
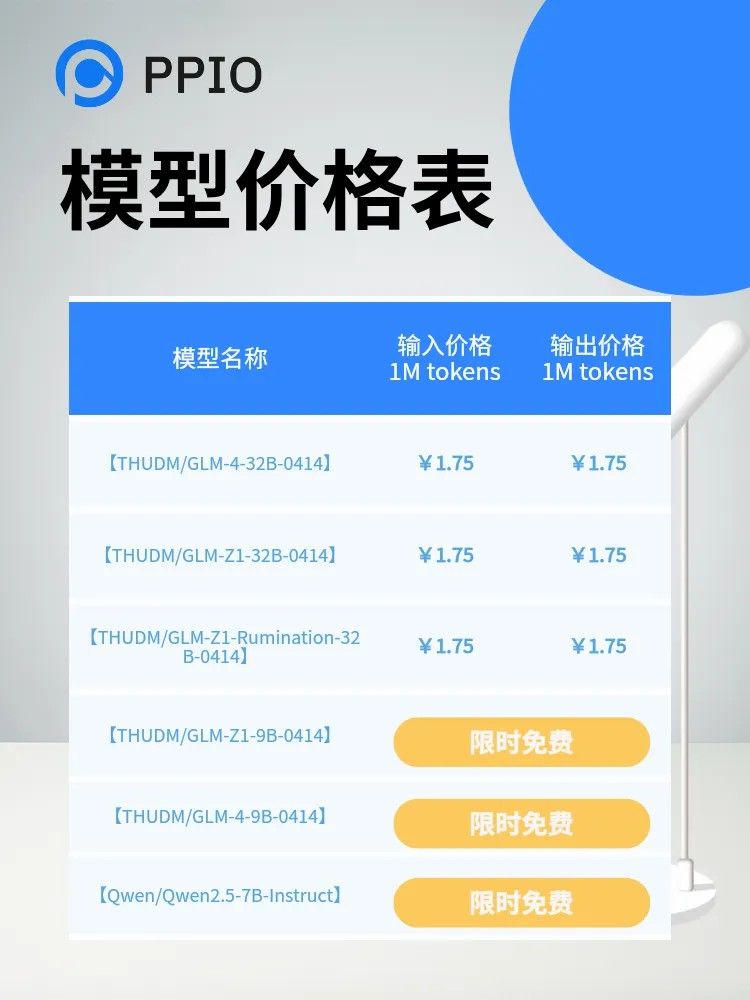
PPIO上线GLM-4-0414系列模型及Qwen2.5-7B-Instruct模型

早在今年 3 月,智谱就曾预告会在 4 月中旬开源新的 GLM 模型,果然,GLM-4-0414 系列准时登场。
此次开源的新模型覆盖基座、推理、沉思三大类型,根据官方公布数据显示,部分模型可在性能上比肩 OpenAI 的 GPT-4o 和 DeepSeek 的 V3/R1 系列模型。
