
高主频CPU+RTX4090:AI生图性能优化超150%

在 AI 图像生成过程中,CPU 与 GPU 的协同效应对系统的整体性能至关重要。
测试表明,与 RTX 4090 显卡搭配使用时,相较于核心数量,CPU 主频对性能的影响更为显著。这颠覆了传统认知中对多核企业级处理器的推崇,也证明了高主频消费级 CPU 不仅能大幅提升生成速度,还可以有效降低硬件成本。
CPU 主频对图像生成速度的影响
在文生图过程中,CPU 为 GPU 预处理数据。更高的 CPU 主频可以加速指令集的准备和传输效率,使得 GPU 无需等待便可保持满载运行。测试显示,相比于低频企业级 CPU,高频消费级 CPU 可将 GPU 的利用率提升 150% 以上。
测试框架:
在 ComfyUI上运行Stable Diffusion 1.8.0,测试NVIDIA RTX 4090 (24GB显存) 搭配多款 CPU 配置。
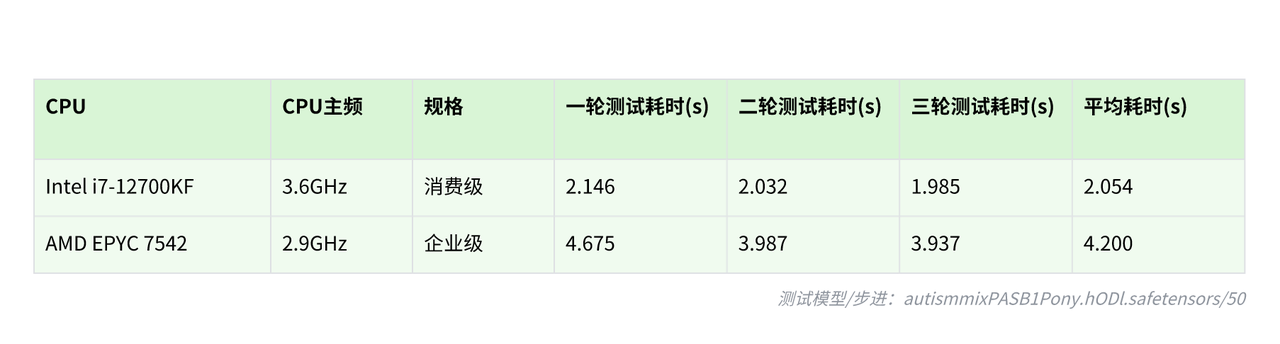
不同主频 CPU 配置下的生图速度对比:
不同主频 CPU+ 单卡 RTX 4090 生成单张图片的耗时对比:
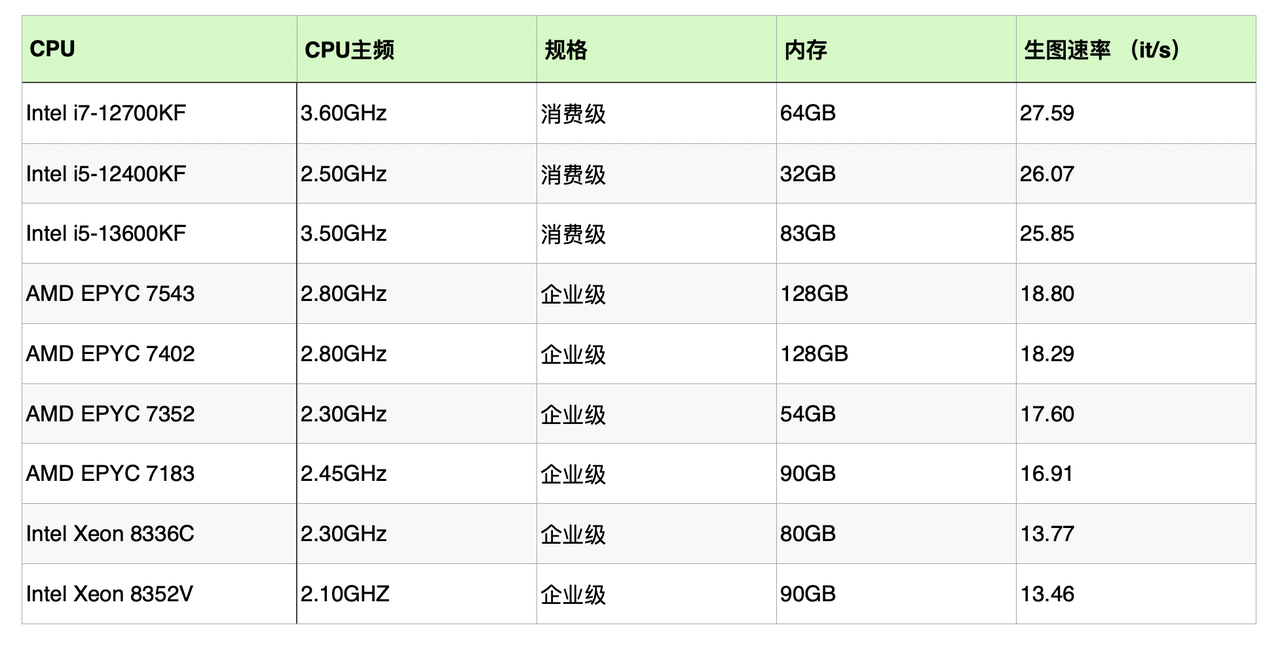
不同主频 CPU+ 单卡 RTX 4090 每秒的生成效率对比:
核心发现:
消费级高主频 CPU 完成相同任务所需时间仅为企业级 CPU 一半左右,性能提升幅度超过 150%。
ComfyUI 设置优化对图像生成速度的影响
验证高主频 CPU 的优势之后,我们来进一步探索提升图像生成速度的方法。
测试框架:
