
热门显卡折扣来袭!长租单卡低至9.9元/小时


H100 是英伟达(NVIDIA)目前最顶级的显卡之一,专为 AI 训练和高性能计算设计。
在深度学习训练、科学模拟等前沿领域,H100 凭借其卓越的并行计算能力和高效的显存管理能力,为各类复杂计算任务提供了强大的硬件支持。
为降低企业算力使用门槛,PPIO 推出 H100 显卡专项优惠计划,按需租用 H100 单卡低至 12.9 元/时,长期租用更可享单卡 9.9 元/时的超值价格,让高性能计算触手可及。

H100 性能一览
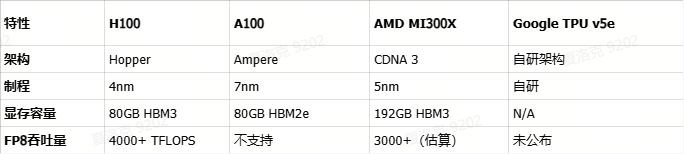
H100 基于 Hopper 架构,采用台积电 4nm 制程,相较前代 A100(Ampere 架构,7nm),在能效比、计算密度上提升巨大,主要特性如下:
- 架构:Hopper
- CUDA核心数:16896
- Tensor核心:528
- 显存:80GB HBM3(带宽高达 3.35TB/s)
- Transformer Engine:通过 FP8+Tensor Core 加速,能够显著提升训练速度
- 应用场景:大规模 AI 训练、HPC、企业级 AI 推理
H100 特别适用于大型 AI 模型训练,可以大幅提升训练效率。
性能对比
相比前代 A100,H100 提升了数倍的计算性能,与 AMD 同期发布的 MI300X 相比,H100 在主流 AI 工作负载中表现更优。
结尾
PPIO GPU 容器实例提供免运维 GPU 算力,用户可以开箱即用,无需复杂配置。且支持按需计费,计费透明,让更多中小企业及开发者可以使用性价比更高的 GPU 算力。



