
PPIO上线Qwen3:百万tokens输入仅0.72元,支持“混合思考”

今天,Qwen 系列大语言模型的最新成员 Qwen3 发布,与 DeepSeek R1、OpenAI o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等全球顶尖模型相比极具竞争力,成为新晋开源新王。
Qwen3 一口气发布了 8 款新模型,全部开源权重。包括:
- 两个 MoE 模型:Qwen3-235B-A22B(总参数 2350 亿,激活参数 220 亿),Qwen3-30B-A3B(总参数 300 亿,激活参数 30 亿)
- 六个 Dense 模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B
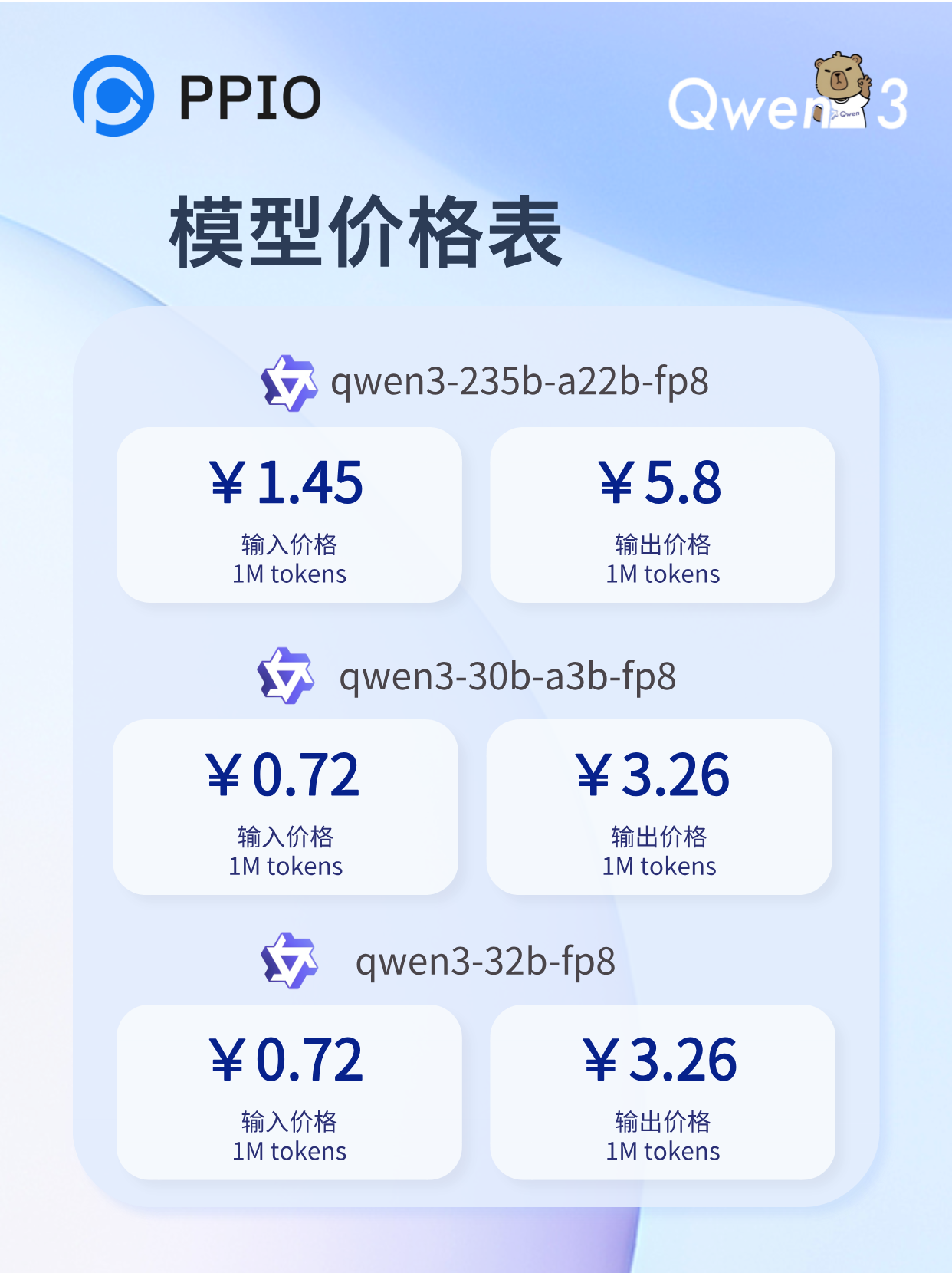
作为一站式 AIGC 云服务平台,PPIO派欧云在第一时间上线了 Qwen3 系列模型!