在高主频 CPU( 13th Gen Intel(R) Core(TM) i7-13790F )搭配 RTX 4090 显卡的系统上,在 ComfyUI 上运行 Flux1.dev fp8 模型。
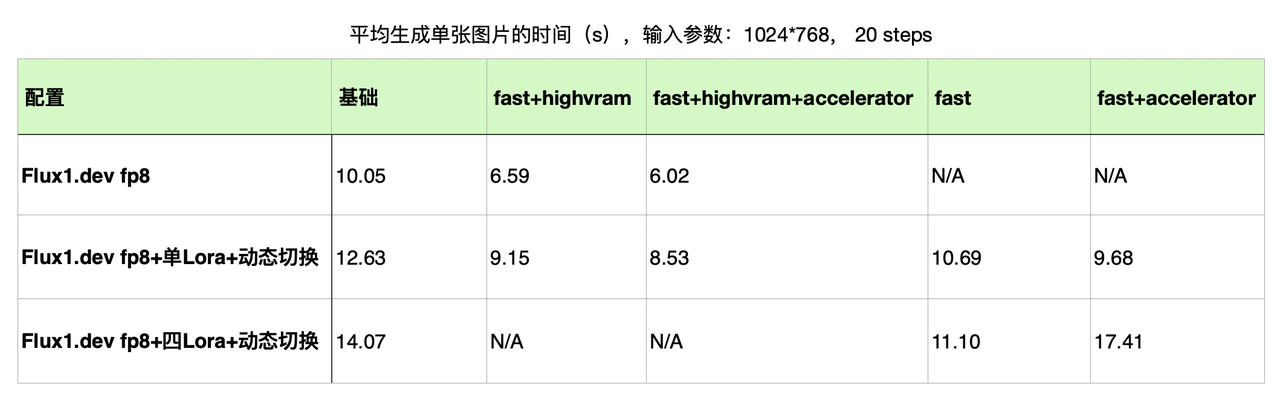
不同 ComfyUI 设置下的生图速度对比:
ComfyUI 功能解析:
Fast:通过预加载和缓存机制来加速这些资源的加载。减少非必要的检查并优化资源加载,使启动时间更短,同时在重复生成图像时提升整体效率。在图像生成过程中 ComfyUI 会执行一些预处理步骤,如图像转换、数据验证等。
HighVRAM:更多的模型和数据会常驻在 GPU VRAM 中,减少数据传输开销。同时优化内存管理,避免频繁的内存分配和释放操作,从而提升生成效率。还具有多 batch 处理的能力(在显存足够大的情况下)。
Accelerator:ComfyUI 中的自定义节点(插件),帮助提升处理流水线效率。
核心发现:
在 RTX 4090 显卡搭配高频 CPU 配置下,通过优化 ComfyUI 的设置,在保持图像质量的前提下实现显著性能提升:
基础模型工作流:采用 flux.dev-fp8 配合 Fast 模式和 HighVRAM 模型,生成时间从 10.05s 降至 6.02s。
单 Lora 切换工作流:flux.dev-fp8 配合 Fast 模式和 Accelerator 插件,生成时间从 12.63s 缩短至 9.68s。
四 Lora 切换工作流:flux.dev-fp8 配合 Fast 模式,生成时间从 14.07s 优化至 11.10s。
