PPIO派欧云发布下一代推理加速引擎

(2024年7月28日,长春)2024年7月26至28日,由中国计算机学会(CCF)主办的“CCF Computility 2024分布式计算大会暨全国开放式分布与并行计算学术年会”在长春市举办。陈国良院士、于全院士、郑纬民院士等11位院士与学术界和产业界的1000多位顶级专家齐聚一堂,深入探讨分布式计算与算力网的最新进展,推动科技与产业的深度融合。

作为中国领先的分布式云服务商,PPIO派欧云联合创始人、董事长兼CEO姚欣受邀参会并发表题为《面向下一代人工智能的分布式智算网络建设与运营》的主题演讲,正式发布下一代分布式推理加速技术产品——派欧算力云推理加速引擎。

性价比领先,推理性能提升十倍,综合成本降低90%
派欧算力云推理加速引擎通过一系列自研推理加速算法,使大语言模型(LLM)推理性能提升10倍。同时,PPIO派欧云还积极在硬件层构建分布式算力基础设施,将综合推理成本降低90%以上。不仅推理性能超越了众多硅谷AI Infra头部公司,还具备显著的成本优势,助力更多开发者使用大模型技术进行应用创新。

为了突破显存、算力和带宽对大模型推理性能的限制,PPIO派欧云通过算法、系统和硬件的协同创新实践,推出三大核心技术,通过Pyramid Cache稀疏化压缩算法、Hydra Sampling投机采样技术以及端到端FP8推理,打造全球领先的下一代高性价比算力云推理加速引擎。这些技术显著提升了推理加速优化的潜能,实现成本与性能之间的最佳平衡,为开发者提供了卓越性价比的大模型推理服务。
Pyramid Cache稀疏化压缩算法
与当前主流压缩优化思路不同,Pyramid Cache稀疏化压缩算法分析计算注意力分数在不同层上的分布模式,为不同层动态分配不同KV Cache预算,在压缩比和模型性能之间取得最佳匹配。实验表明,该方法将KV Cache压缩至10%以内,同时保持95%以上的模型性能表现,最终将GPU内存开销降低至20%,显著提高GPU内存资源利用率,不仅满足长窗口的推理需求,还进一步将端到端推理效率提升2倍以上。
Hydra Sampling投机采样技术
针对传统大模型推理过程中每次仅生成一个token导致的低吞吐量问题,PPIO派欧云创新实现了基于多头并行推理的Hydra Sampling投机采样技术。大量实验证实,在传统的投机采样算法中,草稿模型的输出token接受率严重影响推理效率。为此,PPIO通过用场景数据在线更新草稿模型,使得草稿模型逐渐拟合目标大模型,相应的输出token接受率可以进一步提高。基于这种在线动态更新机制,草稿模型越用越聪明,推理效率也随之越来越高,端到端综合性能优化达到2倍以上,处理更多请求的同时,推理性价比显著提升。
端到端FP8推理
PPIO派欧云重写了核心的注意力算法,直接调用FP8 TensorCore进行注意力计算,并使用FP8保存KV Cache,避免FP16格式的中间结果转换和传输,实现全链路FP8计算。通过这些优化,显著降低数据存储和通信成本,端到端推理效率提升约2倍,充分释放硬件算力潜能。
