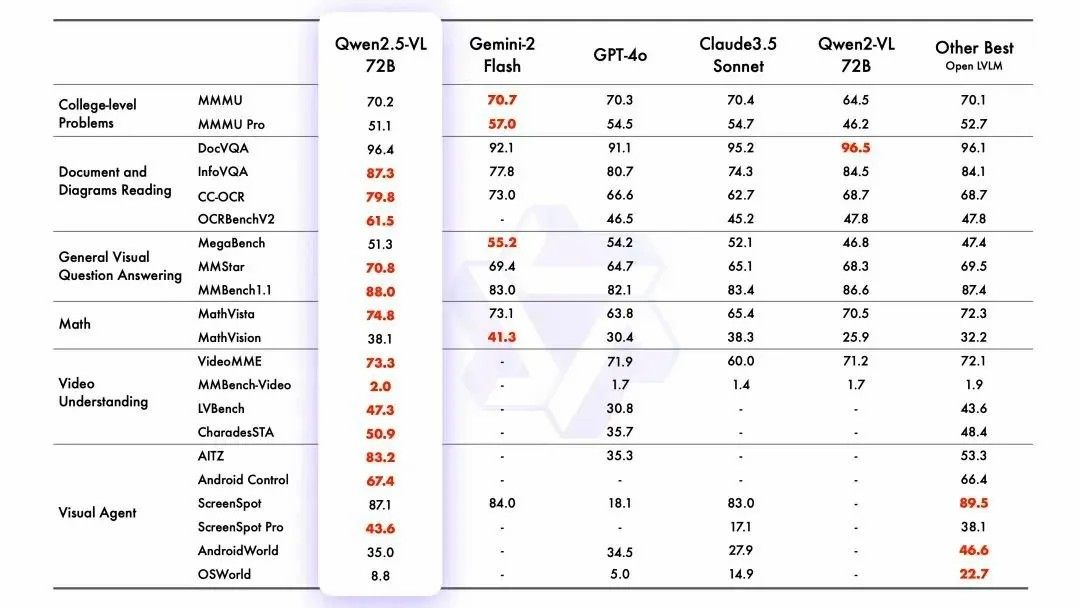
即在具体应用中,模型能识别常见物体、分析文本图表与布局。可推理并动态指导工具使用,支持理解超 1 小时长视频并捕捉关键事件,通过生成边界框或点定位图像物体,并且支持发票、表格等扫描数据的结构化输出。
2. Gemma3- 27B
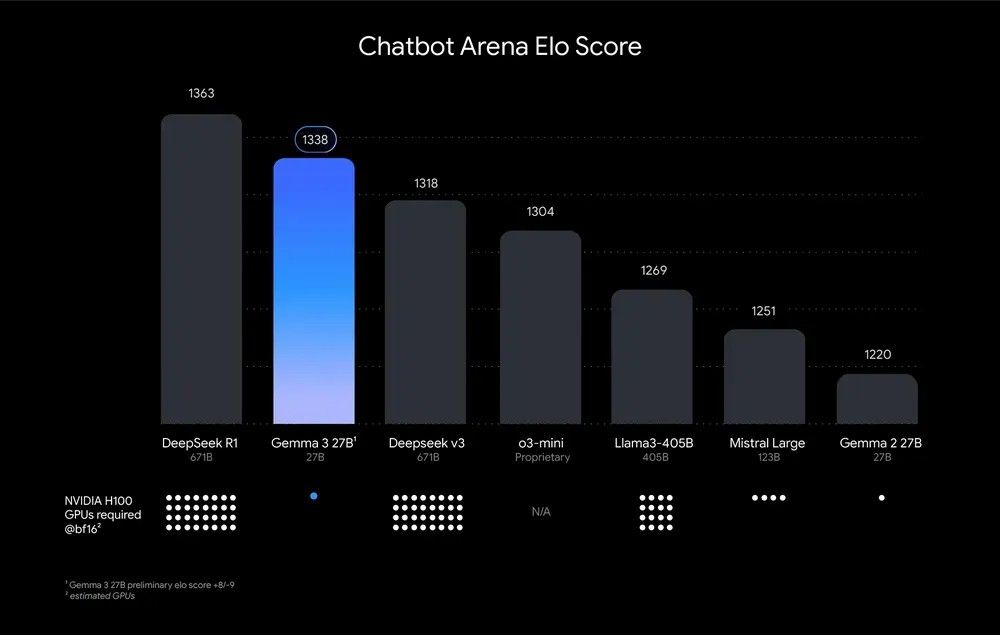
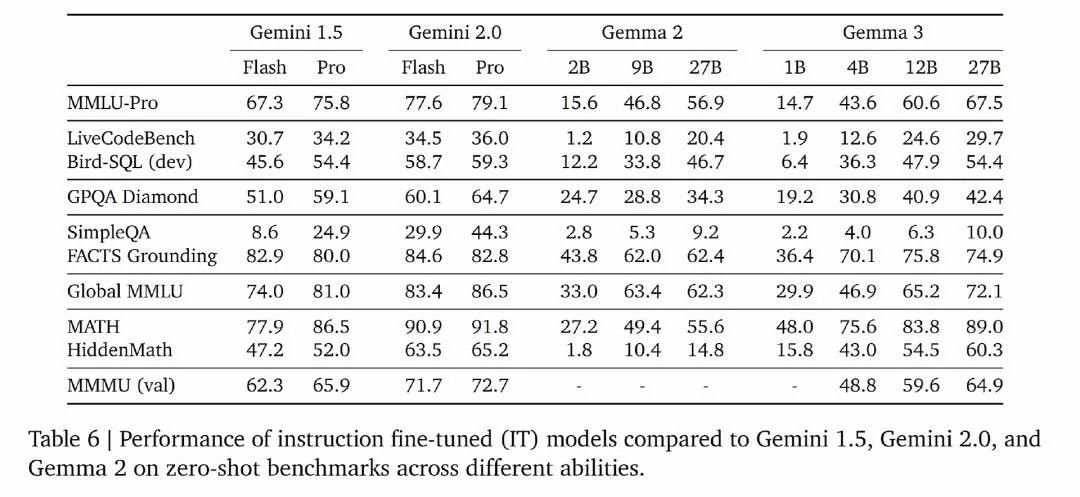
从图中 Chatbot Arena Elo 评分来看,Gemma 3 27B 以 1338 的高分位居前列,仅次于 DeepSeek R1 671B,相较于其他知名模型也优势明显。从 Gemma 自身系列的比较来看,性能上也在不断迭代中提升,且极小的算力需求量使其在众多强劲对手中脱颖而出。
模型价格
PPIO派欧云作为国内最早上线 DeepSeek 全模型的 API 供应商之一,为 AI 开发者和企业提供低成本、稳定可靠、接入简单的大模型 API 和 GPU 算力服务。
此次上新 Gemma 3 27B、Qwen/Qwen2.5-VL-72B-Instruct 模型,为广大用户提供更高效、更智能的 AI 解决方案。模型具体价格如下:

👉在线体验:
- Qwen/Qwen2.5-VL-72B-Instruct:https://ppinfra.com/llm/qwen-qwen2.5-vl-72b-instruct
- Gemma3-27B:https://ppinfra.com/llm/google-gemma-3-27b-it
👉API 文档:https://ppinfra.com/docs/model-api/reference/llm/
TIPS
若您还在寻觅更多优质模型,不妨关注我们刚上架的 DeepSeek V3 0324 模型,我们在下调了价格的同时还实现了更高的上下文窗口!
