重磅!DeepSeek-R1上线 PPIO派欧云平台

继 DeepSeek V3上线引起热议后,深度求索团队在 1 月 20 日又放大招了——DeepSeek R1。自发布以来,它迅速成为全球科技界的“顶流”,同时 DeepSeek 的应用软件在中美 App Store 登顶,引发了广泛的关注和讨论。
模型特点
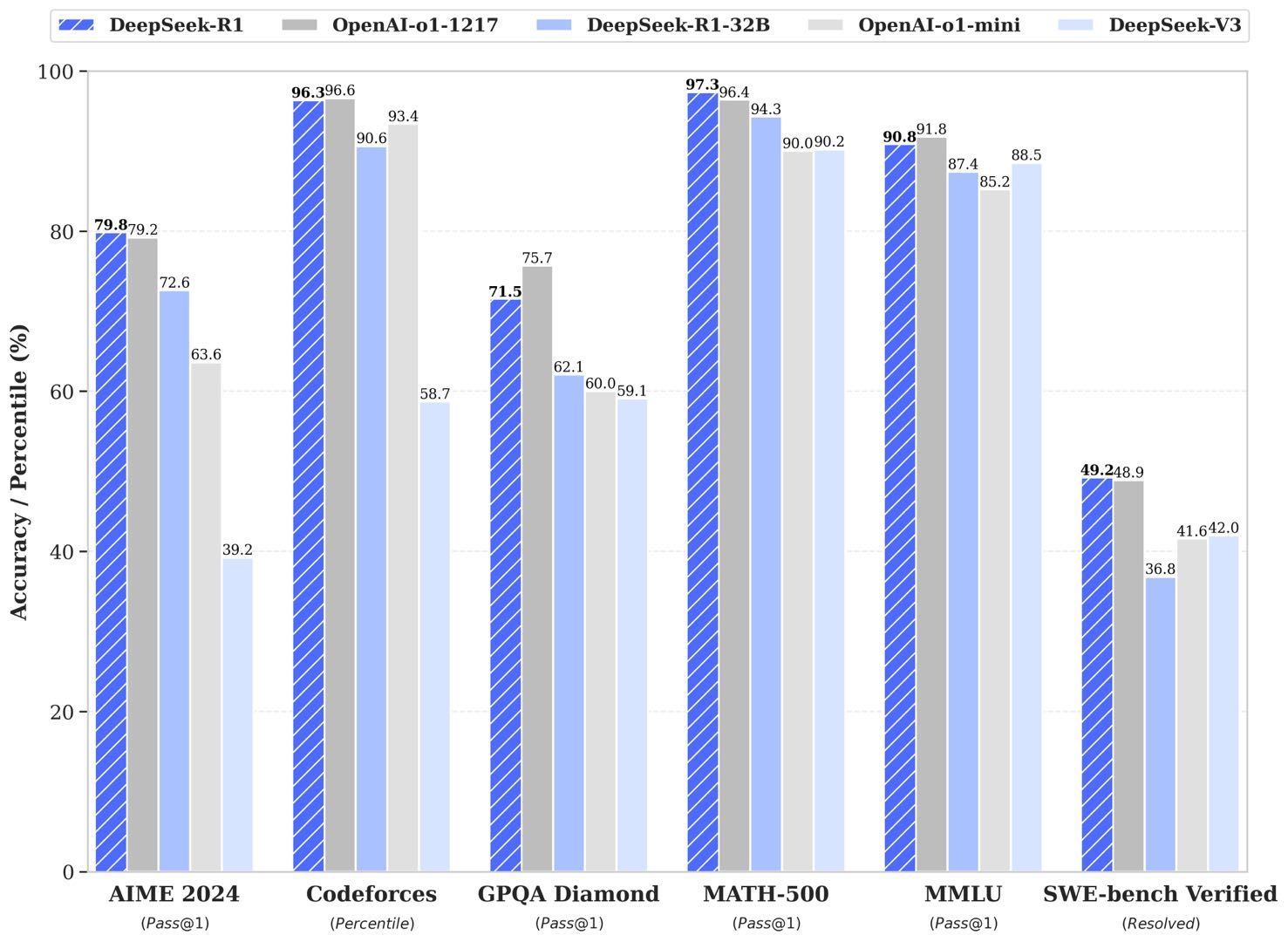
学术领域一骑绝尘
在权威的AIME2024测试中,DeepSeek R1取得了高达79.8%的优异成绩,一举超越了OpenAI的o1-1217。在MATH-500测试里,更是以97.3%的傲人成绩拔得头筹,充分证明了其在学术研究方面的强大实力。
编程能力出类拔萃
在Codeforces竞赛平台上,DeepSeek R1的Elo评级达到了2029,超越了96.3%的人类参赛者。不管是复杂算法的编写,还是程序漏洞的排查与修复,它都能迅速给出高质量的解决方案,是编程人员的得力助手。
深度思考能力
具备深度思考模式,在给出答案的同时,还会展示详细的思维链过程,让用户能够清晰地了解AI的思考逻辑。
轻松接入 API
现在,PPIO派欧云已全面集成 DeepSeek R1。作为一站式 AIGC 云服务平台,PPIO派欧云致力于为开发者提供低成本、高效率的开发模式。开发者只需一行代码即可轻松调用 API,体验前沿 AI 技术。
👉 查看 API 文档
此外,DeepSeek 还支持基于 R1 的输出结果进行模型蒸馏,官方已同步推出 6 个基于 Qwen 和 Llama 模型的蒸馏模型。近期派欧算力云也会跟进部署,以便广大开发者使用。
我们相信,作为国产之光的 DeepSeek,后续还会带给我们更多惊人的技术创新!