
DeepSeek-V3.2-Exp发布,有哪些新变化?

今天,DeepSeek 突然发布新版本模型 DeepSeek-V3.2-Exp,PPIO 已经首发上线!
DeepSeek-V3.2-Exp 是 DeepSeek 新模型的实验版本,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 “DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention)”,旨在探索和验证在长上下文场景下训练和推理效率的优化。
该实验版本代表了 DeepSeek 对更高效的 Transformer 架构的持续研究,特别注重提高处理扩展文本序列时的计算效率。
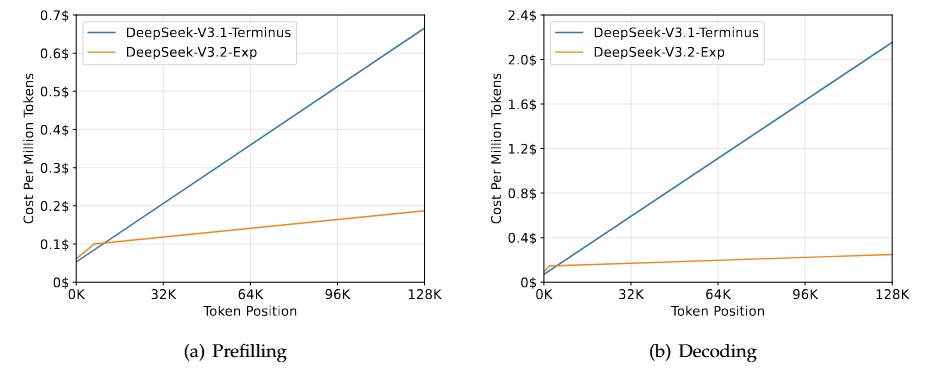
- DeepSeek 稀疏注意力首次实现了细粒度稀疏注意力,在保持几乎相同的模型输出质量的同时,显著提高了长上下文训练和推理效率。DeepSeek-V3.2-Exp 支持 160K 上下文。
- 为了严格评估引入稀疏注意力机制的影响,DeepSeek 特意将 DeepSeek-V3.2-Exp 的训练配置与 V3.1-Terminus 进行了对齐。在各个领域的公开基准测试中,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 相当。
- 基于新架构,DeepSeek-V3.2-Exp 也能在训练推理提效的同时实现 API 价格的大幅下降。PPIO 平台的定价为:每百万输入 tokens 2元,每百万输出 tokens 3元。
现在,你可以到 PPIO 官网(或点击文末阅读原文)在线体验 DeepSeek-V3.2-Exp ,或将模型 API 接入 Cherry Studio、ChatBox 或者你自己的 AI 工作流中。新用户填写邀请码【24CGOJ】注册可得 15 元代金券。
在线体验入口:
https://ppio.com/llm/deepseek-deepseek-v3.2-exp
开发者文档:
https://ppio.com/docs/model/overview
DeepSeek-V3.2 技术报告也已经发布,标题为《 DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention》。感兴趣的开发者、用户可扫下方二维码下载,并加入开发者社群。




