PPIO私有化部署模板上新!10分钟拥有专属最新DeepSeek模型

这两天,DeepSeek接连发布了升级版R1模型DeepSeek-R1-0528及蒸馏模型DeepSeek-R1-0528-Qwen3-8B,模型性能相较于此前R1模型大幅升级。DeepSeek-R1-0528性能自是不必多言,值得注意的是,根据升级版R1模型思维链提取出来蒸馏模型性能依旧强大,在数学测试中表现与 Qwen3-235B 相当,可以说是“小参数大性能”。
此前,不少企业和个人尝试将模型进行私有化部署,但是,如果将DeepSeek-R1(671B)进行私有化部署,至少需要1.5TB显存,按官方推荐配置需要将近20张NVIDIA H100 80GB显卡,门槛较高。
而小参数的DeepSeek-R1-0528-Qwen3-8B,则可以完美匹配这一需求。该模型在保持较高推理能力的同时大幅降低了运行资源需求,适合个人及中小企业部署。现在PPIO派欧云上线了该模型私有化部署模板,用户可一键将DeepSeek-R1-0528-Qwen3-8B部署在云服务器上,10分钟就能拥有专属模型。
模型私有化部署教程
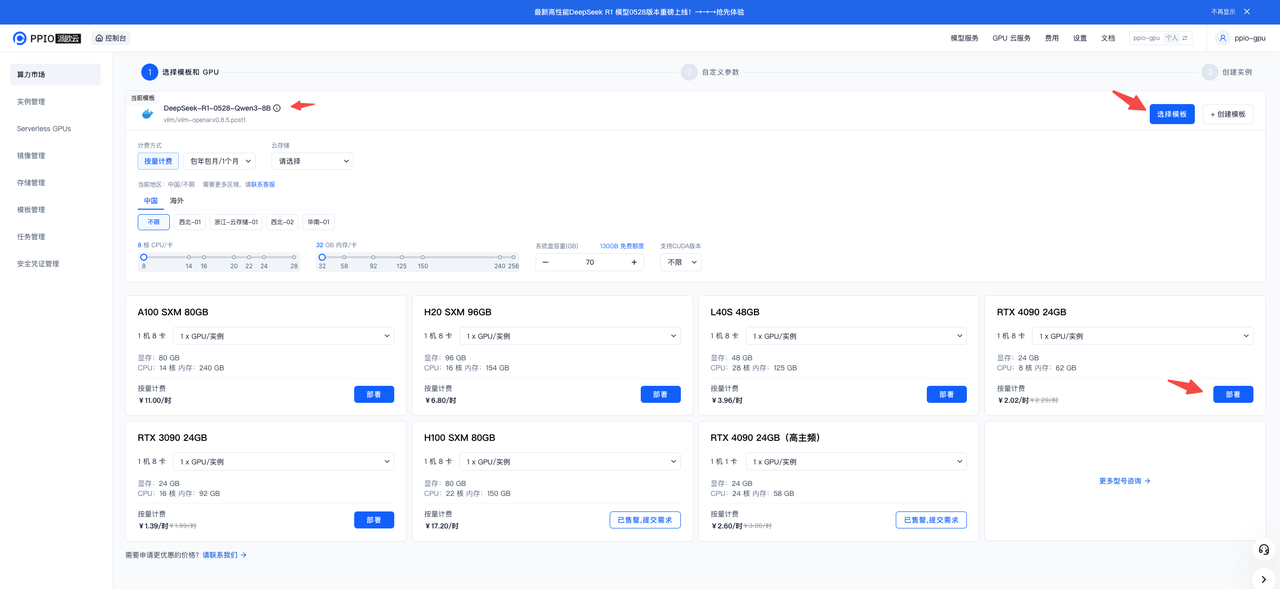
选择模板与配置
打开PPIO派欧云算力市场,选择 deepseek-ai/DeepSeek-R1-0528-Qwen3-8B 模版,选择卡型 4090 点击部署。
算力市场地址:https://ppio.cn/gpu-instance/console/explore
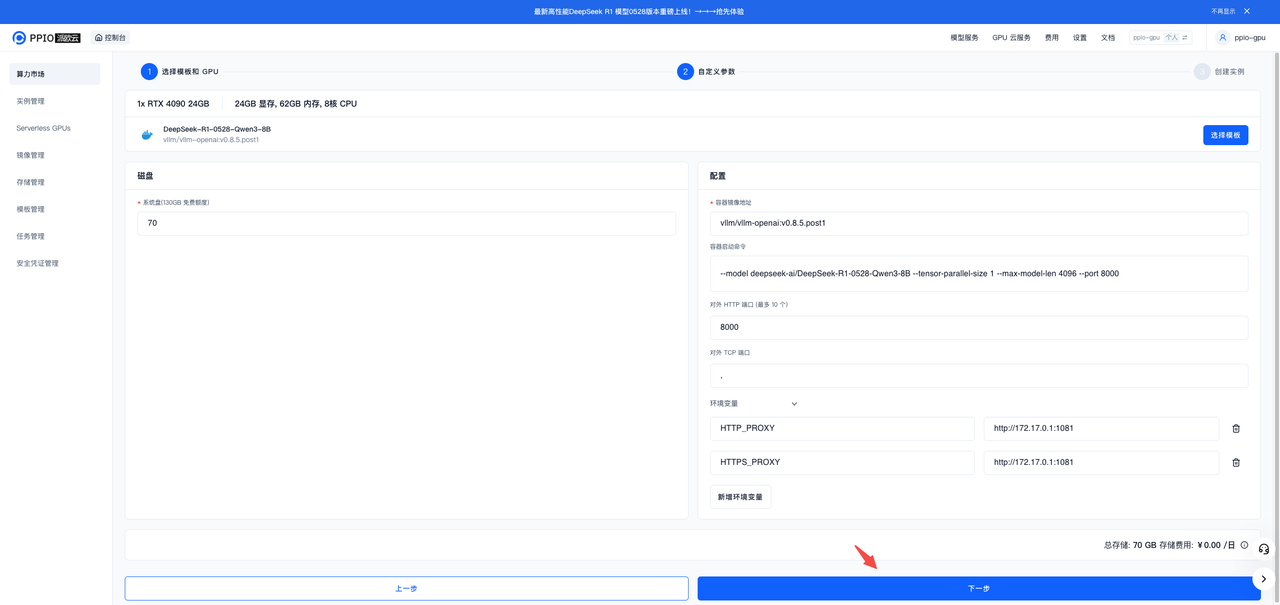
确认部署参数
检查部署参数确认页面。确认无误后,点击 下一步。
