
PPIO实测一手性能数据,MoE模型推理效率显著提升,DeepGEMM重磅开源!

开源周内传来新消息,DeepSeek 正式发布了 DeepGEMM 开源库。
这是一个专为稠密和 MoE 模型设计的FP8 GEMM计算库,特别为 DeepSeek - V3/R1等MoE FP8量化模型的训练和推理提供了强有力的支持。
DeepGEMM 针对英伟达 Hopper 架构 GPU (如H100,H200,H800)进行了深度优化。
主要特点是代码简洁(核心部分仅300行左右)但性能出色,在各种矩阵形状下都能够媲美甚至超越专家调优的库。
作为一家专注于提供高性能 AI 计算服务的云平台,PPIO派欧云已经部署了大量 MoE FP8 量化模型(例如 DeepSeek FP8 版本)。
为了更好地利用 DeepGEMM 技术,提升这类模型的推理效率,PPIO 第一时间对 DeepGEMM 的性能进行了全面测试。
在了解具体测试数据之前,我们先来熟悉一些相关的基础概念。
什么是 GEMM?
GEMM (General Matrix Multiplication) 是深度学习中最基础、最重要的计算算子,GEMM 优化是高性能AI计算的核心。
DeepGEMM 是一个专为加速深度学习中关键 GEMM 运算而设计的开源库,通过提高 GEMM 计算效率,直接提升整个 AI 系统的性能表现。
DeepGEMM 的独特优势
与 CUTLASS 和 CuTe 这类成熟的模板库相比,DeepGEMM 采取了轻量级设计路线:它并非追求广泛兼容所有 GPU 和计算场景,而是专注于充分发挥 Hopper 架构的 FP8 计算能力,特别针对 DeepSeek R1 和 V3 等大模型常见的矩阵形状进行了精细优化。
DeepGEMM 的技术创新
DeepGEMM 通过以下四项核心技术创新实现了性能突破:
- 即时编译技术 ( JIT )
传统方法需要预先编译 CUDA 代码再进行调用,而 DeepGEMM 引入的 JIT 技术将编译过程隐藏在运行时,无需手动编译。