需要强调的是,Fast 与 HighVRAM 虽然对于提升生图速度效果明显,但也会导致生图质量略有下降。同时,由于在 Lora 模式下对于显存有更高要求,而 HighVRAM 需要更大显存,容易导致 OOM (内存溢出)甚至崩溃。所以,实际使用时要平衡生图速度与生图质量。
如何在 PPIO派欧云获取图像生成友好型 GPU
对于以上发现,PPIO 提供搭载最优硬件组合的预配置实例,下面为具体获取步骤:
1. 登录派欧算力云官网,点击【控制台】
地址为:https://ppinfra.com/
2. 进入【 GPU 容器实例】页面
地址为:https://ppinfra.com/gpu-instance/console/explore
3. 选择合适的 GPU 模板:
- StableDiffusion:v1.8.0 ——适用于 Stable Diffusion 模型优化
4. 右下角选择【24CPU/卡】,【一键部署】RTX 4090(高频 CPU )
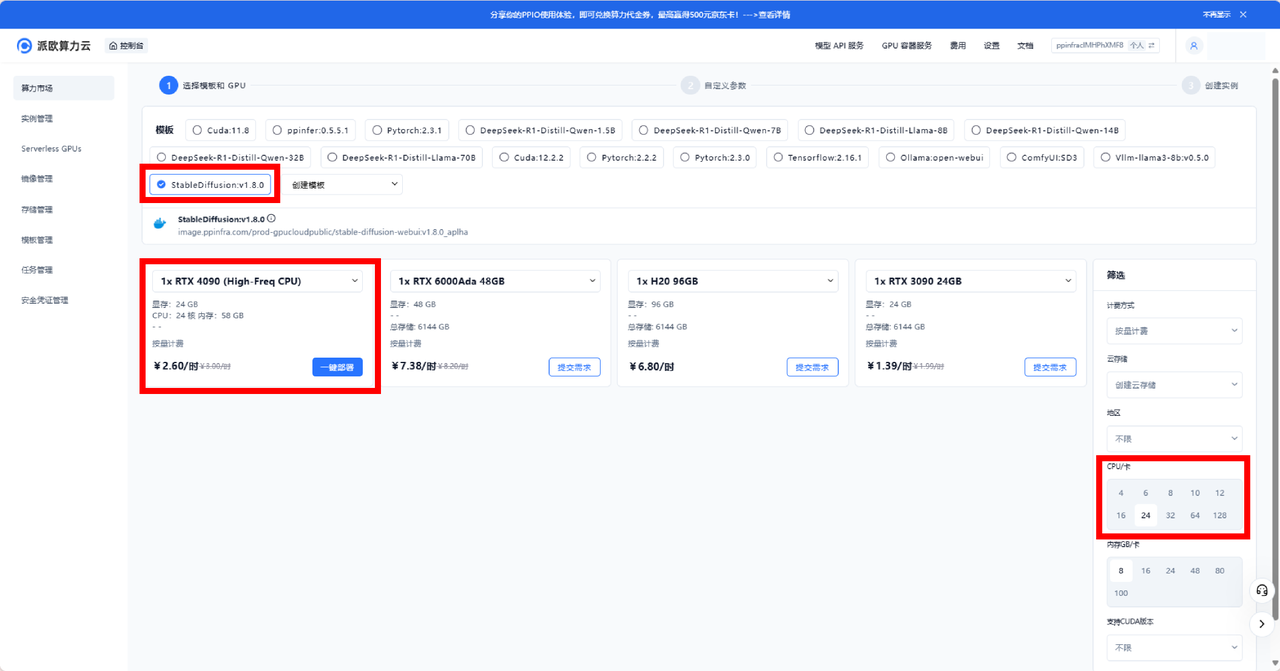
技术规格
GPU:1× NVIDIA RTX 4090( 24GB 显存)
CPU:13 代酷睿 i7-13790F 高频处理器
系统内存:58GB RAM
处理核心:24vCPU
成本效益:2.6 元/小时(按需计费)
结论
研究证实,在 AI 图像生成场景中,相较于低频企业级 CPU,高频消费级 CPU 搭配 RTX 4090 显卡可实现 150% 的性能飞跃,同时显著降低硬件成本。
结合本文所述的 ComfyUI 优化,用户可进一步提高生成的速度、增加吞吐量。升级至 RTX 4090 显卡搭配高频 CPU,即刻获得生成速度与输出质量的双重提升,革新您的 AI 图像生成工作流。