🚩 价格优化调整:每 1M tokens 输入 ¥8 / 输出 ¥8 → 输入 ¥2 / 输出 ¥8(与 DeepSeek 官方价格一致)。
🚩 上下文窗口升级拓展: 64k →128k
👉 一键在线体验:https://ppinfra.com/llm/deepseek-deepseek-v3-0324
模型应用
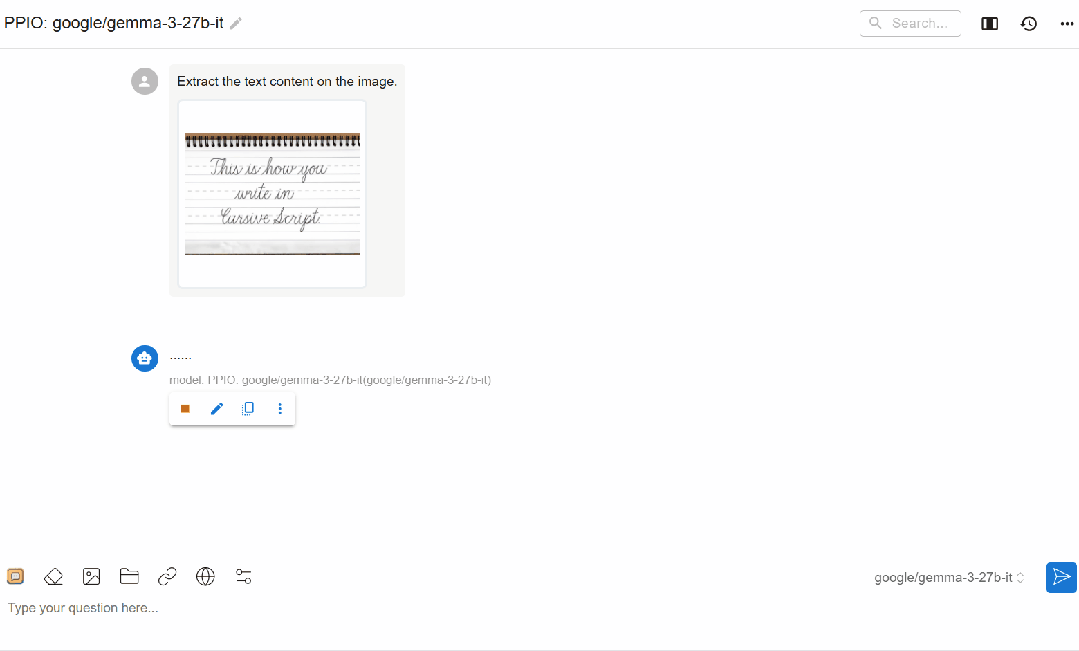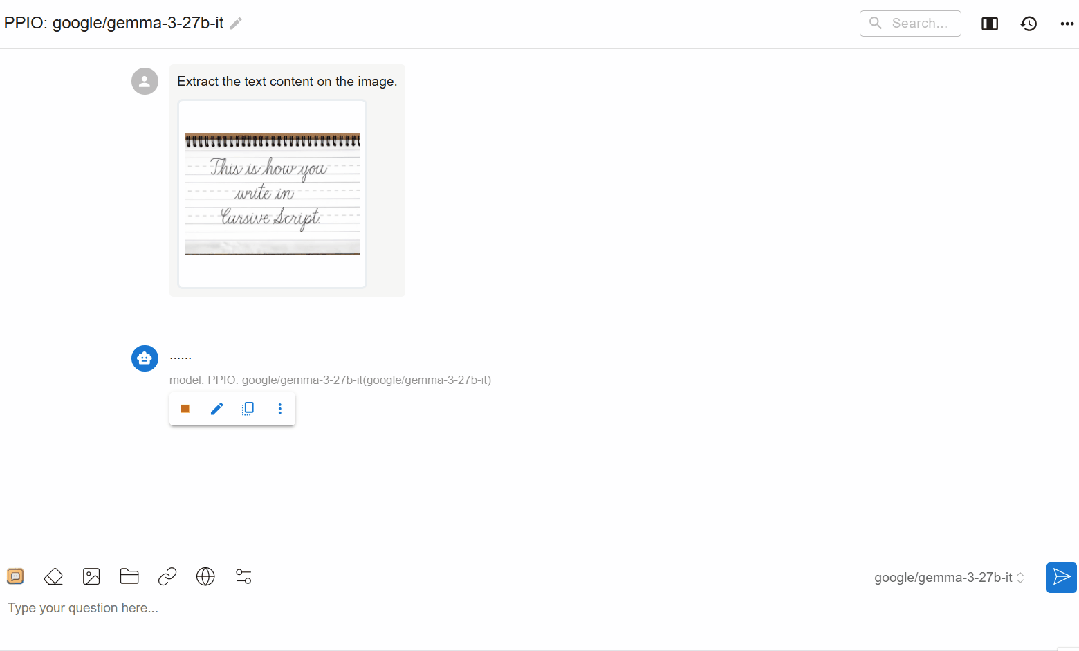