
PPIO姚欣出席首届AI国际人才峰会:AI落地需先找对“钉子”再选好“锤子”


8 月 26 日,由香港投资管理有限公司(下称 “港投公司”)与北京智源人工智能研究院(下称 “智源研究院”)联合主办的首届 “AI 国际人才峰会” 在香港成功举办。香港特别行政区政府财政司司长陈茂波、港投公司行政总裁陈家齐、智源研究院理事长黄铁军等出席并致辞。
峰会还汇聚了加拿大皇家科学院院士张大鹏教授、美国国家工程院院士 David Srolovitz 教授、英国皇家工程院院士 Sethu Vijayakumar 教授等全球人工智能领域顶尖专家、海内外青年学者,以及不同产业的 AI 初创企业,共同围绕 AI 前沿技术发展、产业实践以及生态建设展开交流互动。PPIO 联合创始人兼 CEO 姚欣受邀出席峰会并发表题为《从 PPTV 到 PPIO:赋能全球 AI 创业者》的演讲,从自身创业经历出发,同与会者分享 AI 时代创业者所需的特质。

# 01
AI 时代的创业人才
需具备 “PDA” 思维
活动现场,作为 21 年的连续创业者,姚欣分享了他的创业经历:2004 年,24 岁的姚欣研究生辍学创业,开发出全球首款网络电视软件 PPTV,积累 4.5 亿用户;2016 年,转型投资人,支持近百家科技企业成长;2018 年,开始二次创业,创办了分布式云计算企业 PPIO。
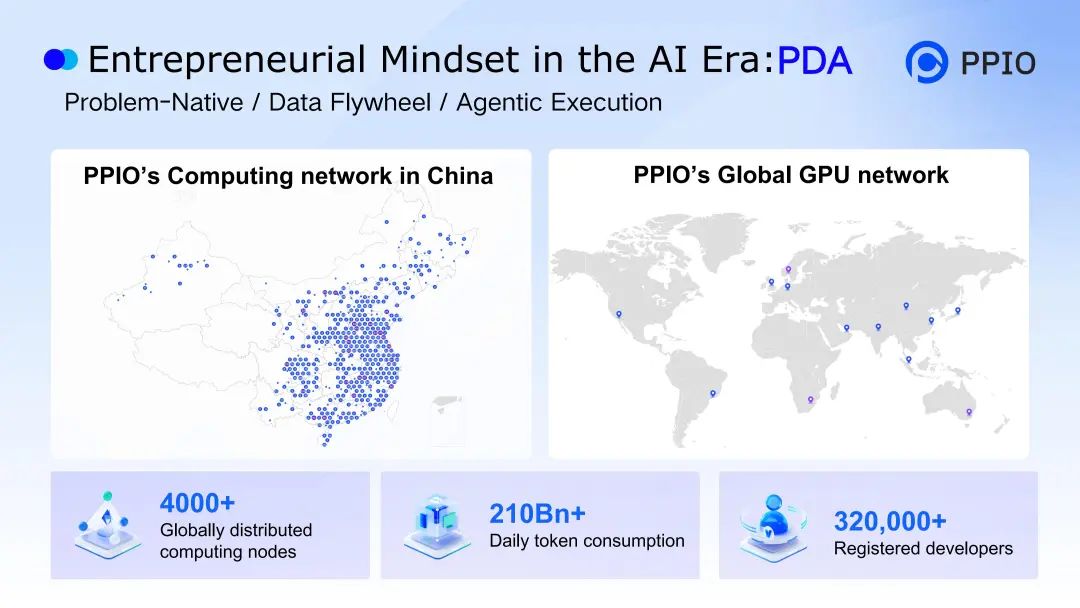
当前,PPIO 在全球六大洲拥有 4000+ 算力节点,平台注册开发者数超 32 万,日均 Tokens 消耗量超 2100 亿。
“二十年创业与投资生涯,让我深度参与了从互联网浪潮到 AI 1.0、再到 AI 2.0 的科技迭代。” 姚欣称,“这段跨时代的实践经历,也让我察觉到,当下 AI 领域对人才特质的需求,已与过往互联网及早期 AI 时代呈现显著差异。”
基于对 PPIO 所服务的大量 AI 创业者、开发者的深度洞察,结合自身创业经历,姚欣认为 AI 时代的创业人才需要具备“PDA”思维,即 Problem-Native(问题原生)、Data Flywheel(数据飞轮)与 Agentic Execution(智能体执行)。