开发者无需创建复杂的 Python 接口,简化了开发流程,仅需几行代码即可实现功能。
- 计算与传输重叠优化
DeepGEMM 通过同时进行数据传输和计算操作,充分利用了 Hopper 架构 TMA ( Tensor Memory Accelerator ) 特性,进一步优化了数据传输效率。同时,DeepGEMM 使用底层 PTX 指令,实现极致性能。
- 任意矩阵尺寸支持
传统 GEMM 实现要求矩阵尺寸为 2 的幂次(如128、256),而 DeepGEMM 支持非对齐块大小的矩阵。这一特性避免了内存浪费,提高整体计算效率。
- FFMA SASS 指令级优化
通过修改 FFMA 指令的 yield 和 reuse 位,创建更多重叠 MMA 指令与 promotion FFMA 指令的机会,即使对底层理解有限也能在某些场景获得 10% 以上性能提升。
DeepSeek 官方测试:DeepGEMM 加速比
根据 DeepSeek 官方在 H800 GPU 上进行的全面测试,DeepGEMM 与经过优化的 CUTLASS 3.6 相比,在各种计算场景中均实现了明显的性能提升。以下是 DeepSeek-V3/R1 推理过程中的加速效果:
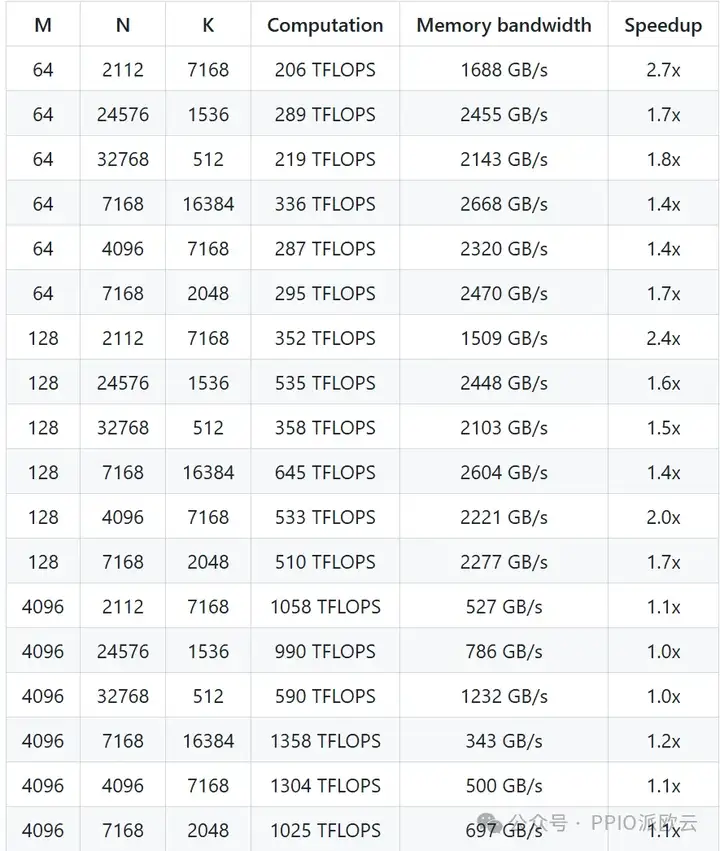
- 稠密模型的常规 GEMM
在小矩阵计算方面,DeepGEMM 性能提升最为显著,最高可达到 2.7 倍的加速比率,极大地提高了小批量数据推理效率。
对于大矩阵计算任务,DeepGEMM 仍然能够稳定地提供约 1.2 倍的性能提升,保证了大规模矩阵运算的高效执行。
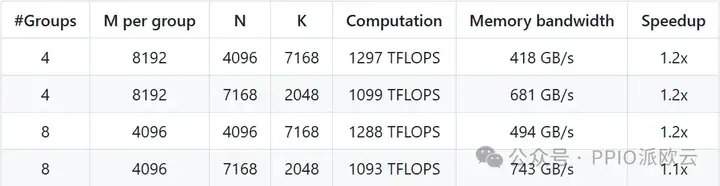
- MoE 模型的分组 GEMM(使用连续存储布局)
连续存储布局主要应用于模型预填充 (Prefilling) 阶段,是处理长文本输入的关键环节。
测试结果表明,DeepGEMM 在这一场景下能够稳定实现约 1.2 倍的计算加速,有效缩短了模型响应时间。