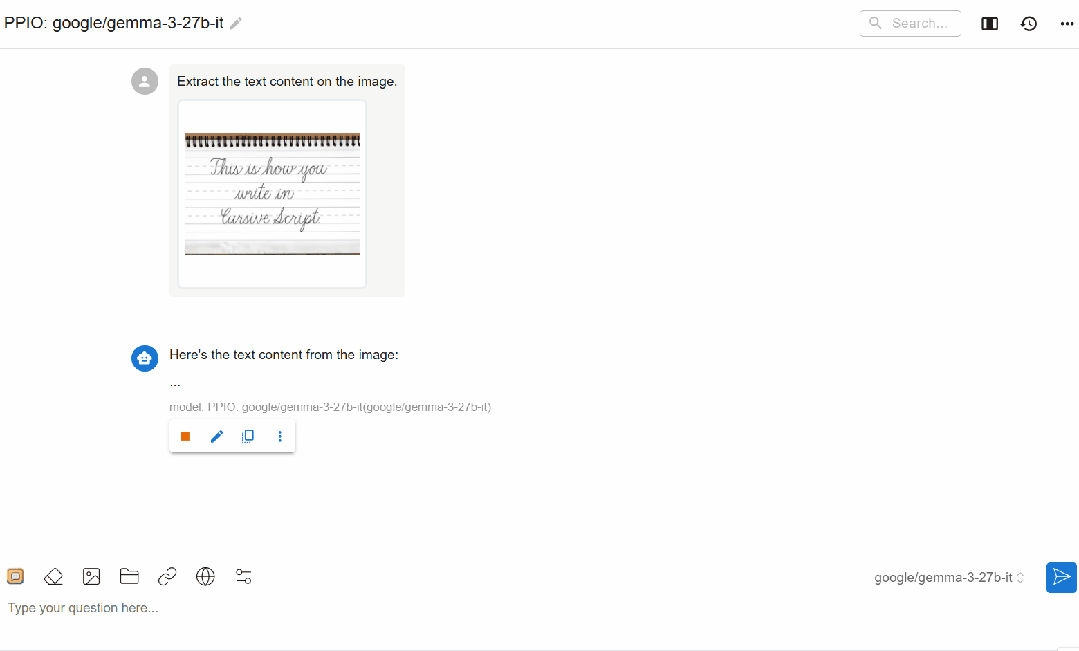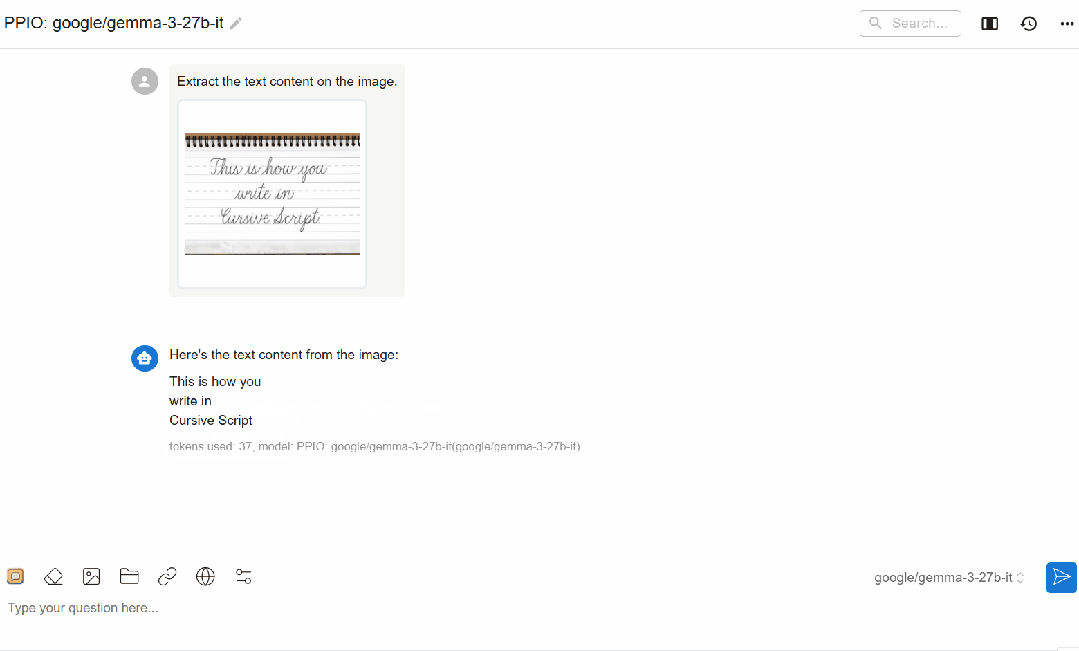
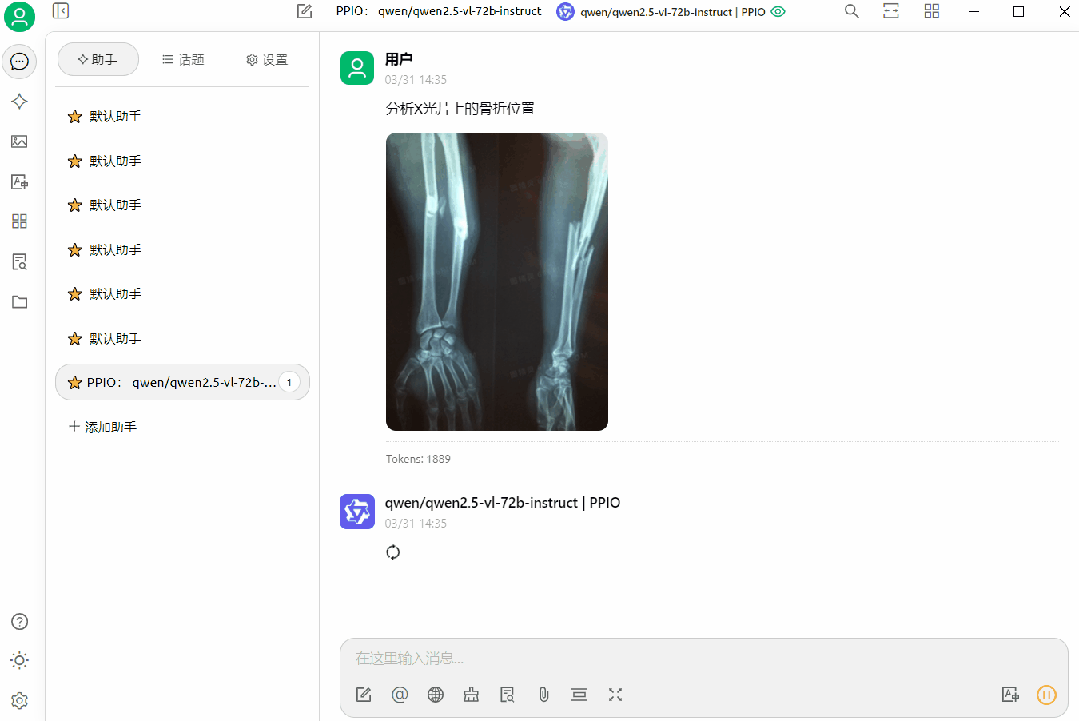