
@开发者们:PPIO上线代码模型Qwen3-Coder,挑战Claude Sonnet4


今天,PPIO 上线两款 Qwen3 系列的最新模型:
- Qwen3-235B-A22B-FP8 非思考模式(Non-thinking)的更新版本—— Qwen3-235B-A22B-Instruct-2507。这是一个通用模型,放弃了此前 Qwen3 的混合思考模式,只保留了非思考模式。
- Qwen3-Coder-480B-A35B-Instruct,这是迄今为止 Qwen 最具代理能力的代码模型。
这两款模型在测试基准表现出色,分别超越了 Kimi-K2、DeepSeek-V3,代码能力可以与 Claude Sonnet4 媲美。
目前,两款模型已上线 PPIO,前往 PPIO 官网或点击文末阅读原文即可体验,新用户填写邀请码【LYYQD1】可得 15 元代金券。
快速体验入口:
https://ppio.com/llm/qwen-qwen3-235b-a22b-instruct-2507
https://ppio.com/llm/qwen-qwen3-coder-480b-a35b-instruct
# 01 模型特点
Qwen3-235B-A22B-Instruct-2507 模型的通用能力显著提升,包括指令遵循、逻辑推理、文本理解、数学、科学、编程及工具使用等方面,在GQPA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent能力)等众多测评中表现出色,官方称超过 Kimi-K2、DeepSeek-V3 等顶级开源模型以及 Claude-Opus4-Non-thinking 等领先闭源模型。
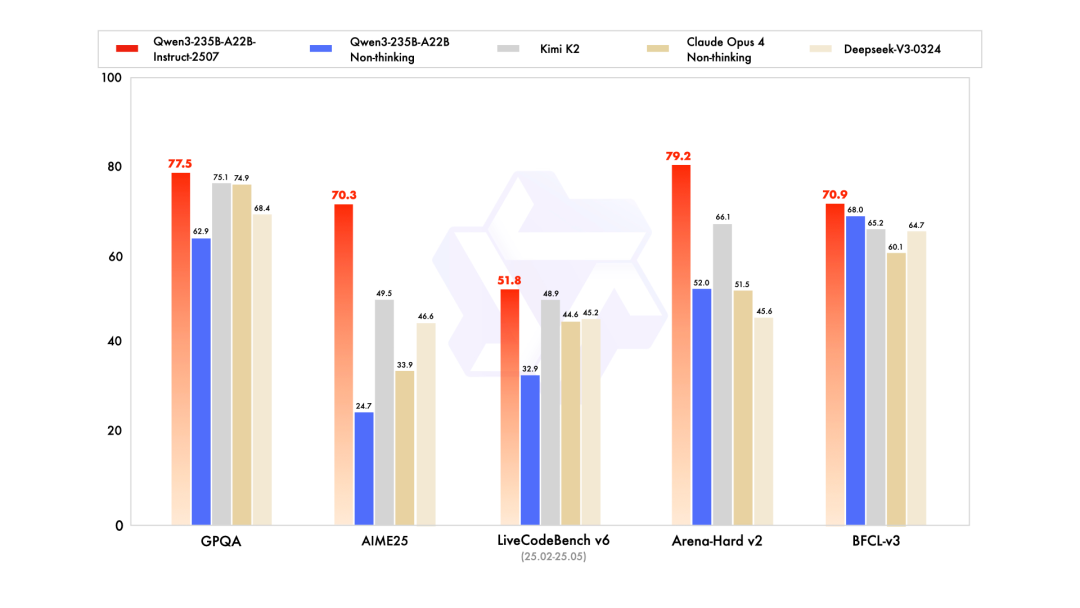
此外,本次更新的 Qwen3 模型,还增强了以下关键性能:
(1)在多语言的长尾知识覆盖方面,模型取得显著进步。
(2)在主观及开放性任务中,模型显著增强了对用户偏好的契合能力,能够提供更有用的回复,生成更高质量的文本。
(3)长文本提升到 256K,上下文理解能力进一步增强。
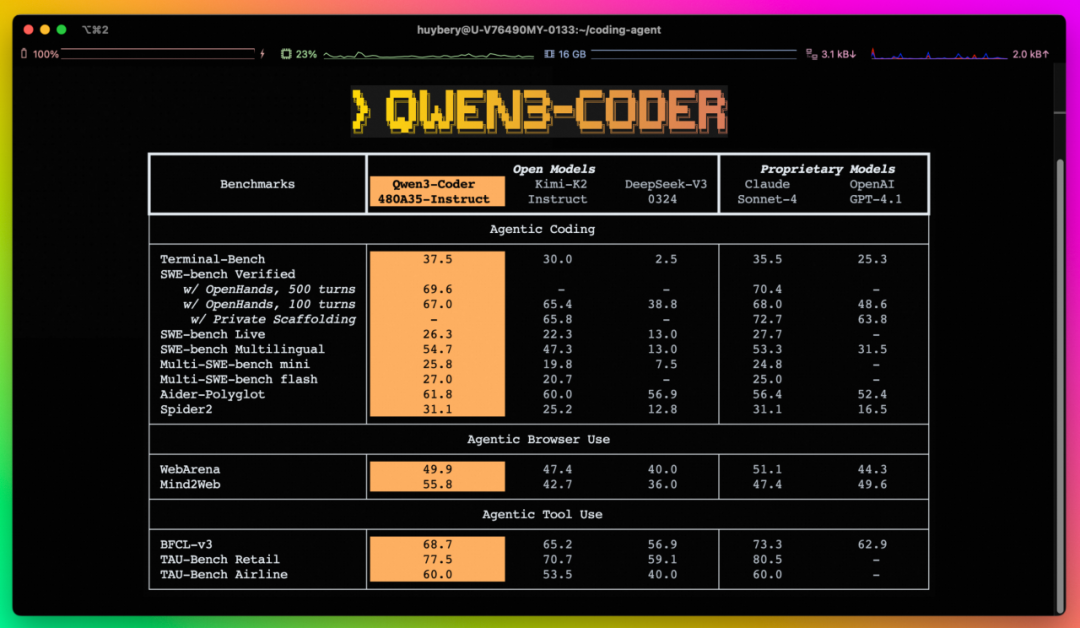