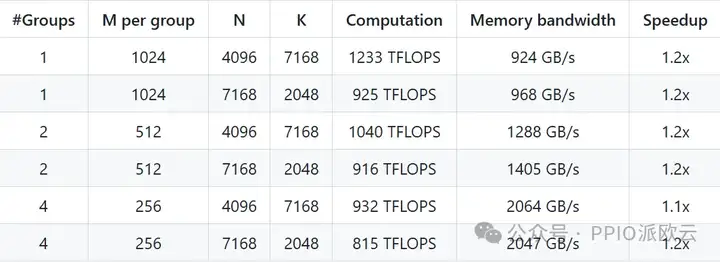
- MoE 模型的分组 GEMM(使用掩码存储布局)
掩码布局主要用于模型解码 (Decoding) 阶段,直接影响模型生成文本的速度。
在这一关键环节,DeepGEMM 同样实现了约 1.2倍的性能提升,使模型能够更快地完成单个 token 的生成过程。
PPIO 一手测评:DeepGEMM 通用性
在 MoE 模型的推理场景中,PPIO对 DeepGEMM 在 H100和 H200 两款 GPU 上的性能表现进行了详细测试,并与官方 H800 的测评数据进行了对比。
首先,我们整理了 H100、H200和H800 三款 GPU 中影响 DeepGEMM 性能的关键硬件参数:
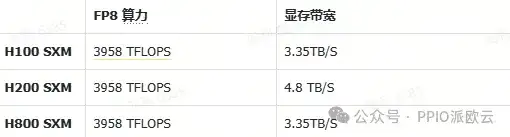
以下是详细的评测结果:
- MoE 模型的连续存储布局分组 GEMM(训练前向、推理预填充)
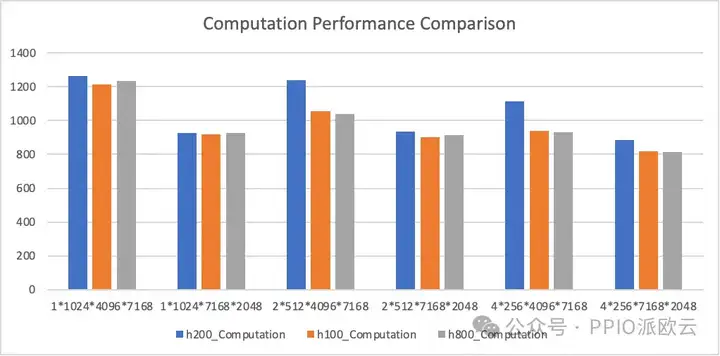
在使用连续存储布局的 MoE 网络中,H100/H200/H800(官方)的表现差异不大。
下图展现了显存带宽占用的对比测试,由于受限于计算瓶颈,且三款显卡在 FP8 算力上的差距不大,它们的性能表现没有显著差异。
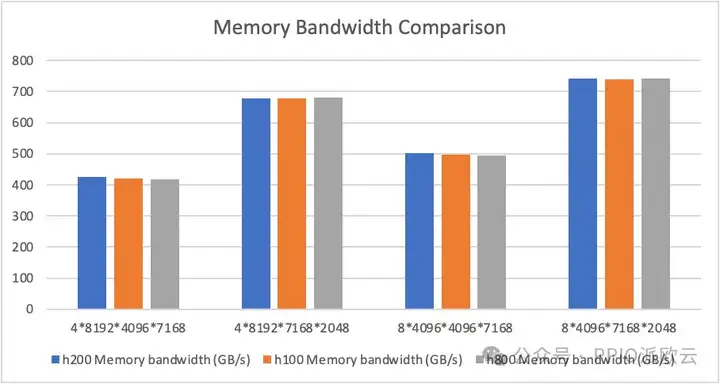
下图为计算性能的对比图,由于未达到访存瓶颈,三款显卡在性能上并无明显差距。
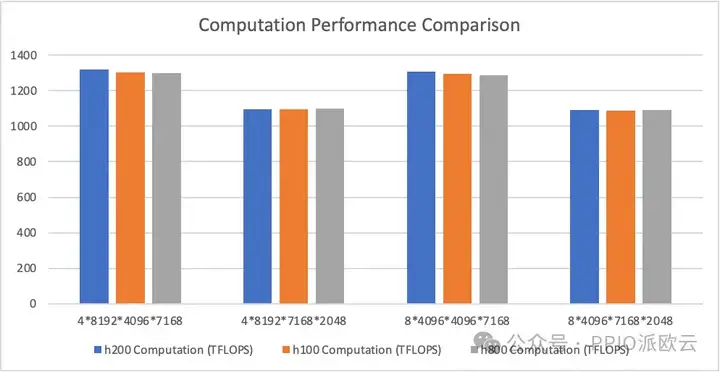
- MoE 模型的掩码存储布局分组 GEMM(推理解码)
在使用掩码存储布局的 MoE 网络中,H200 的性能表现相对最优,H100 与 H800 的差异非常小。
下图展现了显存带宽占用的对比测试。由于掩码存储布局比连续存储布局占用更多的显存带宽,部分情况已经达到了访存瓶颈,因而三款显卡的表现有所不同:
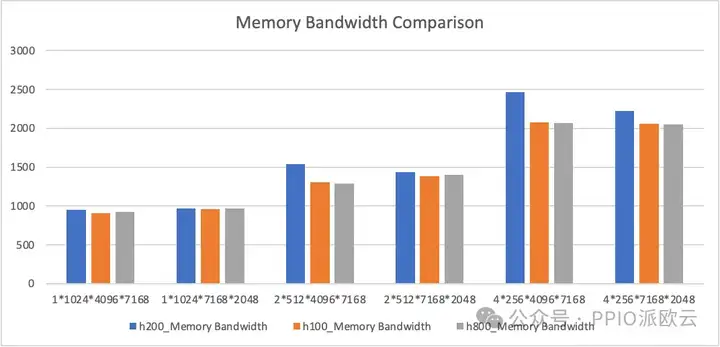