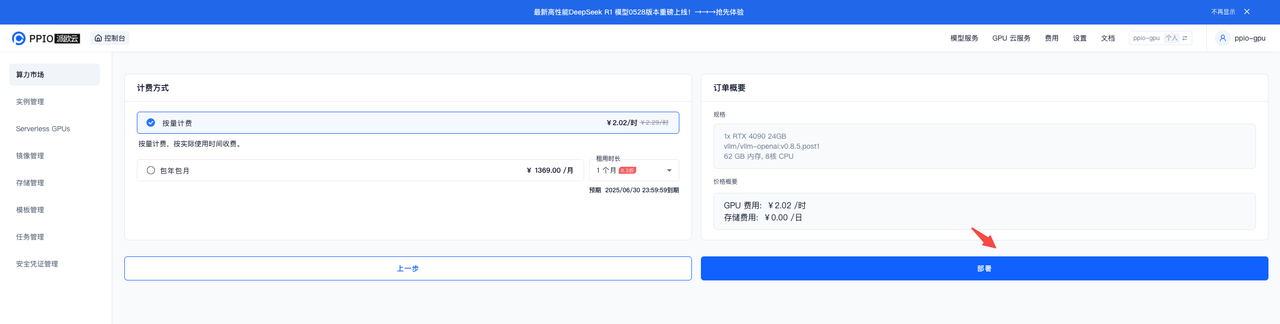
启动部署
在最终确认页面,点击 部署 按钮启动实例创建。 此过程可能需要几分钟,请耐心等待。
查看部署进度
点击实例管理,进入控制台查看部署进度
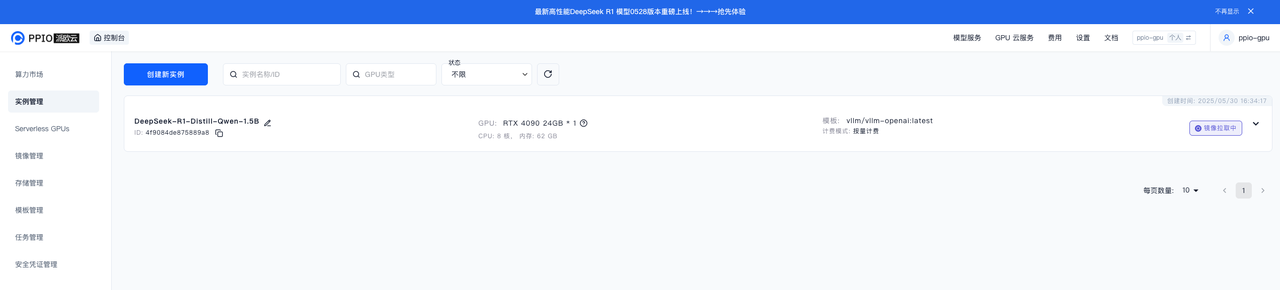
点击实例,查看镜像拉取进度
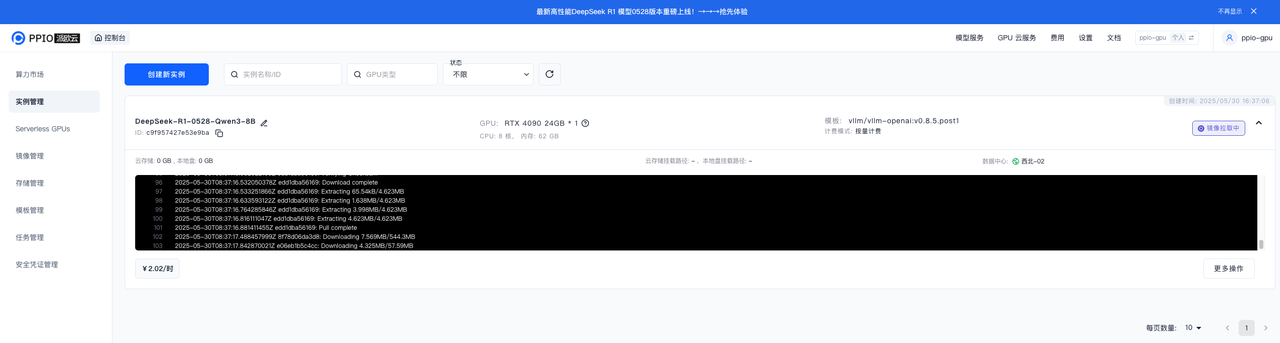
等待实例变为运行中,点击日志 —> 实例日志查看模型拉取进度,等待模型拉取完成
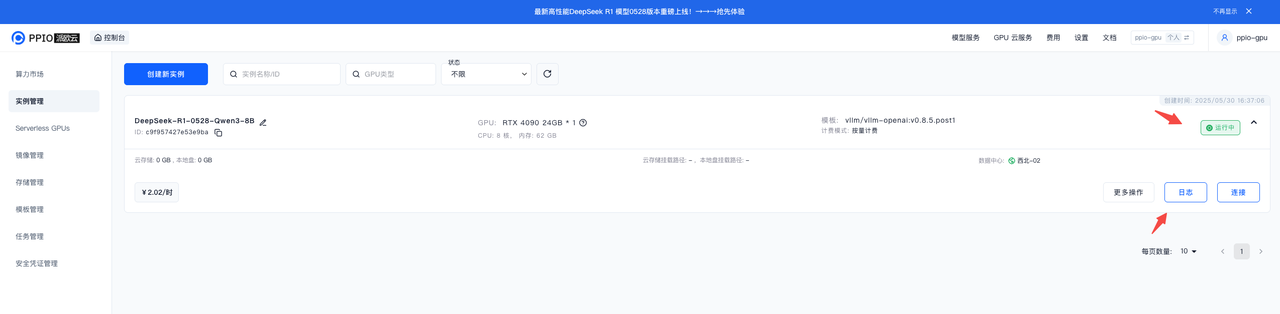
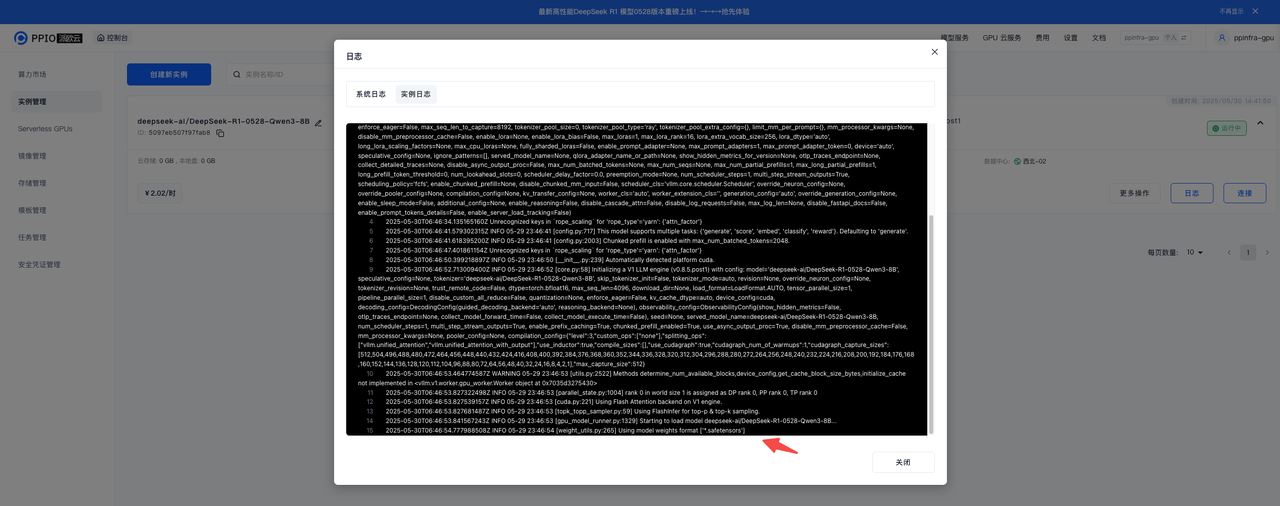
日志出现 “Application startup complete.” 即为部署完成!