首批上线三个参数最大的旗舰模型:
Qwen3-235B-A22B
Qwen3-30B-A3B
Qwen3-32B
在线体验:https://ppinfra.com/llm/qwen-qwen3-235b-a22b-fp8
除了上线 Qwen3 模型之外,PPIO 在春节后特别推出的福利活动仍在持续火爆进行中!
只需简单分享 PPIO 专属邀请码,每成功邀请 1 位好友注册并完成实名认证,邀请人即可获得 30 元无门槛代金券,被邀请人也能获得 15 元无门槛代金券。代金券适用于 PPIO 所有大语言模型 API 服务!
点击下方链接,或直接访问网站即可参与:
https://ppinfra.com/user/register?invited_by=N7EUVY
# 01
Qwen3 的主要特点
Ⅰ. 多种思考模式
Qwen3 支持两种模式:
思考模式:模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
非思考模式:模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。
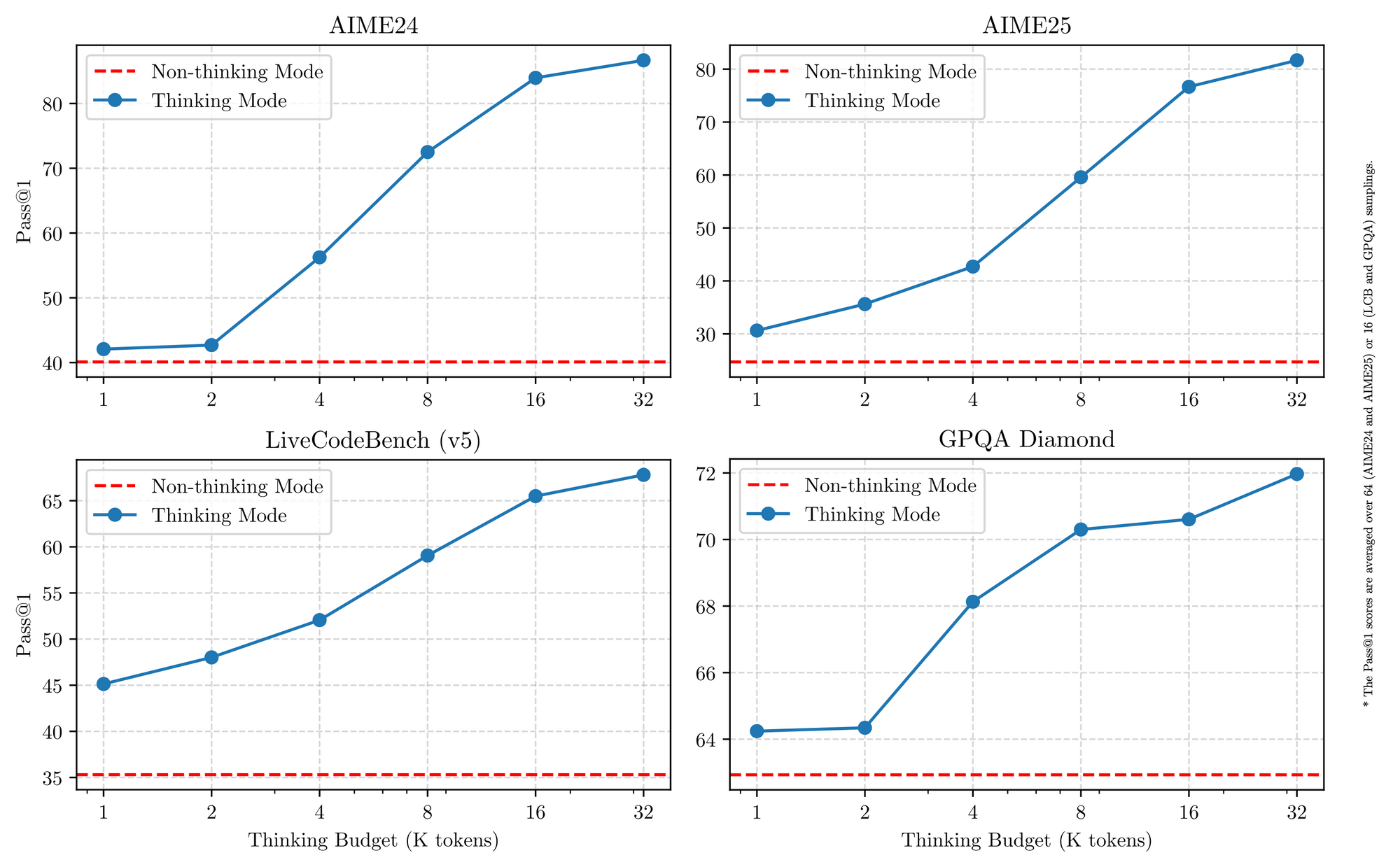
例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。
Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
Ⅱ. 多语言支持
Qwen3 模型支持 119 种语言和方言(包括印欧语系、汉藏语系、亚非语系、南岛语系、德拉威语、突厥语系、壮侗语系、乌拉尔语系、南亚语系等)。
