
PPIO 上线 GLM-4.7-Flash 模板 | 极速部署教程

今天,PPIO 上线智谱最新款轻量级大语言模型 GLM-4.7-Flash。
GLM-4.7-Flash 作为 GLM-4.7 旗舰系列的“极速版”,总参数量为30B,激活参数量为3B,为用户提供了一个兼顾性能与效率的新选择。
该模型面向 Agentic Coding 场景强化了编码能力、长程任务规划与工具协同,并在多个公开基准的当期榜单中取得同尺寸开源模型中的领先表现。在执行复杂智能体任务,GLM-4.7-Flash 在工具调用时指令遵循更强,并大幅提升了 Artifacts 与 Agentic Coding 的前端美感和长程任务完成效率。
现在,你可以通过 PPIO 算力市场的 GLM-4.7-Flash 部署模板,简单几步部署该模型。
项目地址:https://ppio.com/gpu-instance/
#01 GPU 实例+模板,一键部署 GLM-4.7-Flash
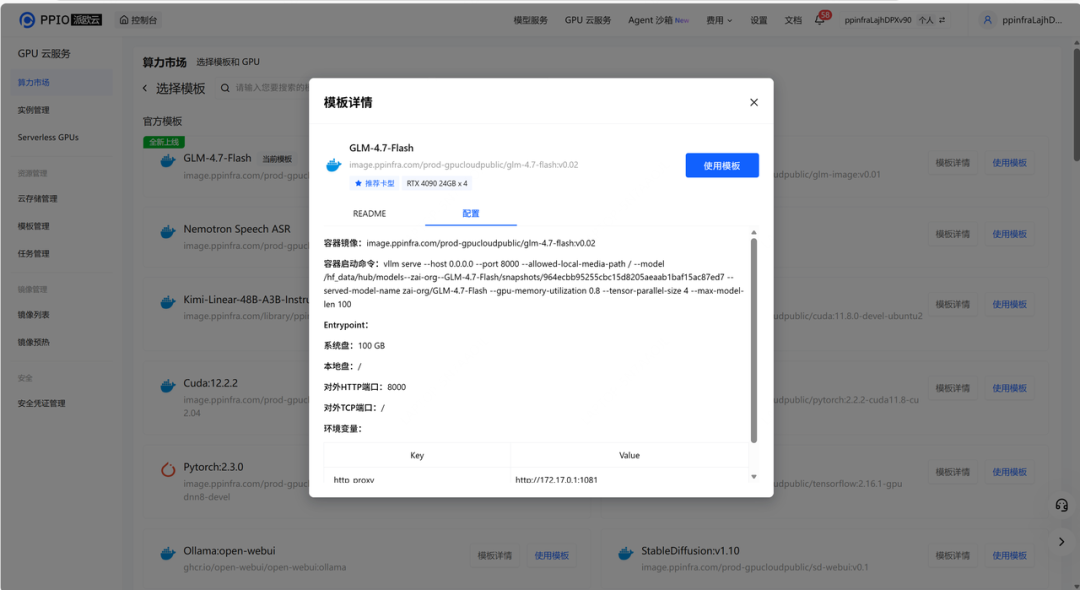
step 1: 子模版市场选择对应模板,并使用此模板。
