
PPIO派欧云假期战报:99.9%可用性!连夜支持满血版DeepSeek,助力客户轻松应对流量高峰

1月28日,PPIO 派欧云首发上线DeepSeek V3,一周内,全量上线 DeepSeek 全系列模型(V3 满血版/R1 满血版/R1 蒸馏模型等),成为首批支持 DeepSeek 全模型商业化API的服务平台,性能直逼官方天花板,告别 “卡顿” 和高昂成本,助力开发者高效开发!
现查看模型列表页即可一键调用,凭借卓越的性能与性价比,上线以来已有超千家开发团队接入!

01 核心优势?稳到发指!
稳定性经得起亿级流量考验
支持春节10倍暴增流量,DeepSeek-V3/R1 服务可用性99.9%,无 TPM 限制,从容应对流量洪峰。
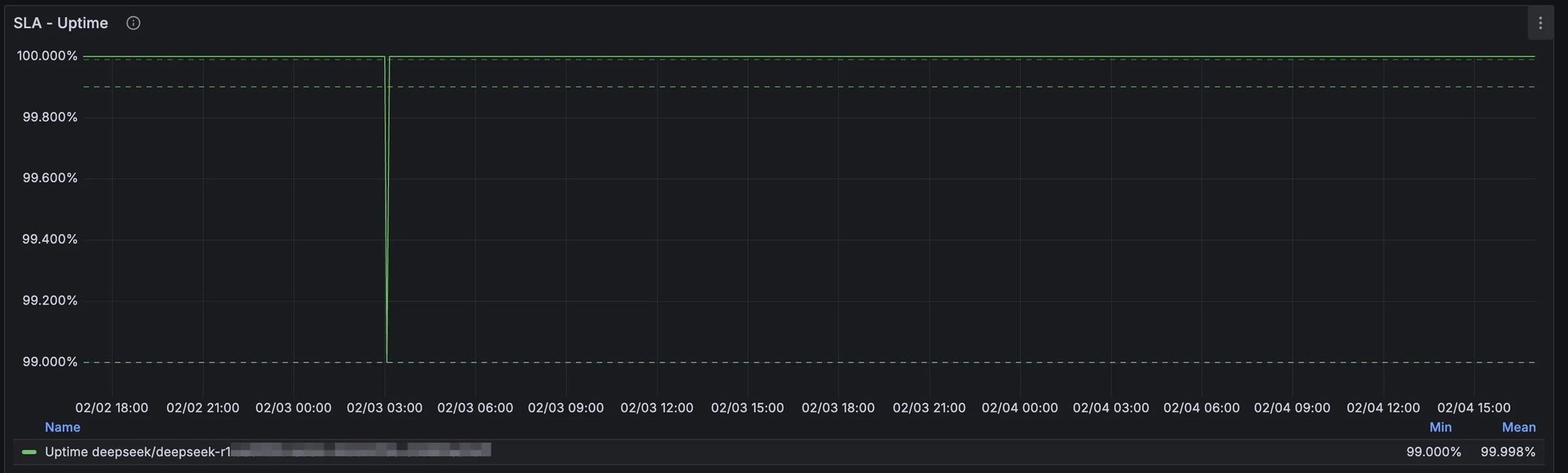
DeepSeek R1 Uptime - 99.99%
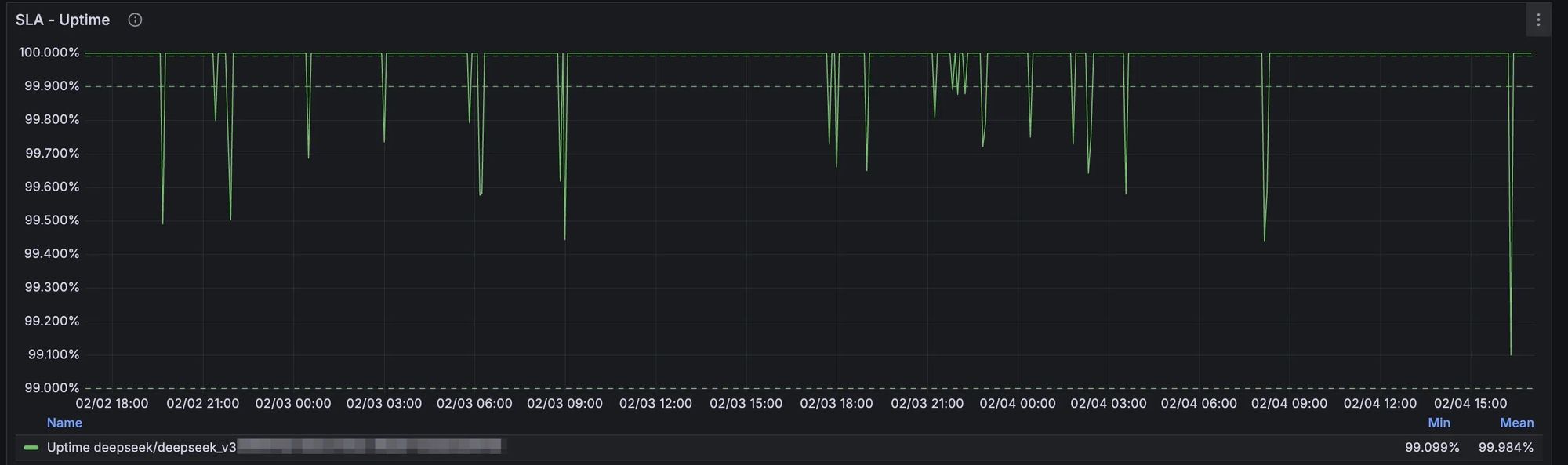
DeepSeek V3 Uptime - 99.98%
价格直击地板,不赚差价
PPIO派欧云致力于普惠开发者低成本使用当前最强开源模型,因此我们的模型定价与DeepSeek官方保持一致!