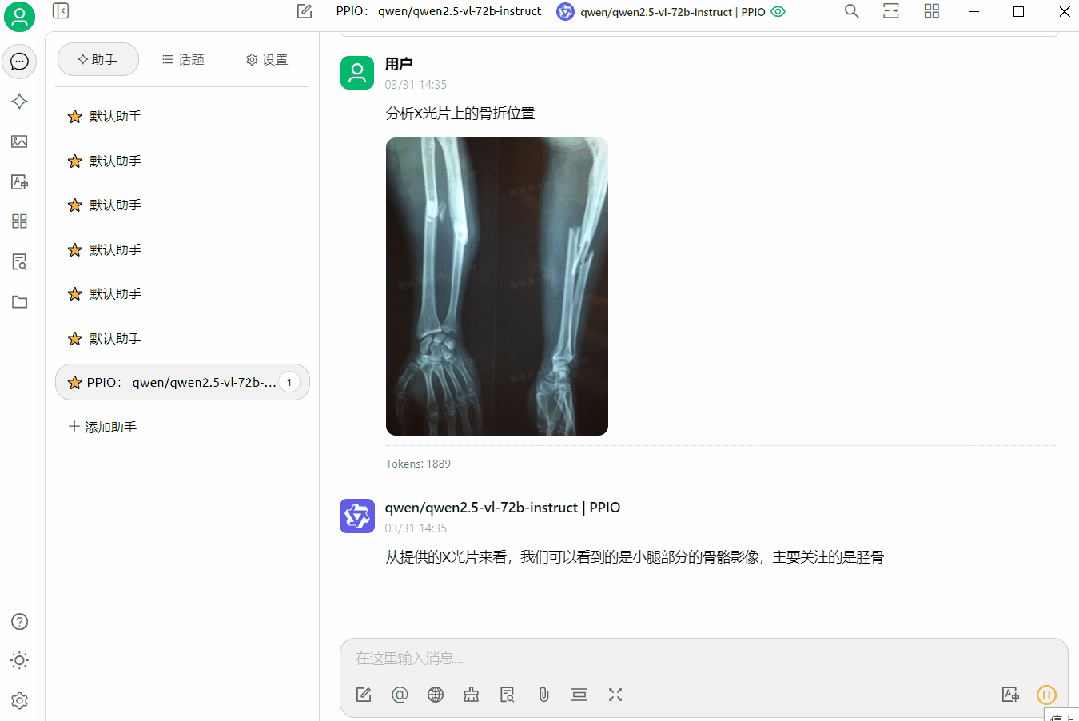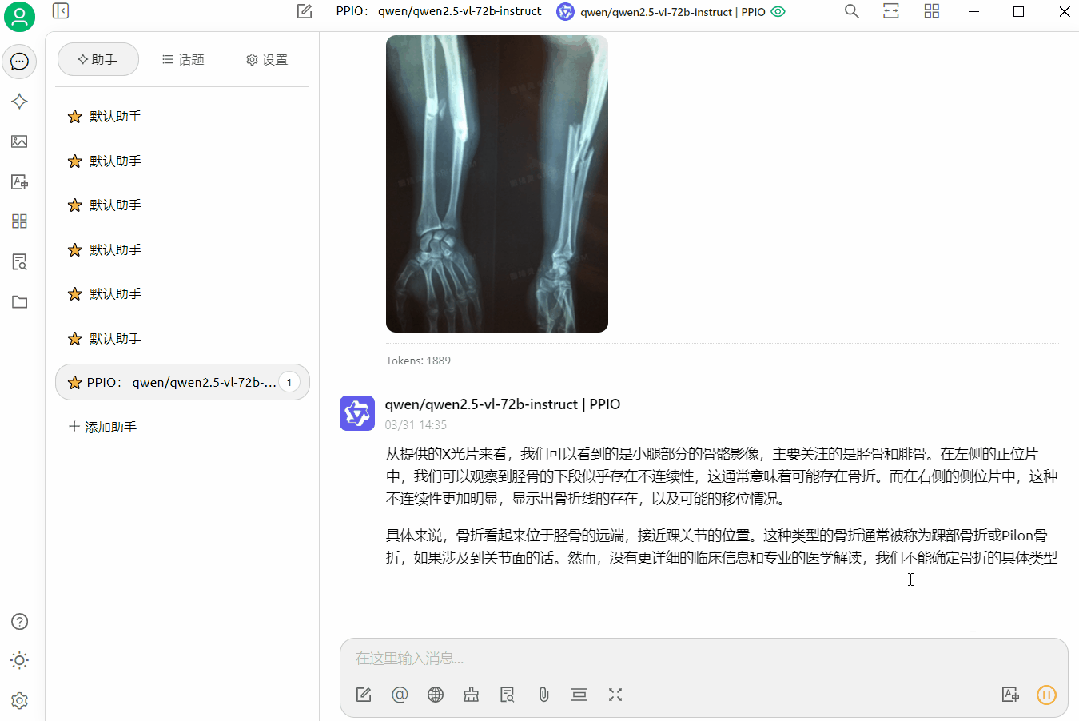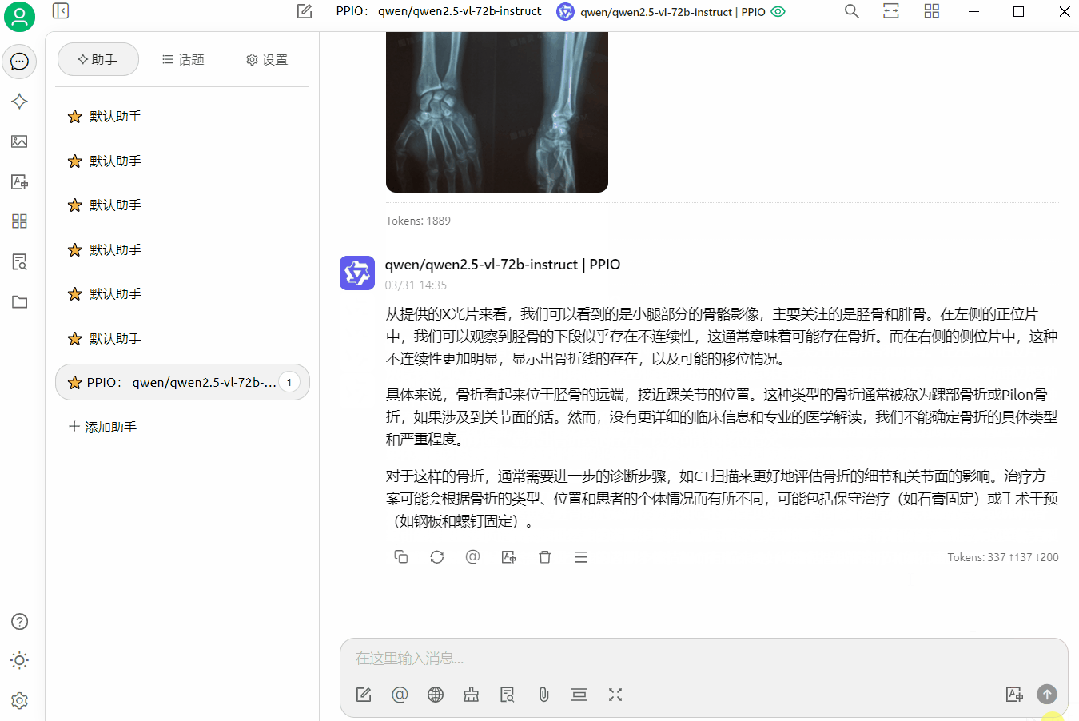
