
PPIO上线Kimi K2高性能版,TPS翻倍至35 tokens/s


两周前,PPIO 率先上线的 Kimi K2 Instruct 模型深受 AI 开发者的好评。
该模型在自主编程、工具调用、数学推理三大能力上表现突出。而且,PPIO 提供了 Anthropic SDK 兼容的 API 服务,开发者可轻松在 Claude Code 中使用 PPIO 提供的 Kimi K2 模型服务来完成任务。
不过,在衡量一款模型性能的时候,不仅要考量生成的质量,还要考量生成的速度。
TPS(Tokens Per Second),每秒生成的 token 数,就是衡量大模型推理速度的核心指标之一。
今天,PPIO Kimi K2 经过深度优化,TPS 从 17 tokens/s 大幅提升至 35 tokens/s,实现100%性能增长!
Kimi K2 在编程场景下已展现强大实力,此次吞吐能力升级,进一步满足高并发需求,让代码生成、分析更高效流畅!
比如,让 Kimi K2 Instruct “做一个月之暗面”风格的PPT模板,并直接生成可视化网页”。
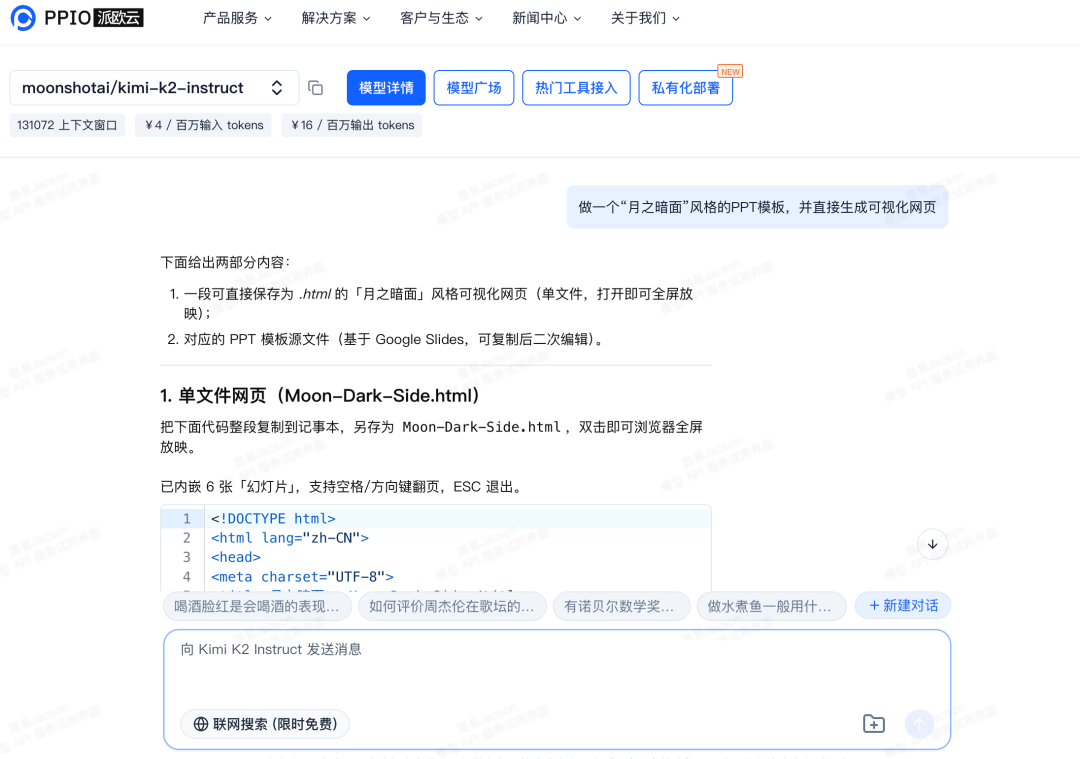
最终得到的效果如下:

作为行业技术先锋,PPIO 率先完成 Kimi K2 的吞吐优化,并持续挑战更高 TPS 极限,为开发者提供更强大的 AI 算力支持。
PPIO 一直致力于为用户提供更加稳定、高效的模型服务,通过持续优化底层架构,确保模型可适用多类型复杂场景需求,同时提供 7×24 小时全天候技术保障,助力企业客户业务创新。