这种广泛的多语言能力为国际应用开辟了新的可能性,使全球用户都能受益于这些模型的强大功能。
Ⅲ. 增强代理能力
Qwen3 优化了模型的编码和代理能力,并增强了对 MCP 的支持。
# 02
预训练(Pre-training)
Qwen3 的预训练数据集相比 Qwen2.5 有了显著扩展。Qwen2.5 是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量是 Qwen2.5 的两倍,约有 36 万亿个 token,涵盖 119 种语言和方言。
Qwen3 不仅从网络收集数据,还从类似 PDF 的文档中收集数据,使用 Qwen2.5-VL 从这些文档中提取文本,并使用 Qwen2.5 来提升提取内容的质量。
Qwen 3 还利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程包含三个阶段。
在第一阶段,模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。
在第二阶段,过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。
在第三阶段,使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
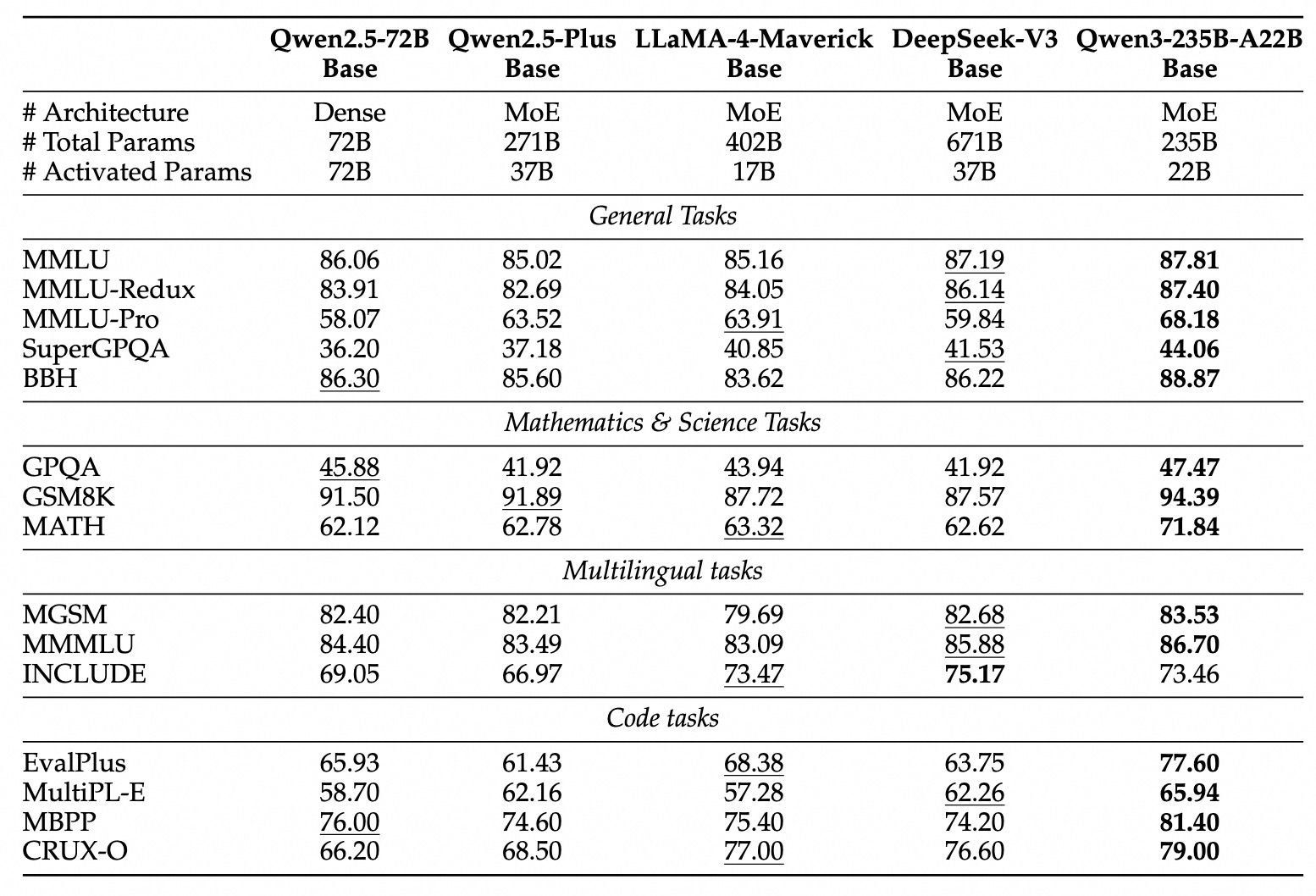
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的 Qwen2.5 基础模型相当。
例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。