(1)Qwen/Qwen2.5-VL-72B-Instruct 应用


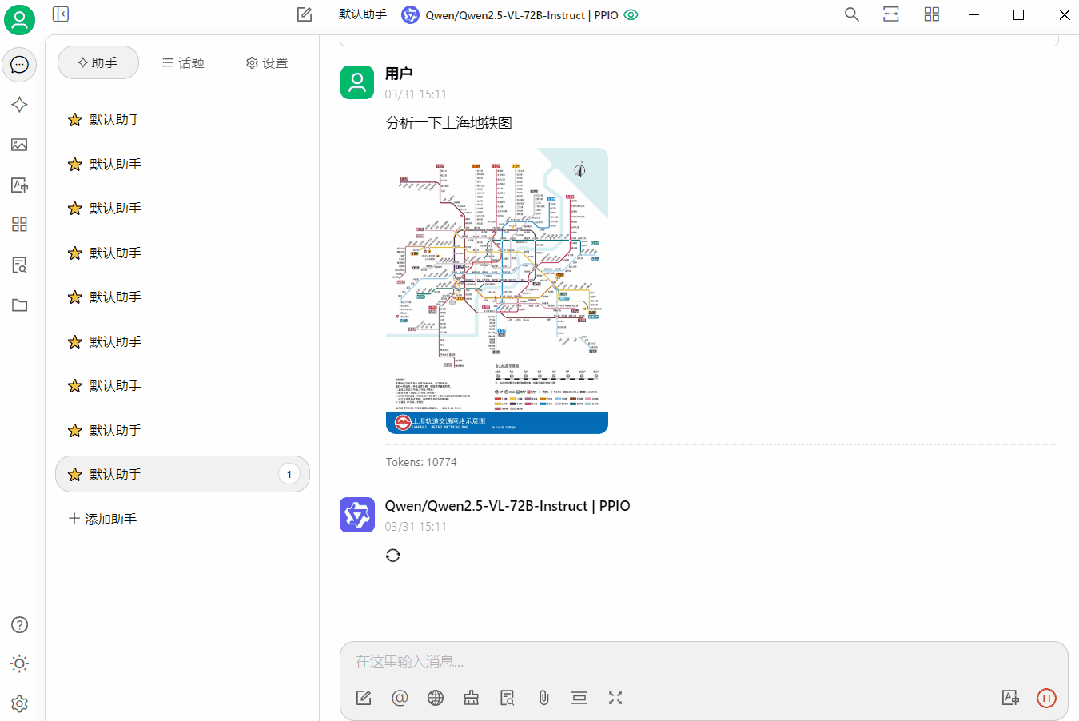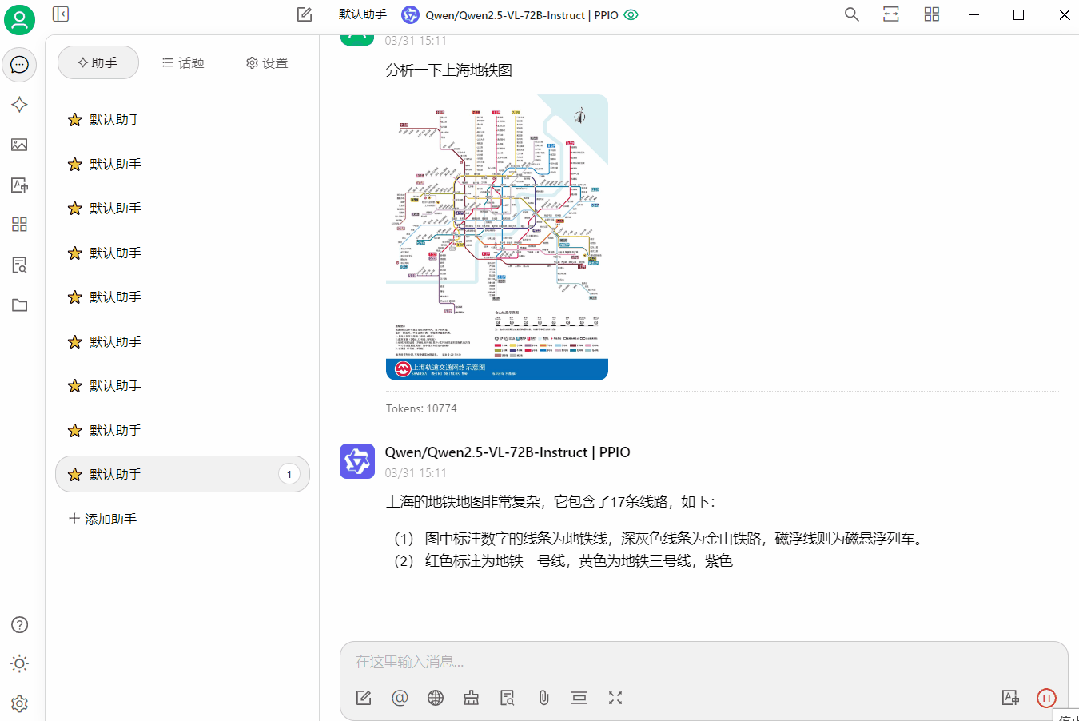