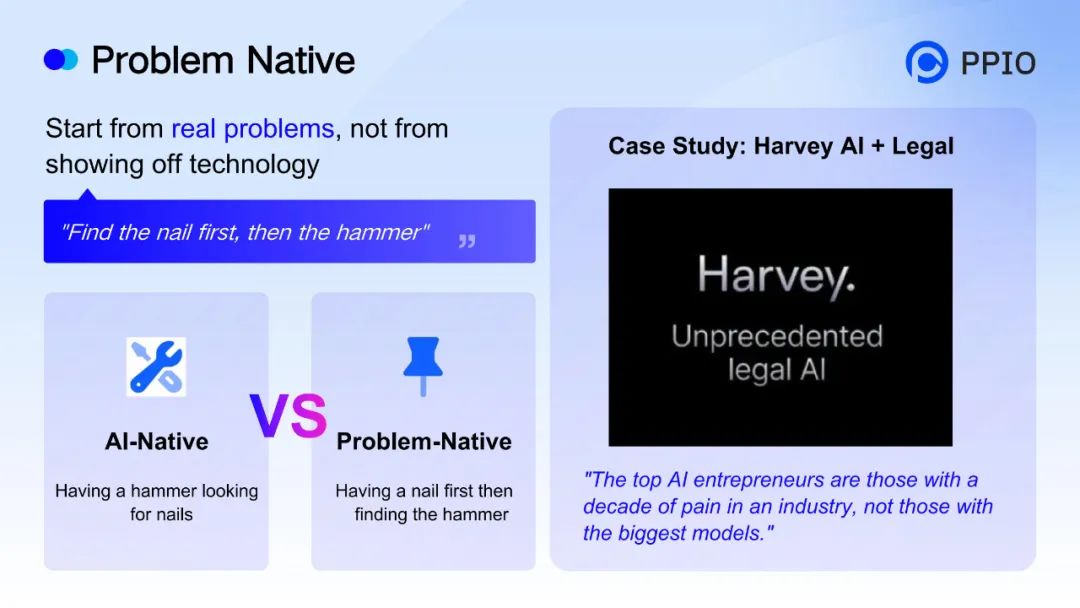
“真正成功的 AI 创业者是真正发现了行业痛点的人,而非拥有最大、最全模型的人。” 姚欣强调,AI 人才、创业者需首先遵循 “问题原生” 原则,从行业痛点出发,“先找准钉子,再选择锤子”。
他以海外客户 Harvey AI 为例,这家由 Google Brain 技术专家与资深律师联合创立的法律垂类 AI 公司,正是凭借对行业严谨性、专业性的深刻洞察,成功让 AI 在法律文本处理方面真正释放价值。
面对“真问题”,AI 创业人才还需构筑自己的护城河,构建真正的核心竞争力。在姚欣看来,实现这一目标离不开 “数据飞轮” 的支撑。
他提出,当前 AI 领域的模型差距正不断缩小,高质量垂直行业数据的积累反而成为决胜关键,“0.1% 的模型改进远不及 100% 的专有数据有价值”。他将这种数据壁垒形象化为 “飞轮模型”:通过数据收集、模型训练、用户反馈到产品优化的持续循环,让数据在迭代中不断增值,进而强化竞争优势。
姚欣还特别强调了香港在数据资源方面的独特优势—— 高价值金融交易数据、全球贸易跨境数据流动能力及国际化合规的数据处理环境,这些都能为当地 AI 人才搭建 “数据飞轮” 提供天然沃土,助力其快速构建行业壁垒。
在痛点明确、数据壁垒成型后,AI 人才创业成功还需要高效的落地执行能力,这正是 “Agentic Execution(智能体执行)” 的核心价值所在。
“2025 年最火的话题不是大模型,而是智能体(Agent)技术的爆发。” 在姚欣看来,AI 正从过去的辅助分析角色,进化为能够自主执行任务的 “数字员工”—— 不再只是提供建议,更能直接参与任务处理,比如自动完成流程化工作、高效处理重复性事务。
这种从 “辅助” 到 “执行” 的转变,能帮助创业者将前期的痛点解决方案与数据优势转化为实际成果,大幅提升落地效率,加速 AI 创业者从 “想法” 走向 “价值” 。
# 02
打造智能体基石
PPIO 赋能全球 AI 创业者
