
PPIO独家上新GPU实例模板,一键部署Kimi-Linear

昨晚,月之暗面发布了混合线性注意力架构新模型 Kimi-Linear,旨在解决大语言模型在长上下文推理中的计算瓶颈。
Kimi-Linear 的核心亮点:
- Kimi Delta Attention(KDA),一种通过细粒度门控机制改进门控规则的线性注意力架构。
- 混合架构:采用 3:1 的 KDA 与全局 MLA 比例,在保持甚至超越全注意力质量的同时降低内存占用。
- 卓越性能:在 1.4T Token 的训练规模下,经公平对比,KDA 在长文本与类强化学习基准等多项任务上均优于全注意力。
- 高吞吐:在 1M 上下文中实现最高 6 倍的解码吞吐量,显著缩短单输出 Token 耗时(TPOT)。
今天,PPIO 独家上新 GPU 实例模板,可一键部署 Kimi-Linear-48B-A3B-Instruct 的专属模型。
PPIO 算力市场的 GPU 实例模板是将大语言模型进行私有化部署的模板,方便企业及个人开发者降低模型部署成本,实现高效、安全调用。
在线体验:
https://ppio.com/gpu-instance/console/explore
# 01
PPIO GPU 私有化部署模板
一键部署 Kimi-Linear
Step 1: 在 PPIO 算力市场的子模版市场选择 Kimi-Linear 的对应模板,并使用此模板。
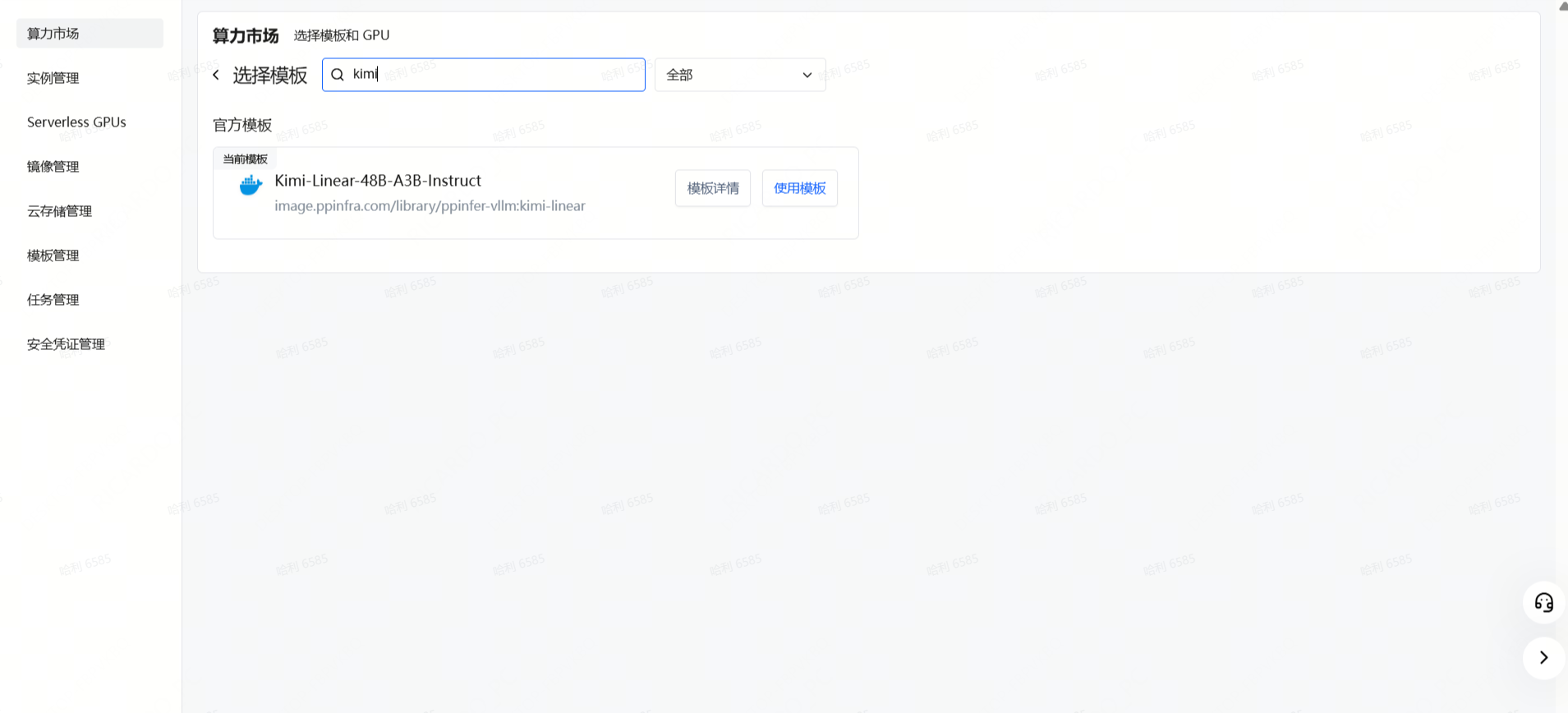
Step 2: 按照所需配置点击部署。

Step 3: 检查磁盘大小、计费方式等信息,确认无误后点击下一步。
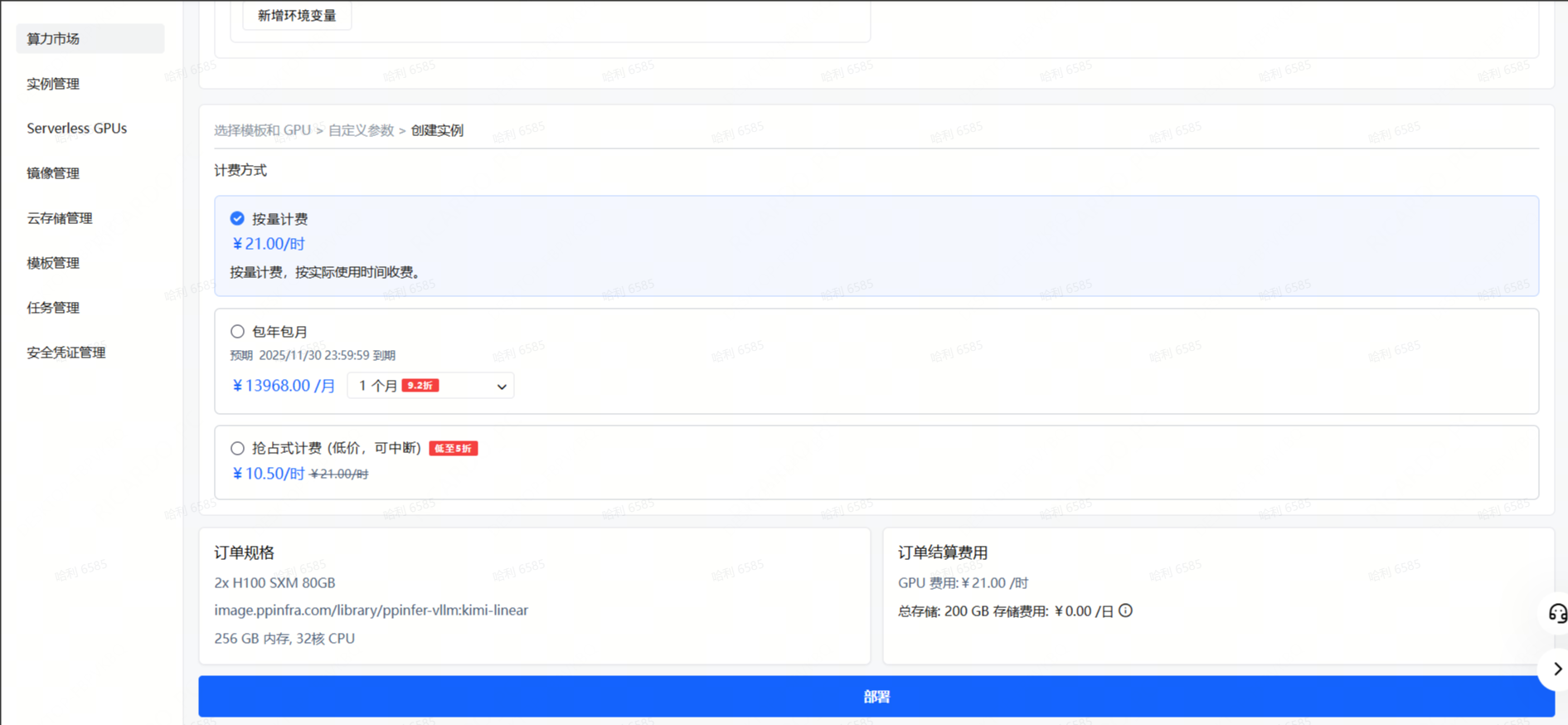
Step 4: 稍等一会,实例创建需要一些时间。
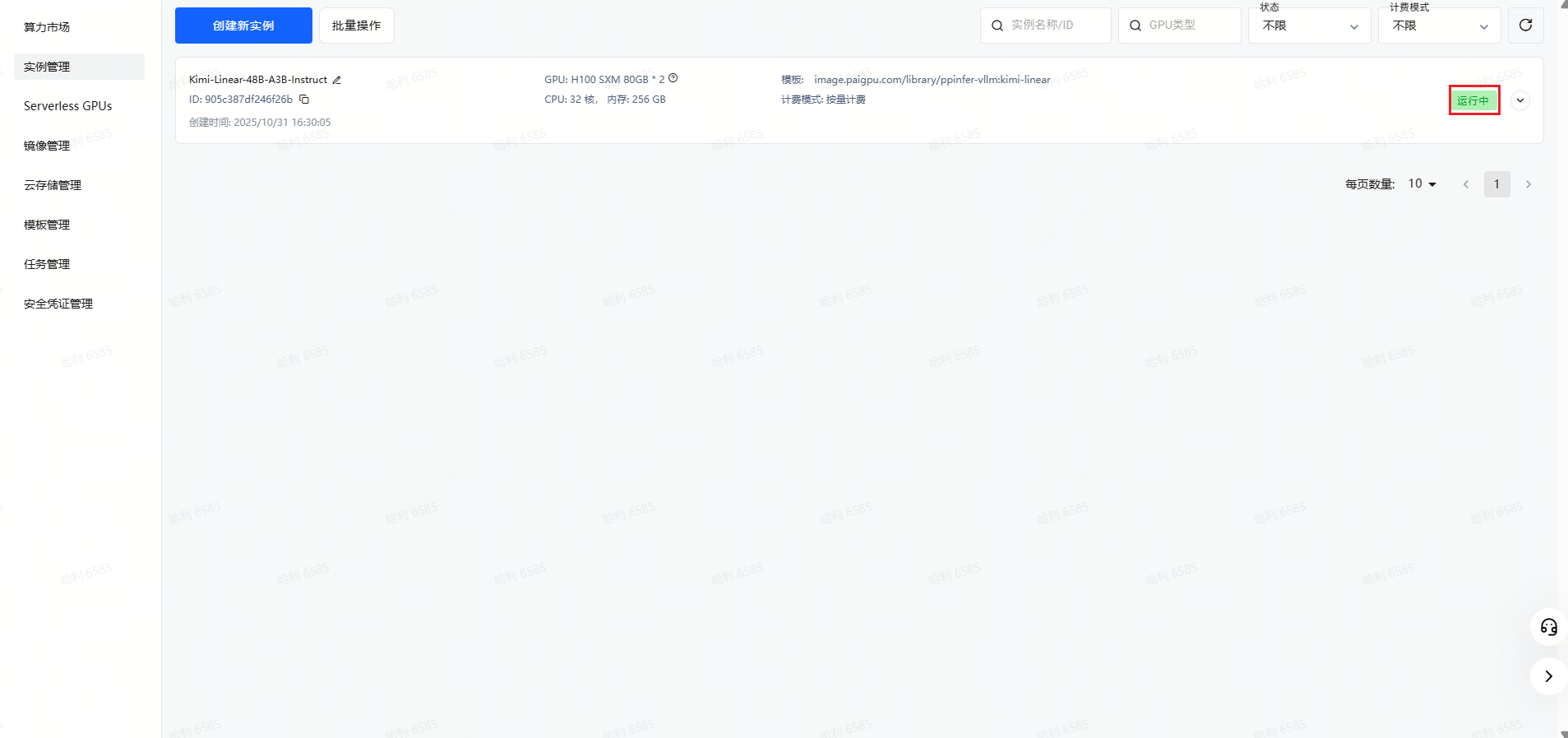
Step 5: 在实例管理里可以查看到所创建的实例。
Step 6: 查看实例日志,确保服务正常启动。
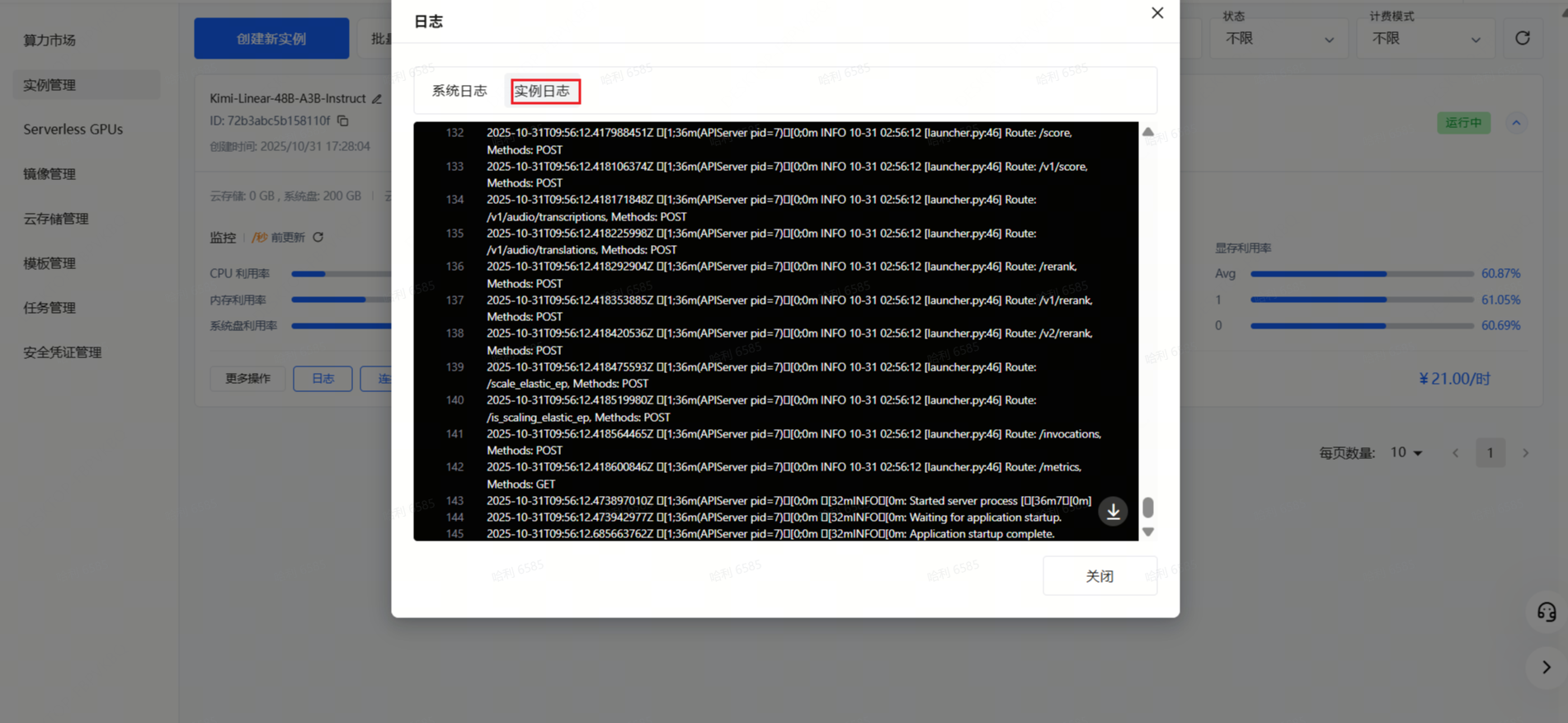
Step 7: 点击启动 Web Terminal 选项,启动后点击连接选项即可连接到网页终端。

# 02
如何使用?
访问您的私有模型,注意请将下文中的
“http://127.0.0.1:8080” 替换为您真正的访问地址,复制以下代码,访问您的私有模型!

curl --request POST \
--url http://127.0.0.1:8080/v1/chat/completions \
--header "Authorization: Bearer " \
--header "Content-Type: application/json" \
--data '{
"model": "moonshotai/Kimi-Linear-48B-A3B-Instruct",
"messages": [
{"role": "user", "content":"who are you?"}
],
"max_tokens": 128
}'
{"id":"chatcmpl-de7c4de865e94699b80eb1a0d0bc9f22","object":"chat.completion","created":1761904682,"model":"moonshotai/Kimi-Linear-48B-A3B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"I'm Kimi, a large language model trained by Moonshot AI. I'm here to help you with any questions or tasks you have. How can I assist you today?","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning_content":null},"logprobs":null,"finish_reason":"stop","stop_reason":163586,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":11,"total_tokens":46,"completion_tokens":35,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
将 API 地址配置到您的 Cherry Studio 等应用,就可以拥有专属模型及聊天助手!
目前,PPIO 算力市场已上线几十个私有化部署模板,除了 Kimi-Linear,你可以将 DeepSeek-R1-Distill-Qwen-1.5B、StableDiffusion:v1.10、PaddleOCR-VL 等模型快速进行私有化部署。
如果你有企业级 Model API 需求,可扫下方二维码获取报价与权益说明。