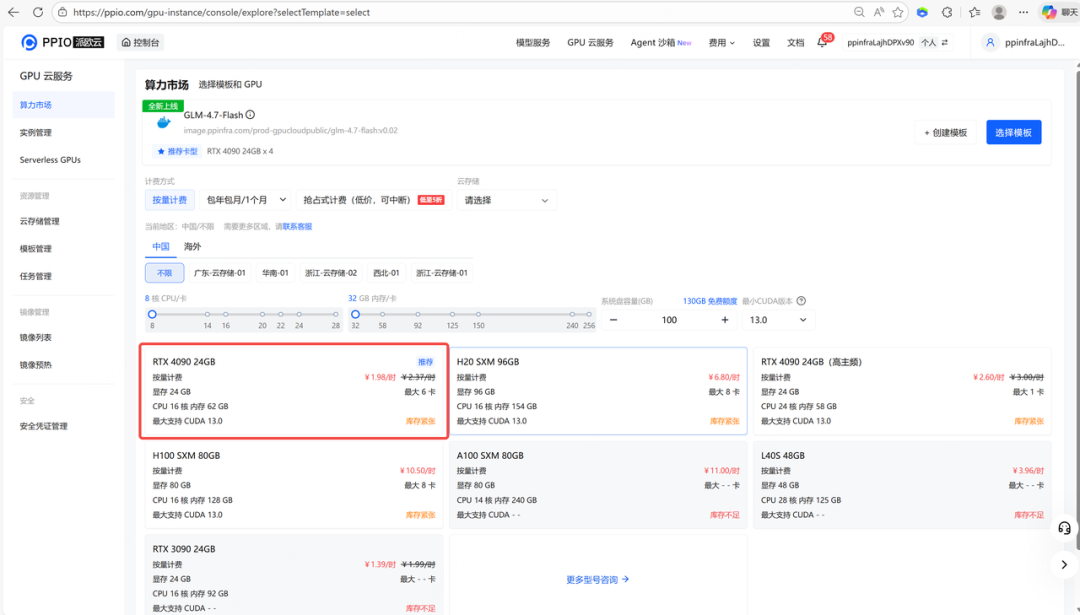
step 2: 按照所需配置点击部署。
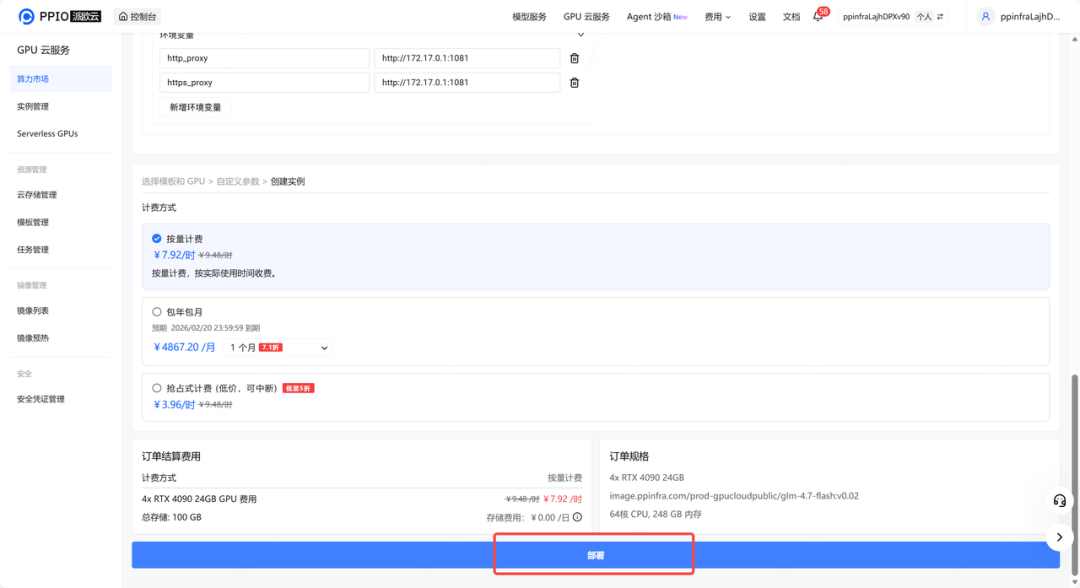
step 3: 检查磁盘大小等信息,确认无误后点击部署。
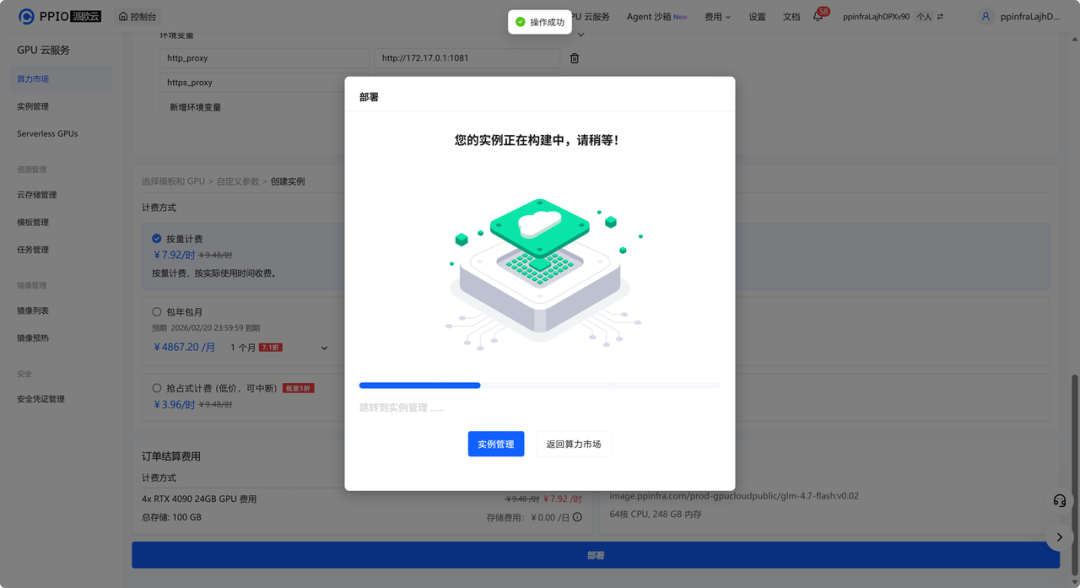
step 4: 稍等一会,实例创建需要一些时间。
step 5: 在实例管理里即可查看到所创建的实例。
#02 如何使用
示例
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\n2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}PPIO 的算力市场模板致力于帮助企业及个人开发者降低大模型私有化部署的门槛,无需繁琐的环境配置,即可实现高效、安全的模型落地。
目前,PPIO算力市场已上线几十个私有化部署模板,除了 GLM-4.7-Flash,你也可以将 GLM-Image、AutoGLM-Phone-9B、Nemotron Speech ASR、PaddleOCR-VL 等模型快速进行私有化部署。