在 AI 智能体从 “理论突破” 迈向 “场景落地” 的关键阶段,作为中国领先的独立分布式云计算服务商,PPIO 正以扎实的技术产品布局,将前文提及的 “智能体执行” 理念转化为可落地的服务能力,为全球 AI 创业者提供底层支撑。
姚欣在演讲中重点介绍了 PPIO 的核心产品突破 —— 今年 7 月发布的国内首个 Agentic AI 基础设施平台。该平台提供“兼容 E2B 接口的 Agent沙箱 + 模型 API+GPU 云服务” 的核心产品,从根本上解决了 AI 智能体 “能思考,难执行” 的行业痛点。
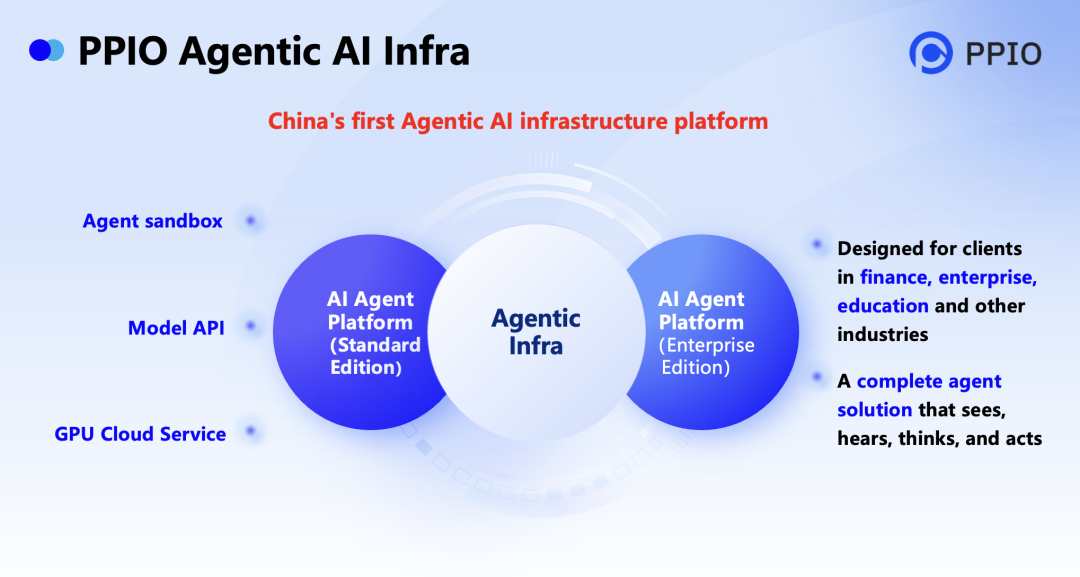
其中,沙箱作为核心组件产品,具备三大关键特性:毫秒级启动速度满足实时任务响应需求,虚拟机隔离保障代码执行过程中的数据安全,按需弹性调度大幅降低算力成本。平台还可同时支持数千实例高并发创建,完美平衡 AI 代码执行的效率与安全。
“我们不仅让大语言模型能思考推理,更给它装上‘手脚’,让 AI 能安全执行代码、自动完成任务,为开发者提供从‘想法’ 到‘落地’的全流程技术支持。” 姚欣表示。
而在将这一核心技术能力向全球范围延伸、进一步放大技术赋能价值的过程中,PPIO 也找到了国际化布局的关键支点 —— 依托港投公司的战略投资支持,将香港定位为国际出海总部,深度融入香港 AI 人才生态圈建设。
数据显示,今年 2 月至 7 月,香港开发者在 PPIO 旗下平台的月度 Tokens 消耗量增长近 10 倍,高校开发者群体快速壮大,成为 AI 创新、创意执行主力。PPIO 正着力通过超高性价比 Token 服务、全栈技术支持和开发者友好的工具链,降低 AI 创新门槛。
在演讲最后,姚欣特别寄语 AI 人才、年轻创业者:“ PPIO 会通过全球分布式计算网络和 Agentic AI 基础设施平台,为与‘24岁的姚欣’有同样创业梦想和热情的创业者提供支持,助力他们获得成功。”
他鼓励青年开发者把握 AI 大航海时代的机遇,借助香港的国际化平台与 PPIO 的技术基础设施,将创新想法转化为实际价值,共同推动 AI 技术在各行业深度落地。