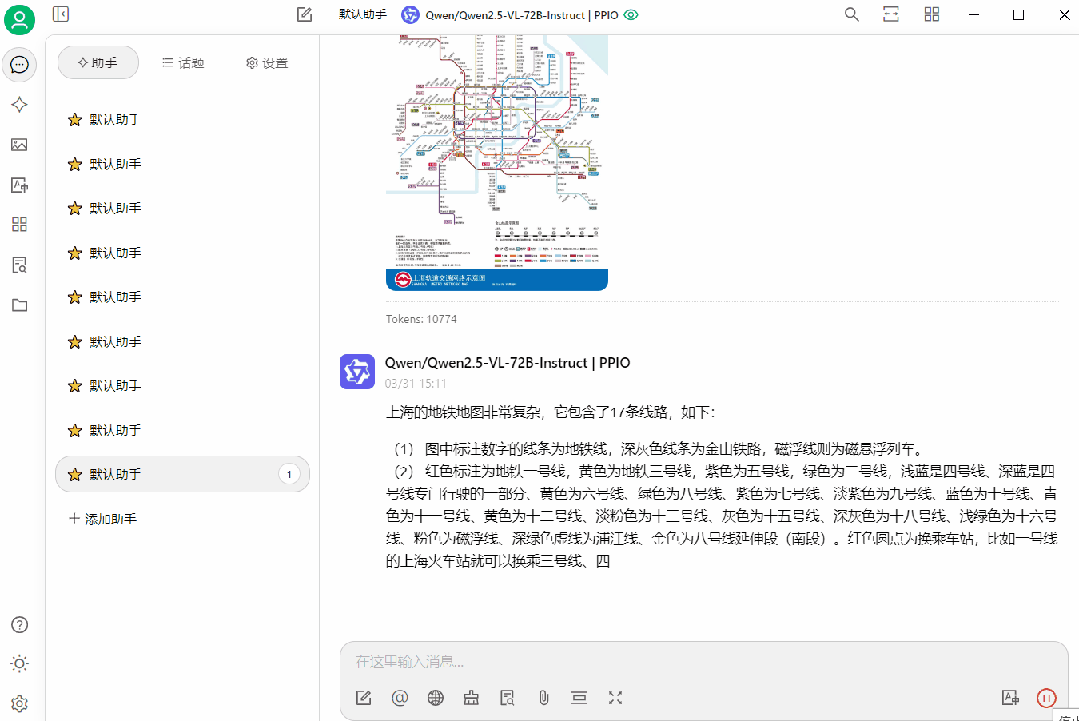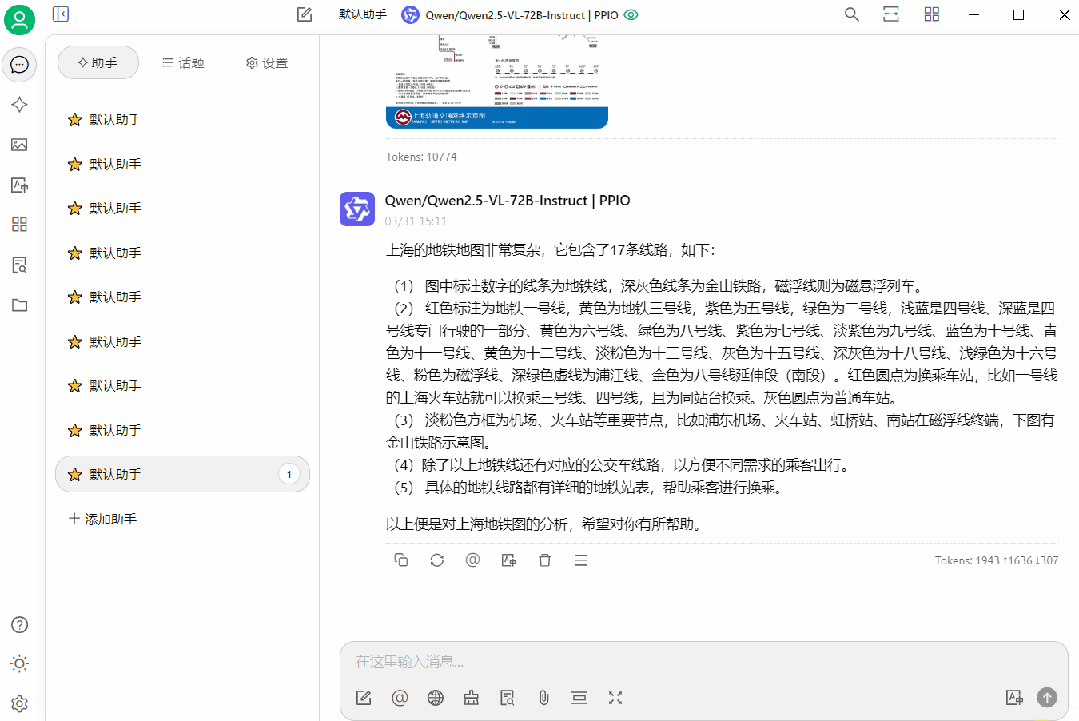
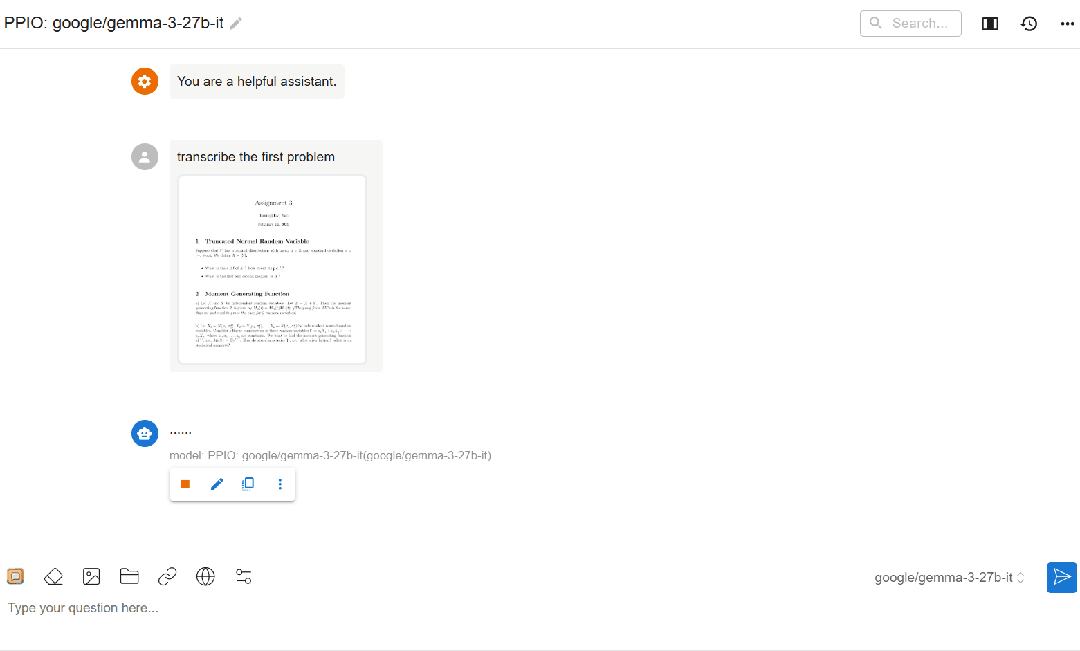