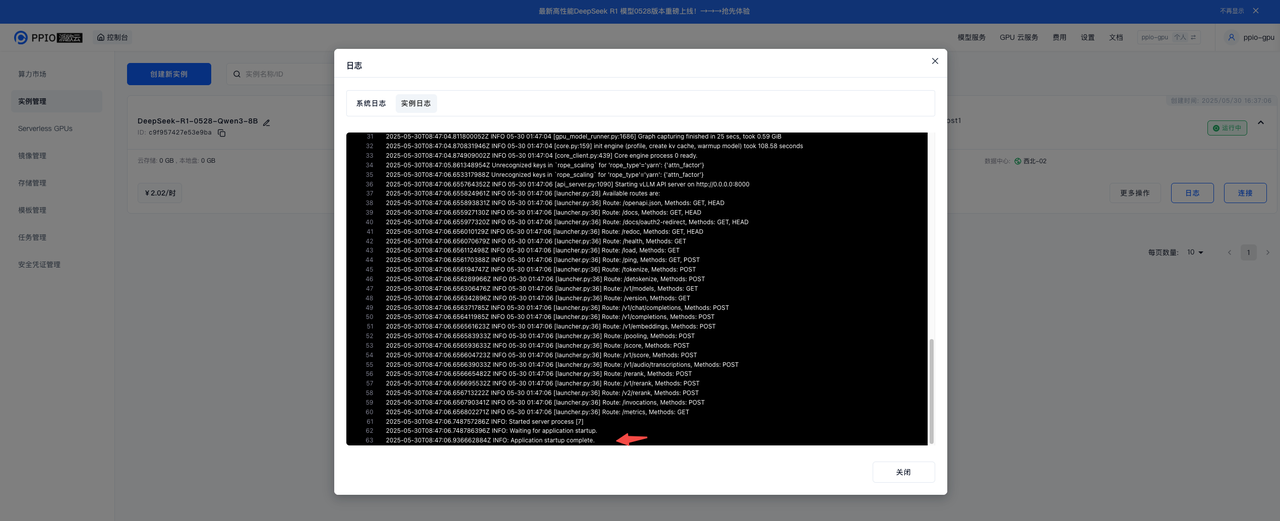
获取模型访问地址
点击实例连接,拷贝端口 8000 的 HTTP 映射,即模型访问
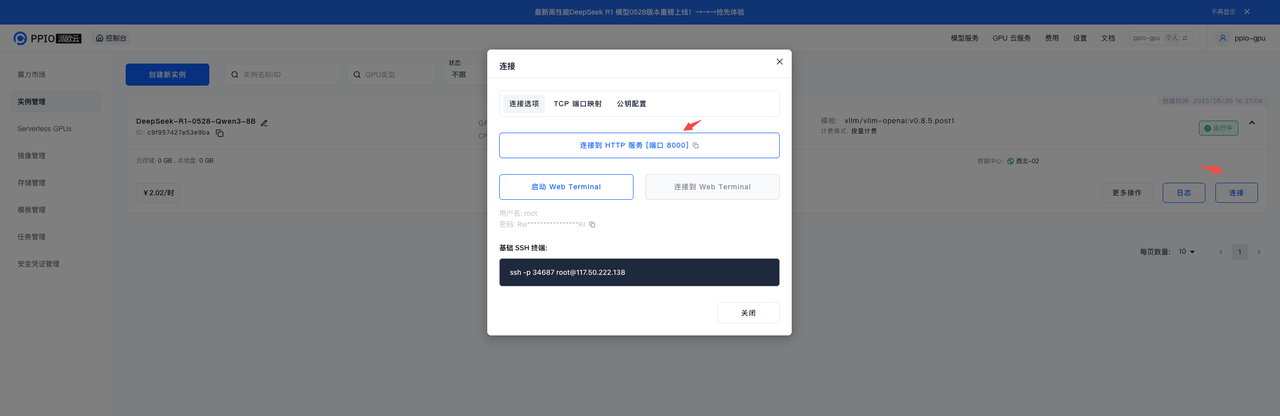
访问您的私有模型
注意请将下文中的
“https://c9f957427e53e9ba-8000.cn-northwest-2.gpu-instance.ppinfra.com”
替换为您真正的访问地址,复制以下代码,访问您的私有模型!
