
为什么说“Spot GPU实例”是AI算力体系的战略级补充?

在云计算的成本优化领域,有一种独特的计费模式,它允许用户以极低的折扣获取计算资源,堪比“捡漏”。这就是 Spot 实例。
早期的 Spot 实例是“闲置资源的低价甩卖”,本质是供需调节。但在今天的云原生与 AI 生态中, Spot 实例——尤其是 Spot GPU 实例,变成了 AI 算力编排体系中的战略一环。
对于希望最大化利用云预算的开发者和企业来说,理解并善用 Spot GPU 实例是实现成本效益最大化的关键。
# 01
什么是 Spot 实例?
Spot 实例,又被称为竞价实例、抢占式实例,是云服务提供商将数据中心内的闲置计算容量以动态变化的价格进行售卖的一种机制。
Spot 实例在性能上与标准的按需实例(On-Demand Instance)并无二致,但价格却能提供高达 50%~90% 的折扣。
而低价的代价是,当云服务商需要收回这些容量以满足按需或其他更高优先级用户的需求时,这些 Spot 实例可能会被中断。
Spot 实例的发展反映了云计算市场从粗放走向精细化运营的趋势。
Spot 实例的鼻祖是亚马逊 AWS。2009 年,AWS 首次推出 Spot 实例,当时采用的是纯粹的竞价拍卖模式,价格每 5 分钟剧烈波动一次,用户必须像股票交易员一样频繁出价和监控价格,使用门槛较高。
2017 年 11 月,AWS 对 Spot 实例的定价模型进行了重大改革,不再是高频的实时竞价,而是转变为基于长期供需趋势的平滑调整,价格变化变得更加缓慢和可预测。同时,AWS 正式将“竞价型实例”更名为“Spot 实例”。这次变革大大降低了用户的使用难度。
继 AWS 之后,全球大大小小的云服务商也纷纷推出了自家的 Spot 实例服务,印证了 Spot 模式在市场上的巨大需求。
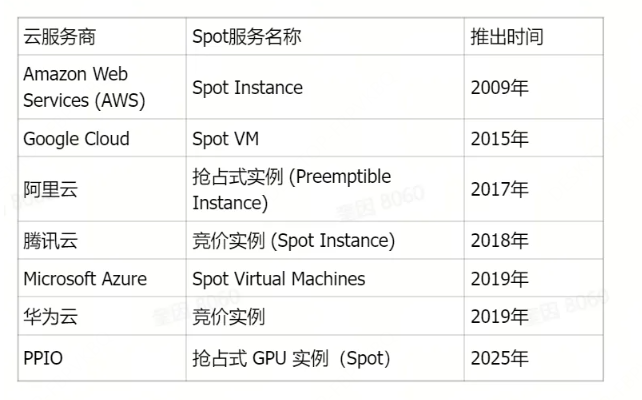
# 02
Spot 在 AI 时代的新机遇
由于存在被中断的可能性,Spot实例并非适用于所有工作负载。它最适合那些无状态、具备容错能力、可中断或可断点续算的业务场景。
在过去,这些场景主要包括:
- 大数据与数据分析:Hadoop、Spark 等分布式计算任务,单个节点的丢失不会影响整个集群的最终结果。
- 批量处理与科学计算:基因测序、金融建模、气象模拟等任务,通常可以被分解成许多可以独立运行的小任务。
- CI/CD 与测试环境:开发和测试环境对稳定性的要求不如生产环境高,使用 Spot 实例可以大幅降低研发成本。
- 图像与视频渲染:渲染农场中的每个节点独立处理一帧或一部分画面,中断后可以由其他节点接替。
- Web 服务与 API 后端:通过负载均衡和弹性伸缩组,可以组合使用 Spot 实例和按需实例,在保证服务稳定性的前提下降低成本。
在大模型时代,最大的算力使用场景就是 AI 训练与 AI 推理。在当前 AI 大模型爆炸式增长的背景下,Spot 实例的价值被进一步放大。
在 AI 训练场景,深度学习的训练天然支持断点恢复:训练数据不是一次性全部加载,而是以小批量(batch)的形式持续输入模型;模型的参数更新以“epoch”(完整遍历一次数据集)为单位累积,会定期保存状态(checkpoint)实现断点续训。这意味着 AI 训练任务不再依赖稳定算力,而是可以主动吸收更加灵活的 Spot 算力。
相比之下,AI 推理场景对延迟和稳定性要求更高。然而,Spot 依然大有可为。
实际上,许多推理并非严格实时——例如批量生成 embedding、微调模型时的验证任务、定时生成用户画像、或面向海外时差波峰波谷的调度。
如果将推理能力按冷热分层,热路径保持按需实例稳定承载,冷路径通过 Spot 灵活扩张——就能在保证服务 SLA 的前提下实现成本大幅下探。
当然,AI 训练与推理目前仍然以稳定的算力供应为核心。不过,在短时间或实验性的深度学习训练与推理任务,如模型训练实验、算法验证、小规模推理、CI/CD与测试环境集群等,仍然可以将 Spot 算力作为稳定算力的战略级补充。
# 03
PPIO Spot GPU 实例低至 5 折
面向 AI 时代的新需求,国内领先的分布式云计算服务商 PPIO 在 2025 年推出了 Spot GPU 实例。
极低的成本是 PPIO Spot 实例的第一特色,其价格通常为按量计费价格的 50%,计费规则与按量计费类似,即先使用再付费,为实际使用时长付费。其中,4090 仅 ¥0.99/小时,H20 仅 ¥3.40/小时,H100 仅 ¥5.25/小时。
Spot 的运行流程如下:

- 选择合适的实例规格创建 GPU 实例,计费方式选择抢占式计费。即创建抢占式 GPU 实例(Spot 实例)。
- 创建后的1小时保护期内,Spot 实例稳定运行。您可以按需开关机或释放。
- 平台定时检测资源库存。当资源库存不足时,对于超出保护期的 Spot 实例,发送1小时后中断回收的通知。
- 收到回收通知后,请您及时确认和响应,保存需要的数据。
- 到回收时间点后,Spot 实例被强制回收,自动释放。
现在,您可以到PPIO官网控制台(或点击阅读原文),在实例管理页面单击「创建新实例」,「计费方式」选择「抢占式计费」,并完成其他参数设置,即可创建抢占式 GPU 实例。
通过 API 调用创建 GPU 实例接口时,将 billingMode 设置为 spot ,即可创建抢占式 GPU 实例。
如果你有 Spot 需求,可扫码联系我们👇

# 04结论
拥抱云计算的成本效益新范式
从最初的“竞价”到如今的“平稳定价”,Spot 计费模式已经发展成为云计算成本优化的标准工具之一。它不仅是云服务商提升资源利用效率的利器,更是用户实现极致成本效益的“秘密武器”。
通过深入理解其运作机制,并结合业务特性进行合理架构设计,企业和开发者可以安全、高效地利用 Spot 实例,将节省下来的预算投入到更有价值的创新活动中,从而在激烈的市场竞争中获得优势。