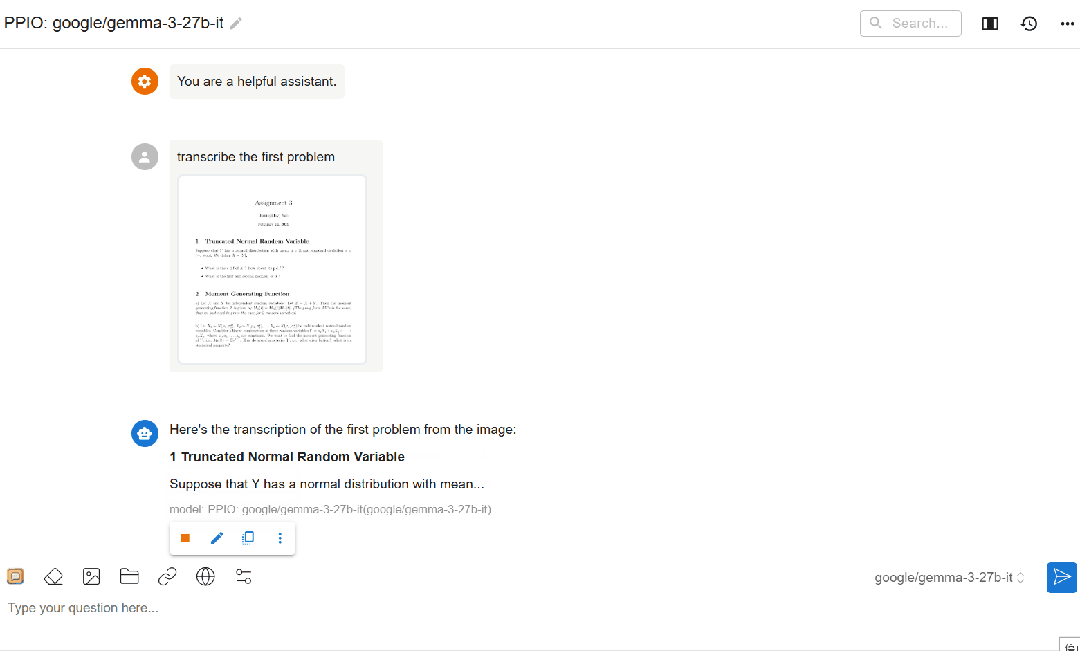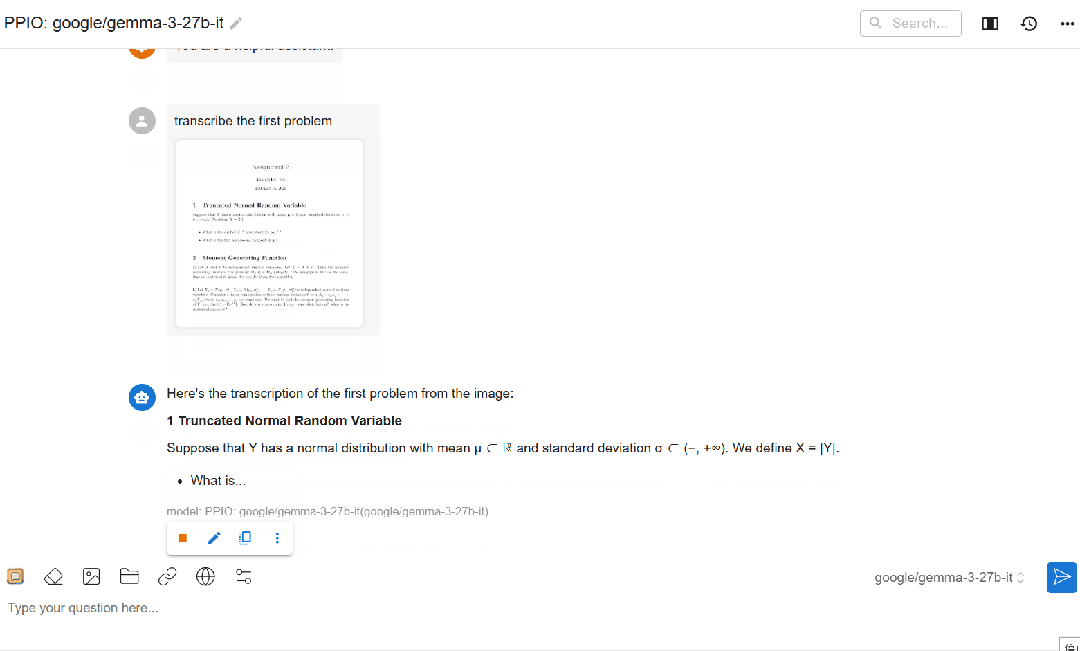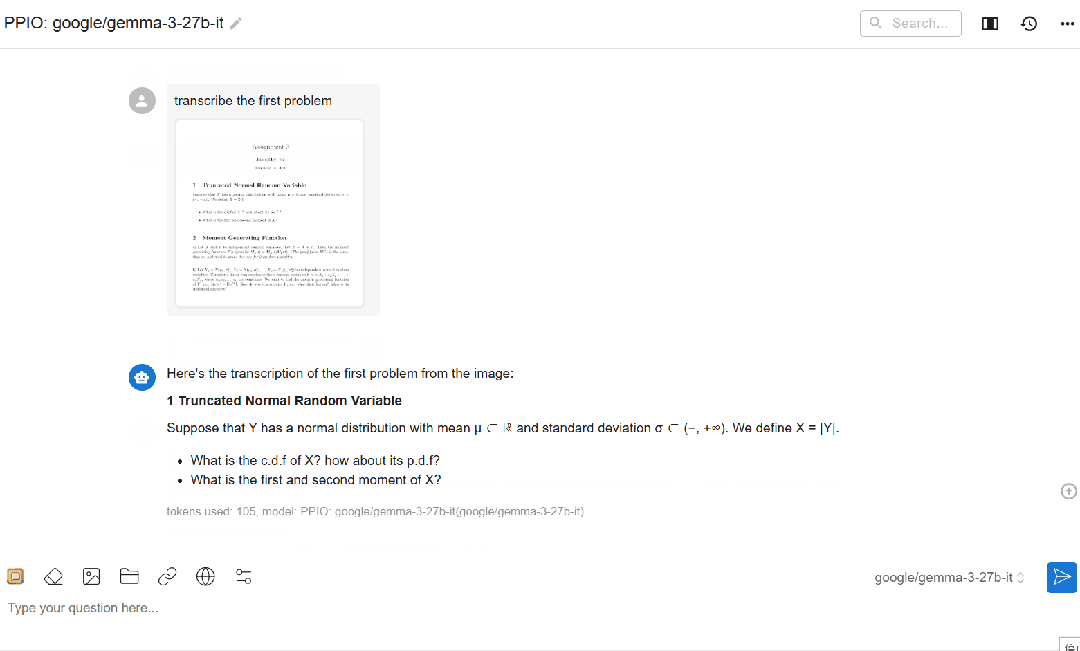
(2)gemma3-27B 应用