在三项创新技术的支持下,派欧算力云产品基于自研的推理加速引擎能够迅速适配和优化开源大模型,第一时间上架Llama3.1-405B、Mixtral 8x22B等20多个开源高性能大模型,API正常运行时间达到99.99% 。与GPT-4o相比,通过派欧算力云产品微调和优化的Llama3.1-70b模型,其Input token价格降低了90%,Output token价格降低了95%。派欧算力云产品还通过第三方大模型API平台为全球开发者提供高性能推理服务,相比于OctoAI、Together、Fireworks等硅谷公司,派欧算力云产品在综合性价比上具有显著优势,确保开发者在享受高性能、稳定的推理服务的同时,获得前所未有的成本效益。
灵活产品形态,共建繁荣AI开发者和产学研生态
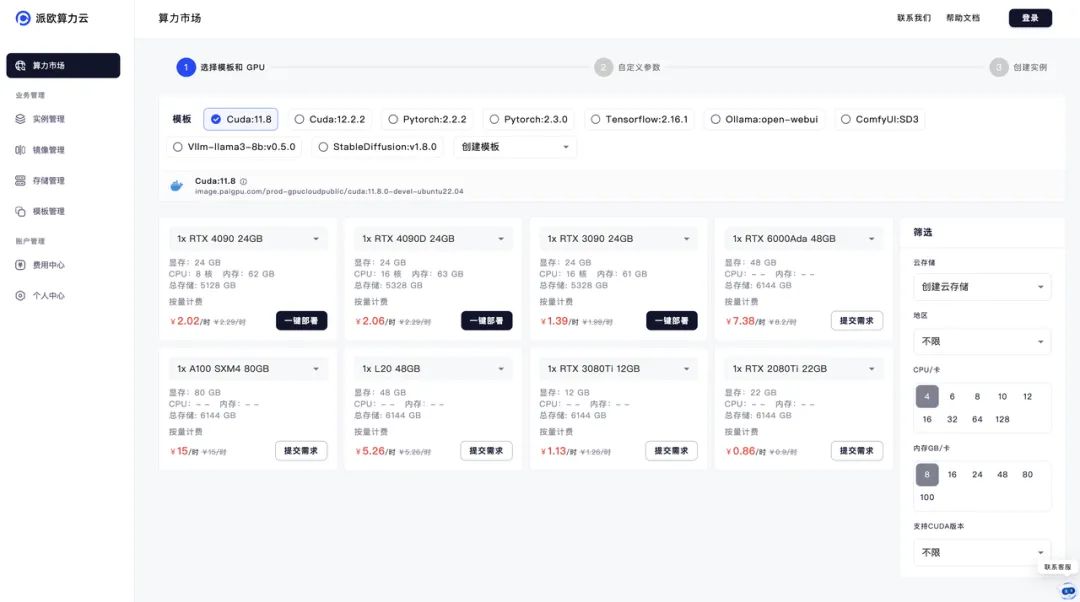
派欧算力云推理加速引擎可广泛应用于多个场景,提供灵活且高效的解决方案。在大模型服务方面,用户只需几行代码即可享受高性价比的推理服务,并且只需为实际消耗的token数量付费。这种方式极大地降低了用户的使用门槛和成本,帮助企业专注于自身业务的增长和发展。
不仅如此,派欧算力云产品还提供容器化的推理基础设施,满足模型定制和私有部署的需求。用户无需担心底层的计算资源管理,只需专注于模型和上层业务,即可自动获得强大的推理性能输出,并按使用时长付费。这种灵活的服务模式使得企业能够快速部署和扩展推理服务,适应不断变化的业务需求。
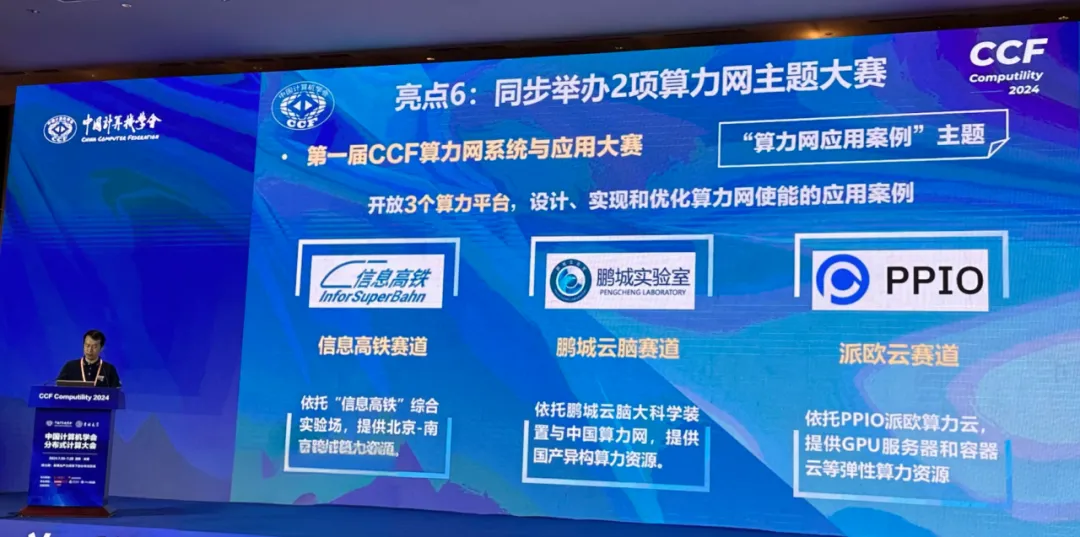
同时,PPIO派欧云积极推动高校学术合作和人才培养。PPIO派欧云首席科学家王晓飞教授在大会发表演讲,分享了PPIO与天津大学在分布式算力云方向的产学研合作最新动态,并介绍了通过汇聚网络边缘侧与端侧算力资源、构建混合异构分布式算力网络的实践案例。此外,依托此次CCF分布式计算大会,PPIO联合中国计算机学会分布式计算与系统专业委员会、中国科学院计算技术研究所分布式系统研究中心、鹏城实验室网络智能研究部,举办第一届CCF算力网系统与应用大赛。大赛旨在激发青年学生的创新创造力,深入了解算力网的系统架构和关键技术,推动算力网技术的创新发展和落地应用,为算力网等分布式领域的创新人才培养和新质生产力实践提供开放合作的平台。经过激烈角逐,最终由南京大学、国防科技大学和河北工业大学队伍获得大赛一等奖。
姚欣强调,随着推理需求的不断增长,降低成本是大势所趋。PPIO派欧云将继续深耕分布式计算及推理加速技术的研究与应用,不断更新迭代推理加速引擎,力求在性能和成本上实现新的飞跃。PPIO的目标是让推理成本降低90%、99%、甚至99.9%,使更多AI创业企业和开发者能够轻松承担大模型推理的费用,从而真正构建出赋能AIGC应用爆发的基础设施。