特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
# 03
后训练(Post-training)
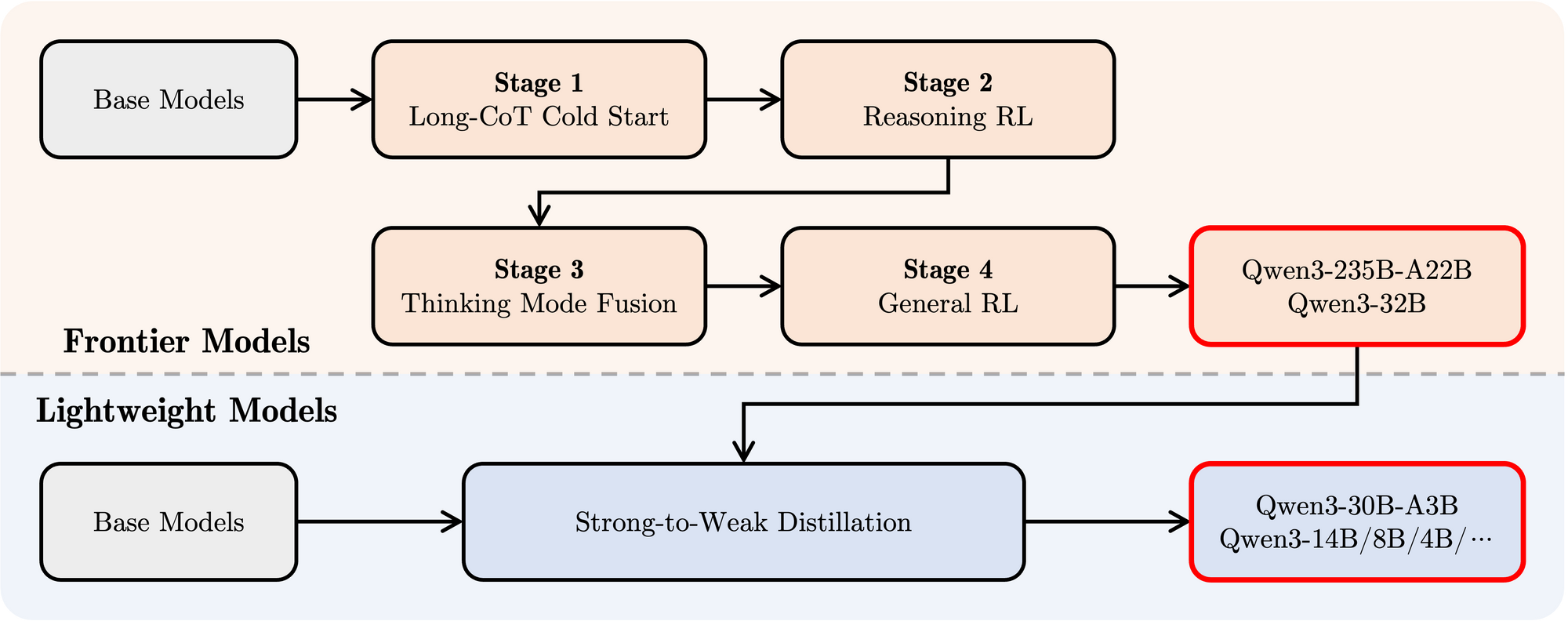
为了开发既能进行逐步推理又能快速响应的混合模型,Qwen3 实现了一个四阶段的后训练流程。
第一阶段,长思维链 (CoT) 冷启动。该阶段使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。
第二阶段,基于推理的强化学习 (RL)。该阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
第三阶段,思维模式融合。该阶段在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。
第四阶段,通用强化学习。该阶段在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
PPIO 上线 Qwen3
PPIO 致力于为企业及开发者提供高性能的 API 服务,目前已上线 DeepSeek R1/V3、Llama、GLM、Qwen 等系列模型,仅需一行代码即可调用。并且,PPIO 通过 2024 年的实践,已经实现大模型推理的 10 倍 + 降本,实现推理效率与资源使用的动态平衡。
目前,以上模型均已上线 PPIO 官网,点击下方链接立即体验!
在线体验:https://ppinfra.com/user/register
API 文档:https://ppinfra.com/docs/model/