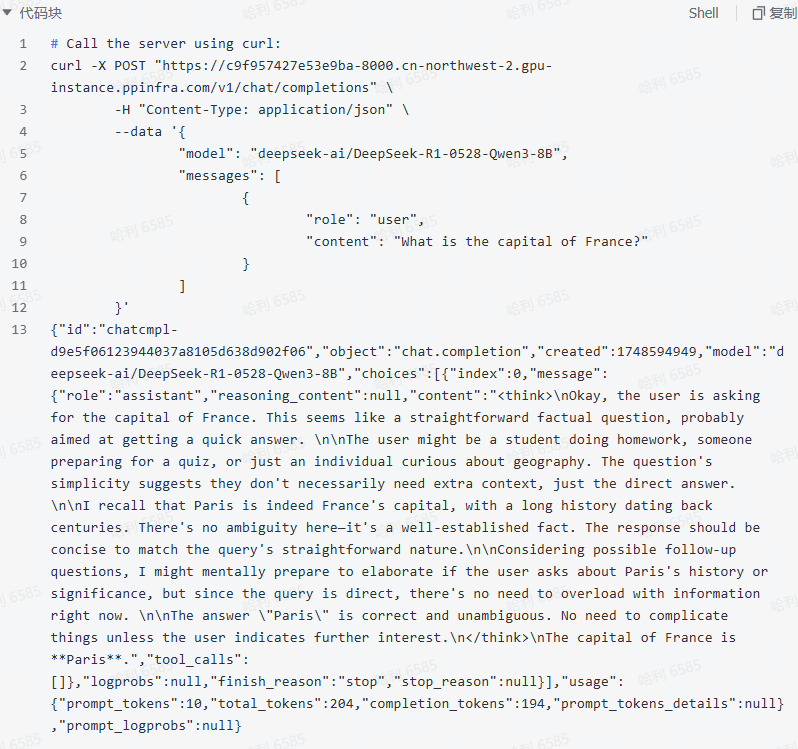
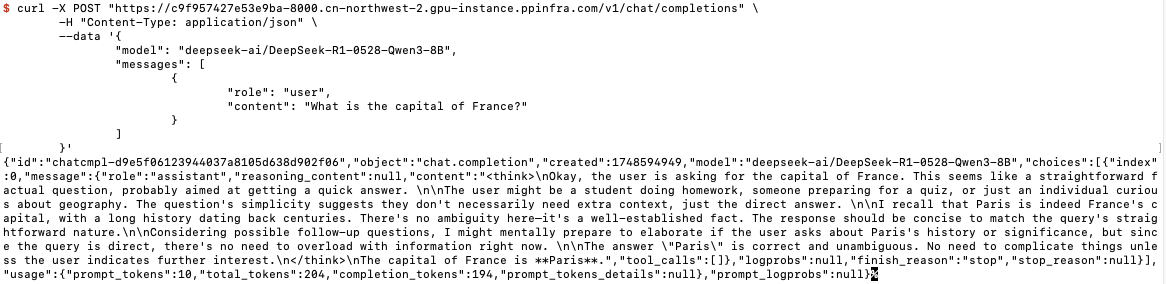
将API 地址配置到您的 chatbox 等应用,就可以拥有专属模型及聊天助手!
目前,PPIO算力市场已上线18个私有化部署模板,除了DeepSeek-R1-0528-Qwen3-8B,用户也可以将llama3-8b:v0.5.0 、StableDiffusion:v1.8.0等模型快速进行私有化部署,帮助企业及个人降低模型部署成本,实现高效、安全调用。