作为一站式 AIGC 云服务平台,PPIO派欧云随即上线了上述模型及 Qwen2.5-7B-Instruct 限时免费版,并对模型进行了全链路优化,在保持原始模型精度的前提下大幅降低推理延迟,开发者通过 API 接口即可高效调用模型。
模型特点
基座模型 GLM-4-32B/9B-0414
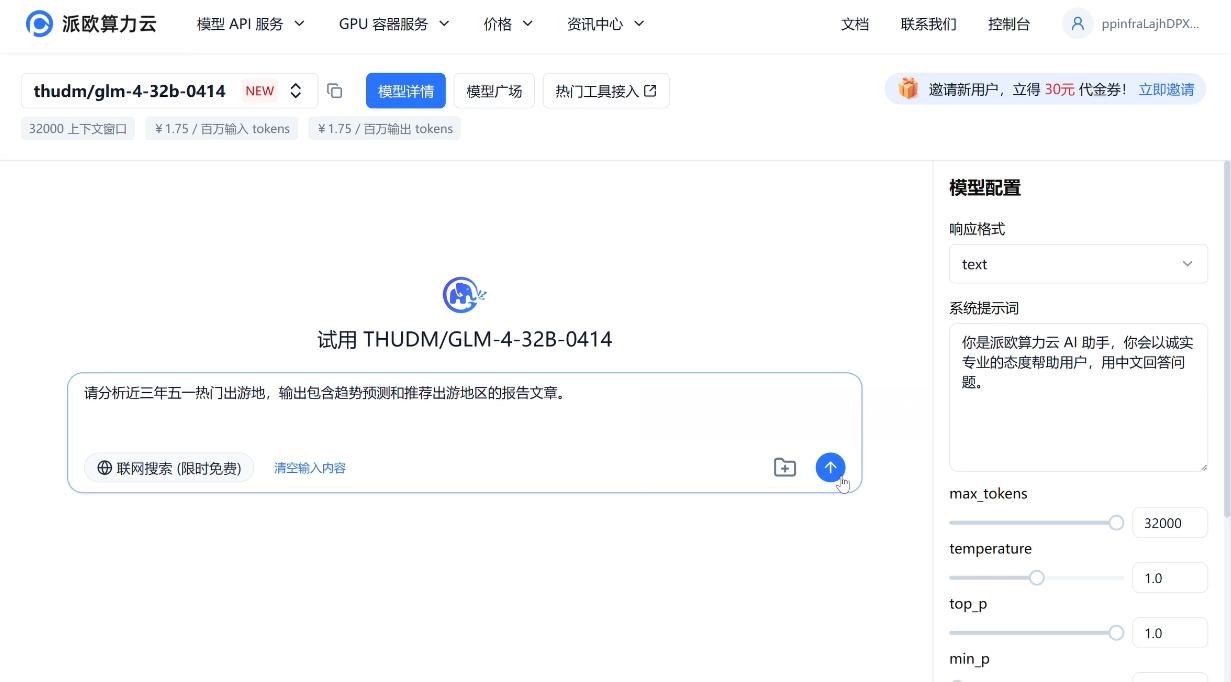
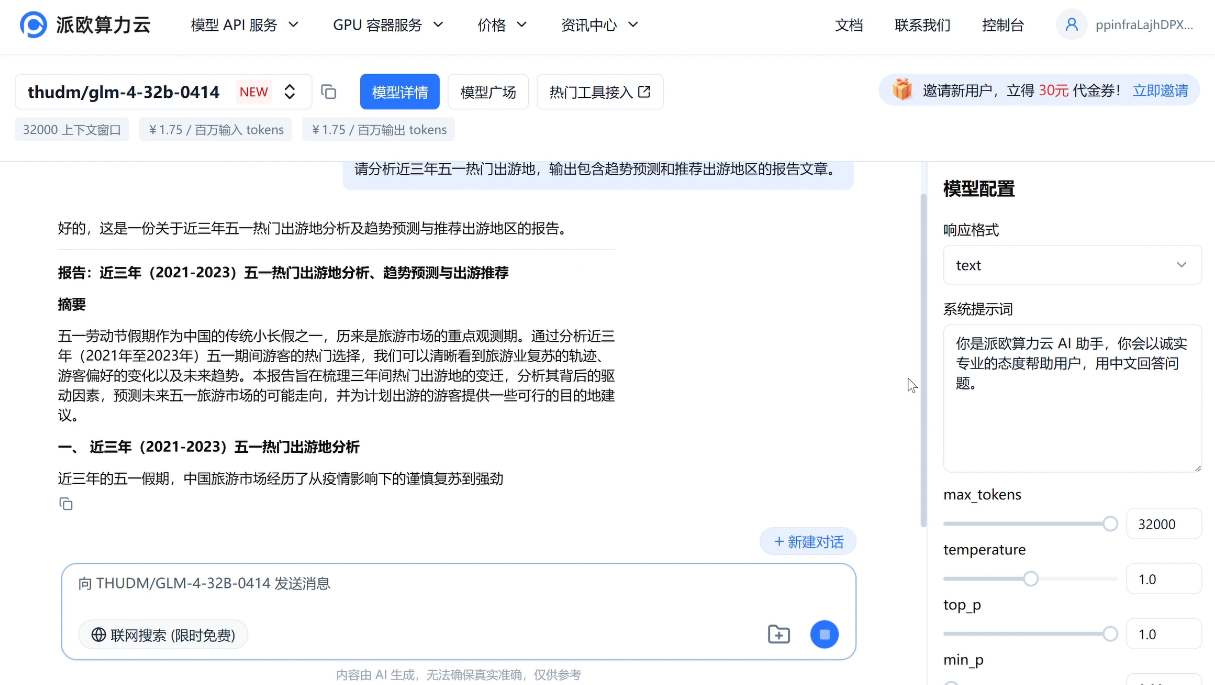
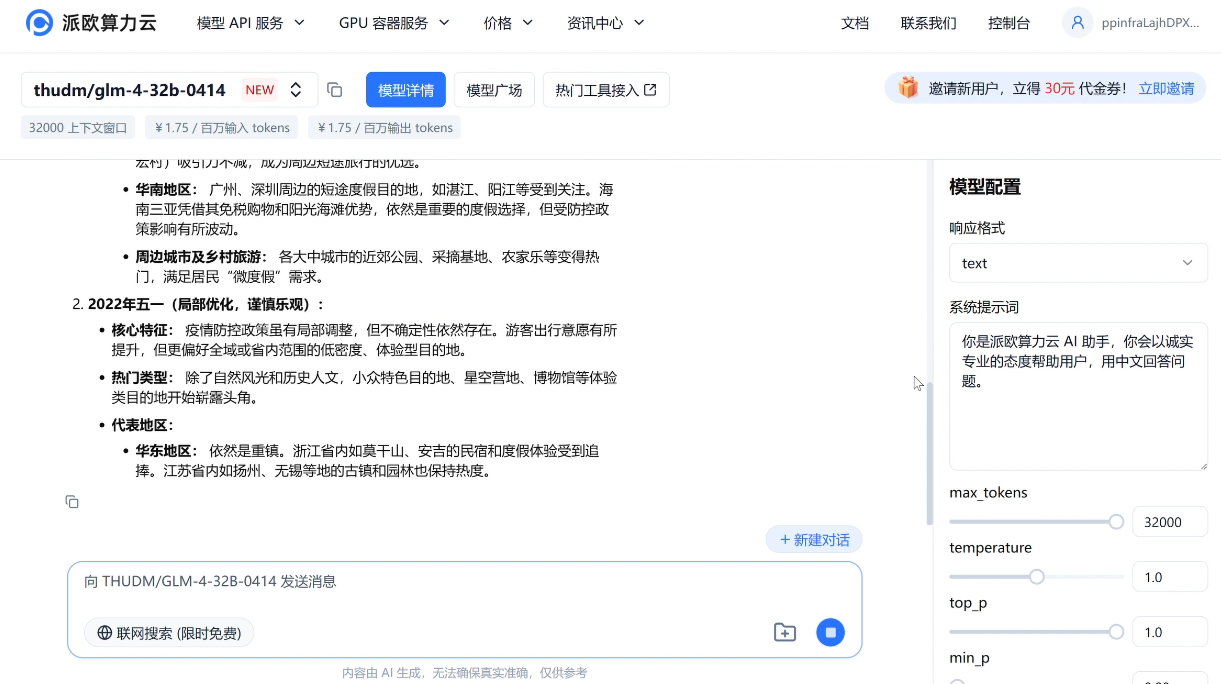