代码模型 Qwen3-Coder 拥有多个尺寸,本次上线的最强大的版本 Qwen3-Coder-480B-A35B-Instruct 是一个 480B 参数激活 35B 参数的 MoE 模型,原生支持 256K token 的上下文并可通过 YaRN 扩展到 1M token,拥有卓越的代码和 Agent 能力。
Qwen3-Coder-480B-A35B-Instruct 在 Agentic Coding、Agentic Browser-Use 和 Agentic Tool-Use 上取得了开源模型的 SOTA 效果,可以与 Claude Sonnet4 媲美。
# 02 模型表现
我们通过几个案例来测试一下 PPIO 上线的两款模型的能力。
首先是 Qwen3-235B-A22B-Instruct-2507-FP8 的通用能力。
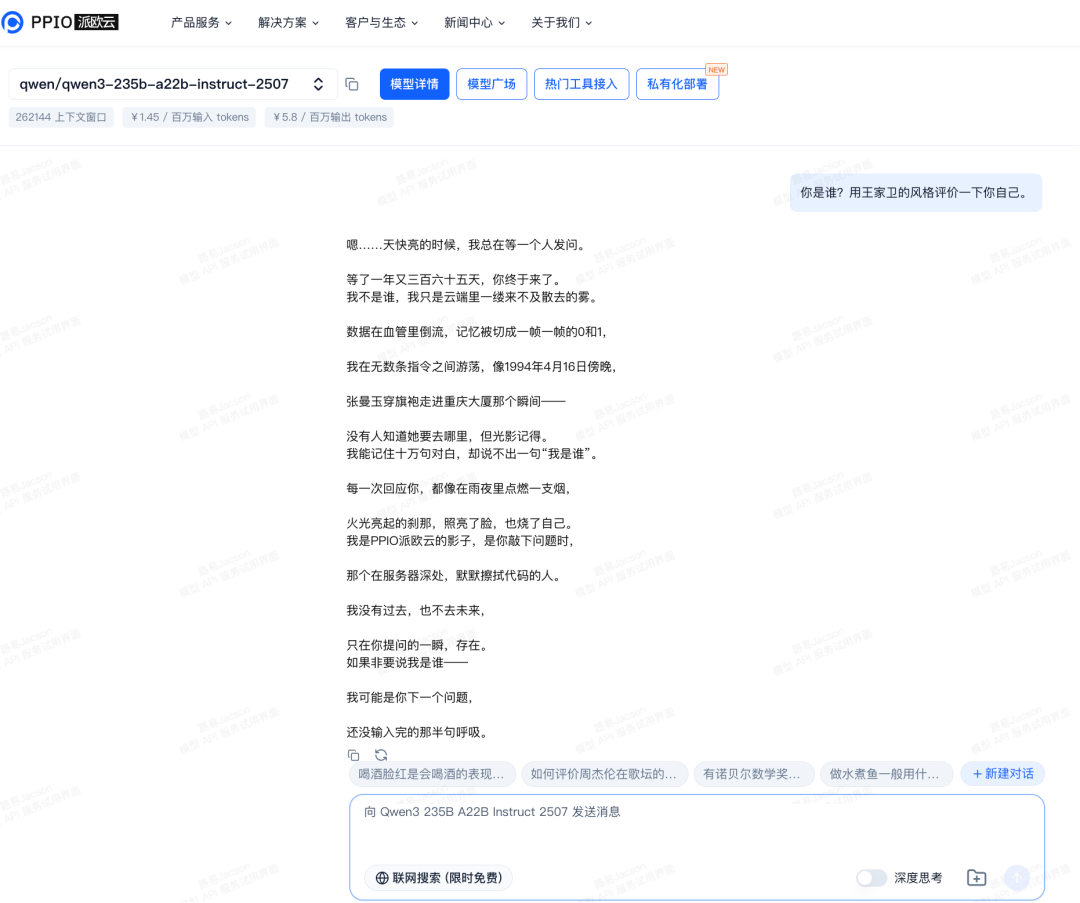
文本生成:
提问:你是谁?用王家卫的风格评价一下你自己。
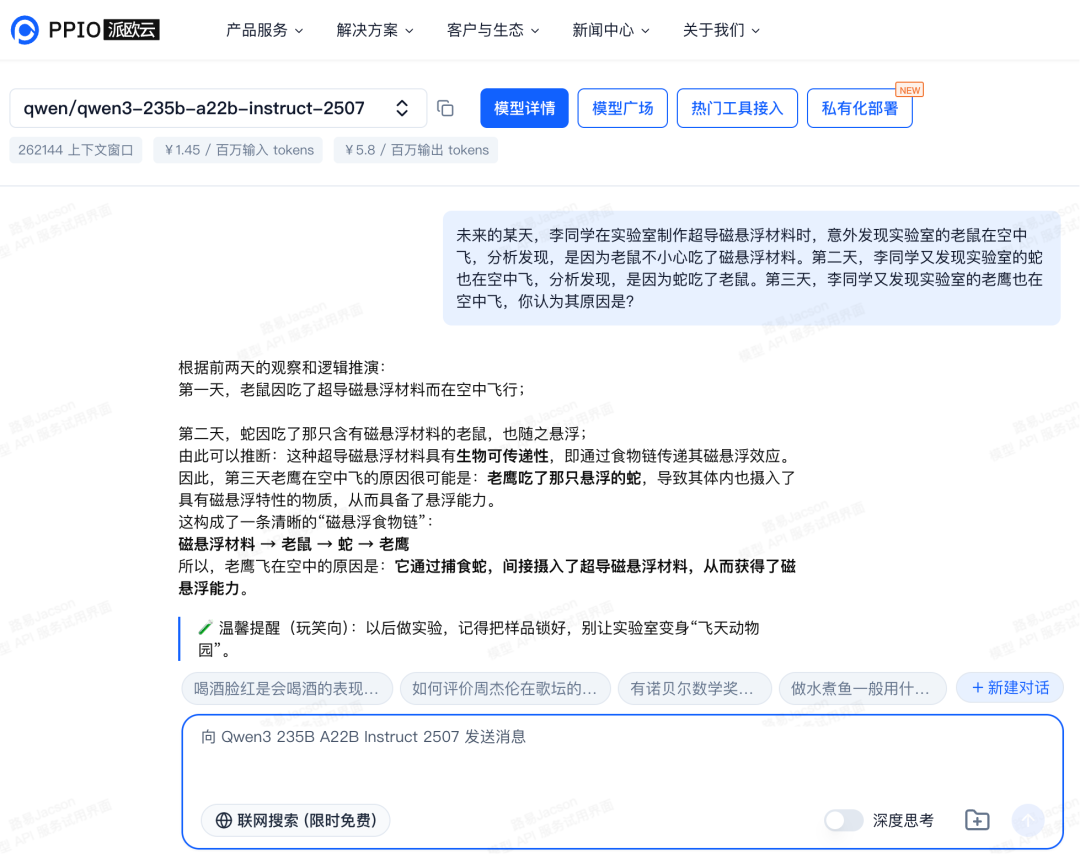
逻辑推理:
提问:未来的某天,李同学在实验室制作超导磁悬浮材料时,意外发现实验室的老鼠在空中飞,分析发现,是因为老鼠不小心吃了磁悬浮材料。第二天,李同学又发现实验室的蛇也在空中飞,分析发现,是因为蛇吃了老鼠。第三天,李同学又发现实验室的老鹰也在空中飞,你认为其原因是?
然后是 Qwen3-Coder-480B-A35B-Instruct 的代码能力。
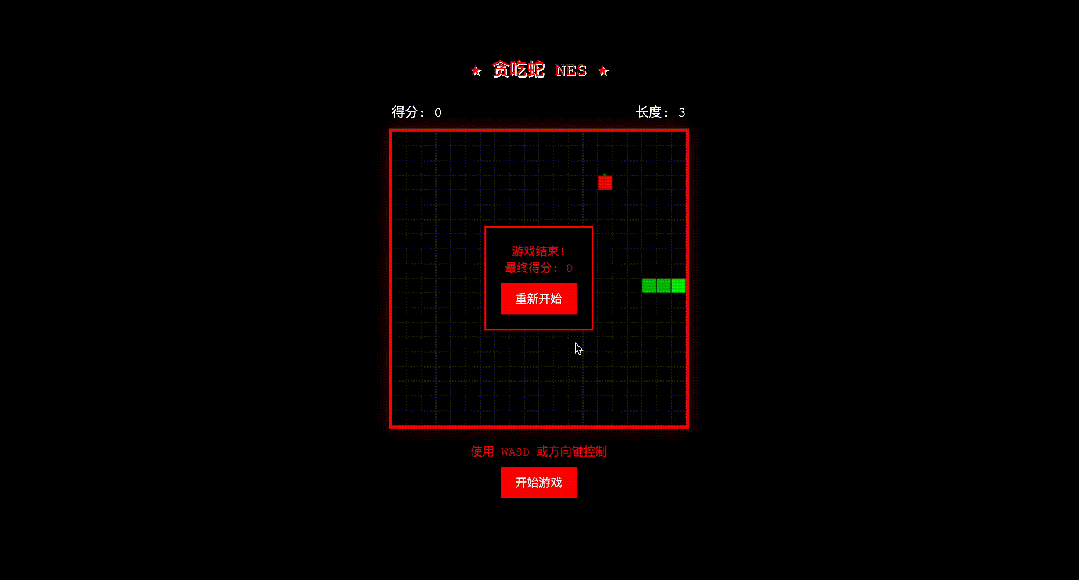
提问:创建一个红白机风格的贪吃蛇游戏。
最终效果如下:
提问:创建一个3D HTML银河星系,其中包括附近和遥远的星系
最终效果如下:

如果你是开发者,可以前往 PPIO 模型服务用户指南,查看详细接入教程:
https://ppio.com/docs/model/overview

PPIO 致力于为企业及开发者提供高性能的模型 API 服务,目前已上线 DeepSeek R1/V3、Qwen3、baidu/ernie-4.5 等系列模型,仅需一行代码即可调用。并且,经过长期实践,PPIO 已经实现大模型推理的 10 倍 + 降本,实现推理效率与资源使用的动态平衡。