免去开发者运维成本,只需一行代码,即可快速调用API服务,进行实时调试!
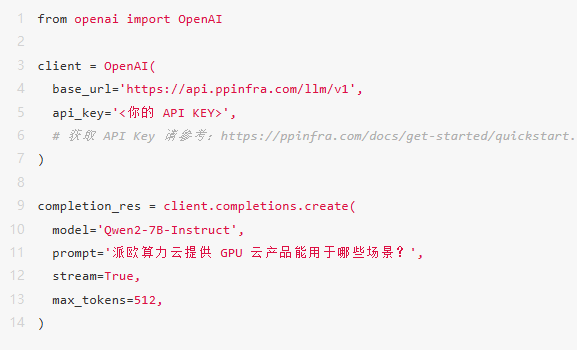
# 获取 API Key 请参考:https://ppinfra.com/docs/get-started/quickstart.html#_2-管理-api-密钥
02 客户实战:春节流量保卫战
01 某用户过亿的健身 APP
客户痛点
春节前夕,客户团队测试发现 DeepSeek 模型效果远超市面方案,但接入官方服务后因 DeepSeek 太火,遭遇延迟波动、扩容受限问题,难以满足业务弹性需求(高峰流量占比60%+)。自建模型需高昂运维成本,中小服务商又难保障稳定性。
解决方案
亿级用户无感扛压
支撑节日单日超 10亿tokens调用,稳定服务不宕机。
24小时紧急上线
春节前完成 DeepSeek V3/R1 模型部署,春节期间24小时加推蒸馏全模型,无缝对接客户产品。
弹性资源分钟级扩容
弹性资源分钟级扩容:深厚的资源储备加持下,基于精细缓存策略和动态调度算法,70B模型10分钟内扩容,8B需求1分钟扩容。
成果反馈
模型高可用性:99.9% uptime
首包延迟优化:降低 25%,超越客户预期
02 某 Top 3 AI浏览器插件
用户需求
需快速接入DeepSeek模型,为百万用户提供一手新鲜且稳定的体验。
抢时间:春节前必须火速上线最新AI功能(接入DeepSeek模型),比竞品快一步
解决方案
24小时极速部署
PPIO派欧云节前就已部署满血版 DeepSeek V3 和 R1 模型,客户发现后1天内就完成接入,24 小时内同步上线蒸馏版模型。
资源“智慧弹性”
弹性调度策略,在春节期间百万用户的高峰流量下,从容应对高并发请求。
全程保镖护航
工程师团队春节值班保障,系统稳定性行业领先。
成果反馈
用户体验稳定有保障:99.9% 服务可用性,为用户体验保驾护航
赚钱能力暴涨:新功能带动付费用户增长10%,春节档多赚百万级
03 创业者专属大礼包
PPIO派欧云致力于大幅降低 AI 基础设施的使用成本和门槛,将前沿技术的力量带给每一位创新者。
01 初创企业扶持计划
立即申请我们的【初创企业扶持计划】,最高可享¥10万额度补贴,特别为 DeepSeek 用户加码20%专属优惠。这不是简单的扶持,而是给创新者的火箭推进器!
02 开发者专属彩蛋
新用户注册即赠百万级tokens体验券!