GLM-4-32B-0414 基于 15T 高质量数据预训练,融入推理类合成数据,强化了指令遵循、工程代码生成、函数调用等原子能力。并且,该模型在工程代码、Artifacts 生成、函数调用、搜索问答及报告撰写等任务上均表现出色,部分指标已接近或超越 GPT-4o、DeepSeek-V3 等更大模型水平。
e.g.请分析近三年五一热门出游地,输出包含趋势预测和推荐出游地区的报告文章。
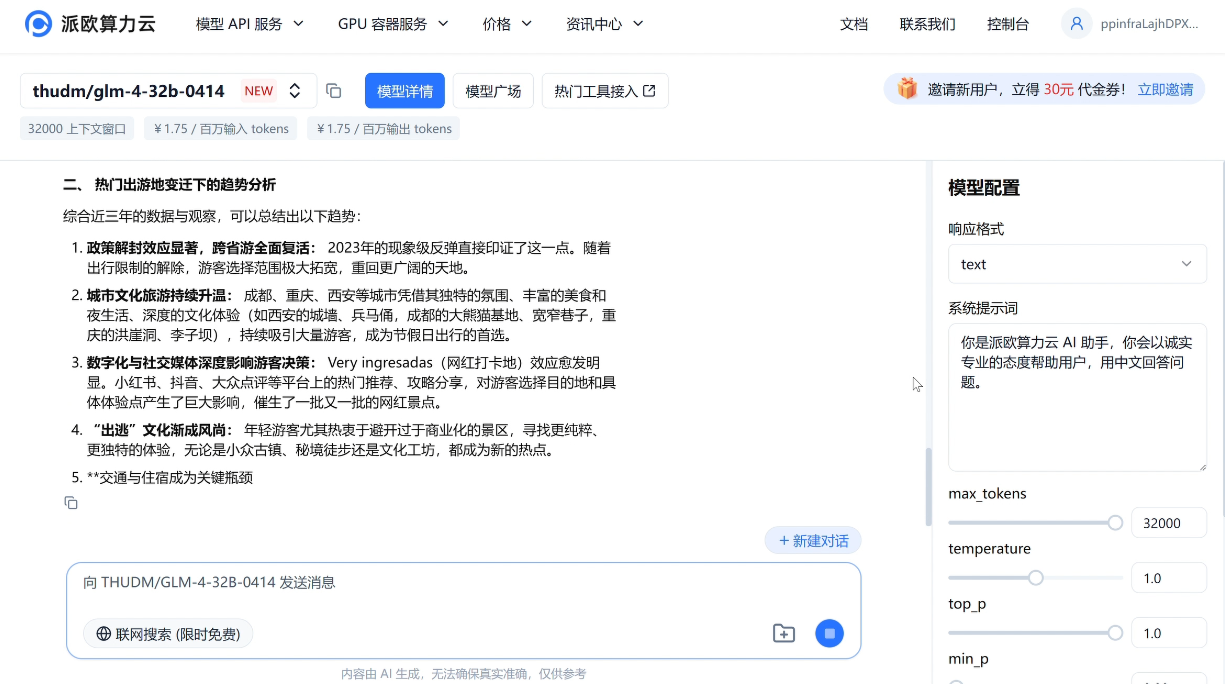
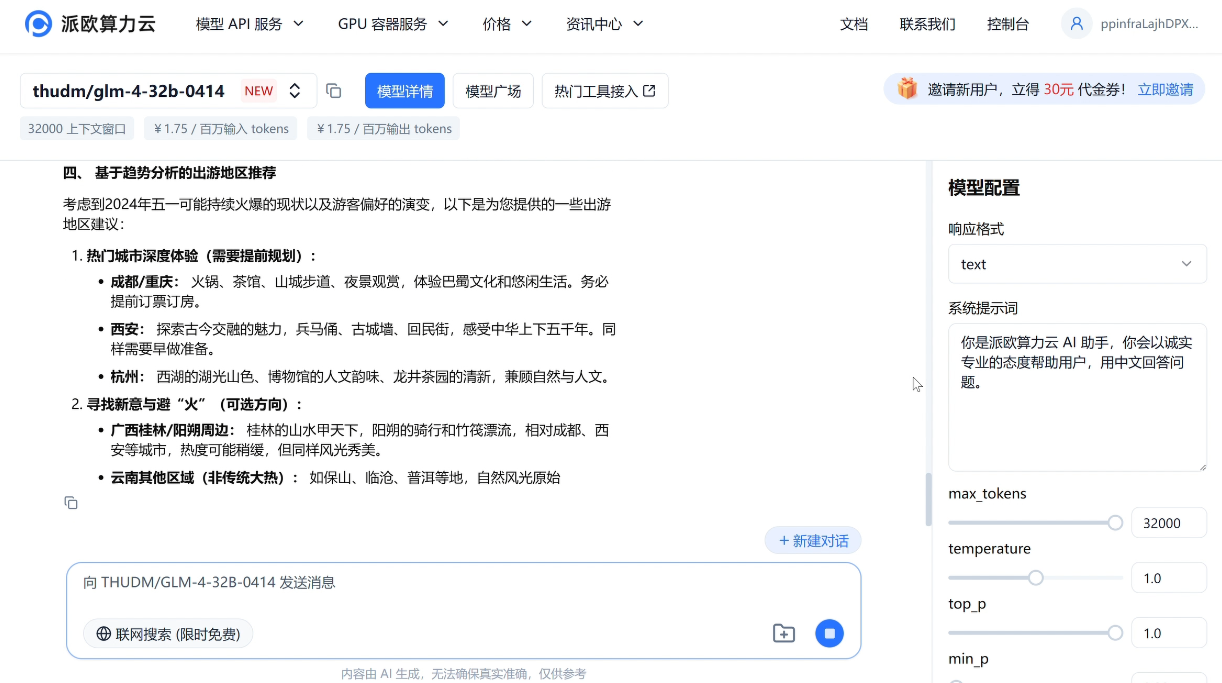