下图是计算性能的对比测试,展示了带宽带来的计算差异:
DeepGEMM 与 SGLang Triton 性能对比
目前,主流推理框架在 MoE 模块中使用的是基于 SGLang Triton 开发的分组 GEMM 算子。我们在 H200 硬件条件下对 DeepGEMM 和 SGLang Triton 进行了性能对比测试:
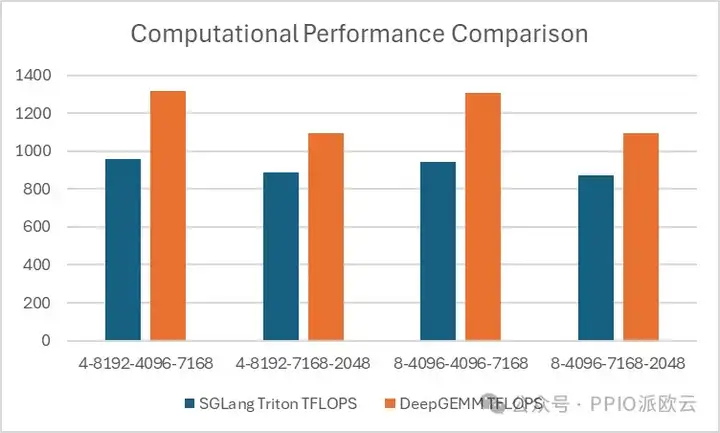
- 对于 MoE 模型的连续存储布局分组 GEMM(训练前向、推理预填充),DeepGEMM 的优势更明显一点:
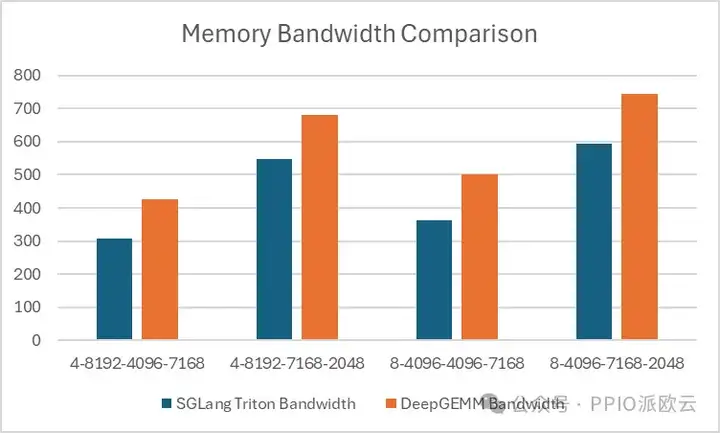
- 对于 MoE 模型的掩码存储布局分组 GEMM(推理解码),可以看出 Triton 更具优势:
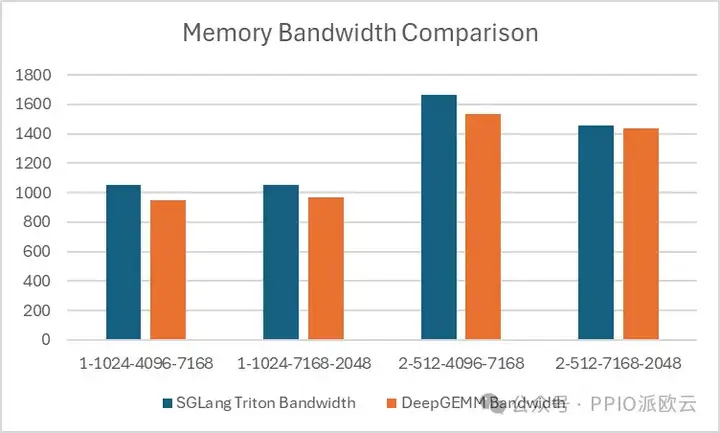
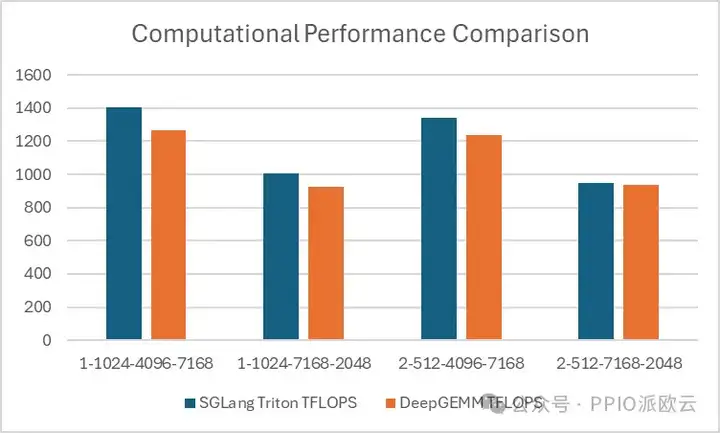
DeepGEMM 在连续存储布局中表现出一定的优势,但在掩码存储布局中,SGLang Triton 的性能更优。
目前,SGLang Triton 的部分算子主要应用于掩码存储场景,因此,DeepGEMM 需要进一步优化,才能在推理框架中替代 SGLang Triton。
总结
根据评测结果显示,DeepGEMM 在 H100、H200 和 H800 等多款 GPU 上均展现出显著的性能优化能力,体现了其良好的通用性。
对于运行在 Hopper 架构上的 MoE 系列模型(如DeepSeek V3和R1),通过对推理框架中的 MoE 模块进行集成优化,将原有的 CUTLASS 版本分组 GEMMs 替换为 DeepGEMM 实现,预计将为模型推理带来约 1.2 倍的加速效果,提升整体性能。
当前,DeepGEMM 还不能完全替代 SGLang Triton,仍需进一步优化以拓宽其应用范围。在推理解码环节,SGLang Triton 依然更为高效,而 DeepGEMM 在训练前向和推理预填充的环节更有优势。