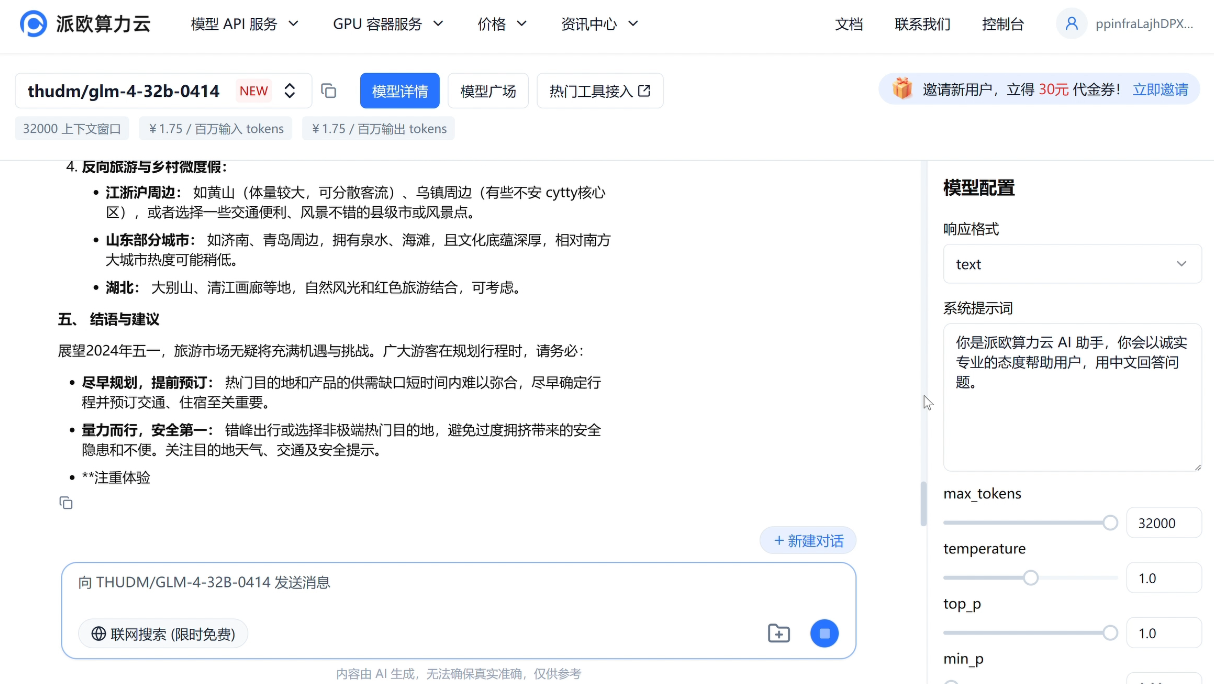
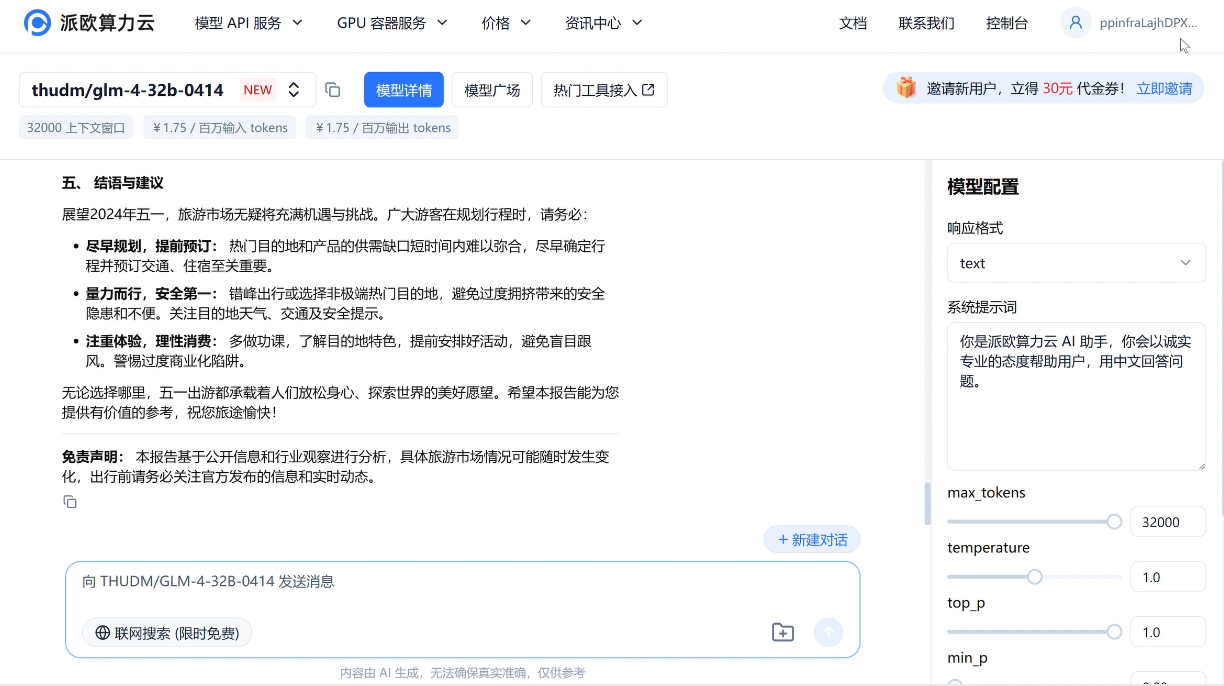
推理模型 GLM-Z1-32B/9B-0414
推理模型 GLM-Z1-0414系列,在基座模型基础上,通过冷启动强化学习,优化数学、代码、逻辑推理能力,显著提升复杂任务解决效率。在部分任务上,GLM-Z1-32B-0414 凭借 32B 参数,性能已能与拥有 671B 参数的 DeepSeek-R1 相媲美。
GLM-Z1-9B-0414 尽管参数更小,但在数学推理及通用任务上依然表现出色,在资源受限的场景下,该模型可以很好地在效率与效果之间取得平衡,为需要轻量化部署的用户提供强有力的选择。
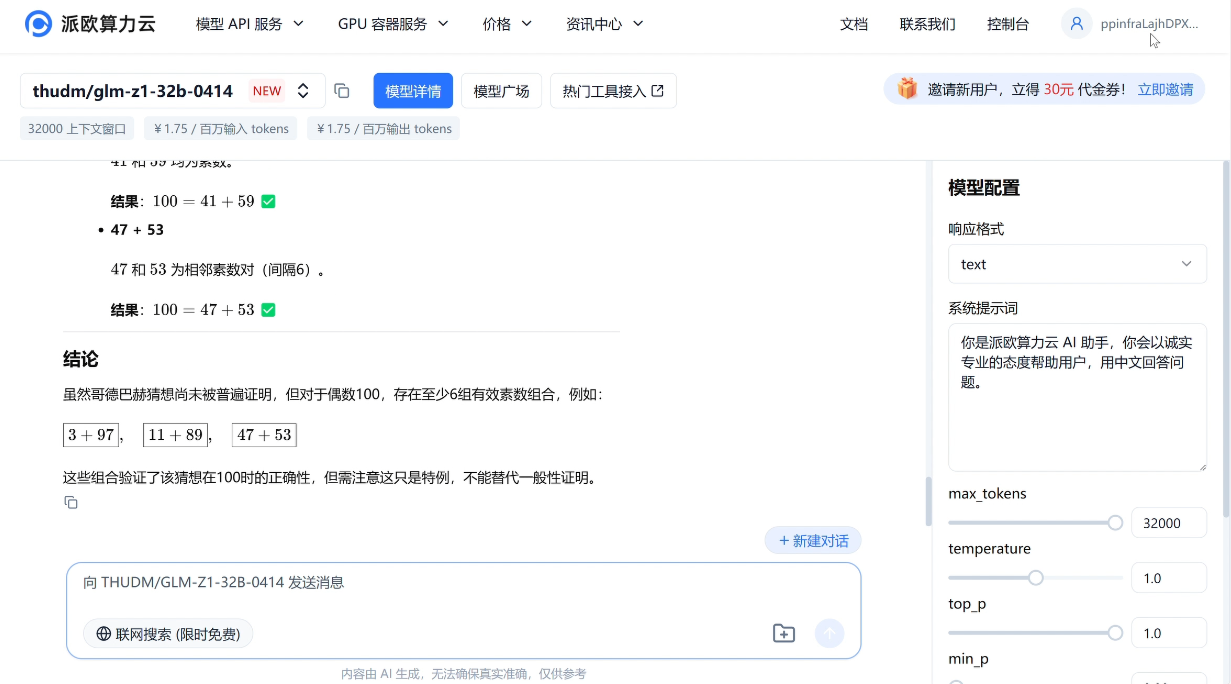
e.g.证明“任一大于 2 的偶数可写成两个素数之和”,并验证当偶数为 100 时的具体素数组合。
沉思模型 GLM-Z1-Rumination-32B-0414
沉思模型 GLM-Z1-Rumination-32B-0414 可通过更多步骤的深度思考来解决高度开放与复杂的问题,并且能在深度思考过程中整合搜索工具处理复杂任务,在研究型写作、复杂检索任务中表现突出。
此外,PPIO派欧云还同步上线 Qwen/Qwen2.5-7B-Instruct,相比 Qwen2,Qwen2.5 知识储备显著提升,并在编程和数学能力上有大幅增强,在指令理解与执行、生成长文本(超过 8K tokens )、理解结构化数据(如表格)、以及生成结构化输出方面表现优秀。
PPIO派欧云致力于为企业及开发者提供高性能的 API 服务,目前已上线 DeepSeek R1/V3 Turbo、Qwen 等系列模型,仅需一行代码即可调用。并且,PPIO 通过 2024 年的实践,已经实现大模型推理的 10 倍 + 降本,实现推理效率与资源使用的动态平衡。
目前,以上模型均已上线 PPIO派欧云官网,thudm/glm-4-9b-0414、thudm/glm-z1-9b-0414、qwen/qwen2.5-7b-instruct 限时免费中,点击以下链接立即体验。
在线体验:https://ppinfra.com/model-api/product/llm-api
API 文档:https://ppinfra.com/docs/model/llm



