
DeepSeek推出DeepEP:首个开源EP通信库,让MoE模型训练与推理起飞!

今天,DeepSeek 在继 FlashMLA 之后,推出了第二个 OpenSourceWeek 开源项目——DeepEP。
作为首个专为 MoE(Mixture-of-Experts)训练与推理设计的开源 EP 通信库,DeepEP 在 EP(Expert Parallelism)领域迈出了重要一步,旨在为 MoE 模型提供低时延、高带宽、高吞吐的卡间和节点间通信能力。
根据测试结果,DeepEP 在节点内部的多卡通信中表现接近带宽上限,同时节点间通信效率也显著提升。
什么是EP?
在深入了解 DeepEP 之前,我们需要先理解什么是 EP。
EP 是一种专为 MoE 设计的分布式计算方法。而 MoE 是一种基于 Transformer 的模型架构,采用稀疏策略,使其相比传统的密集模型在训练时更加轻量化。
在这种 MoE 神经网络架构中,每次仅使用模型中部分组件(称为“专家”)来处理输入。
这种方法具有多项优势,包括更高效的训练、更快的推理速度,即使模型规模更大依然如此。
换句话说,在相同的计算资源预算下,与训练一个完整的密集模型相比,MoE 可以支持更大的模型或更大的数据集。
MoE 模型通过动态路由机制将输入分配到不同的专家子网络(Expert Sub-network),而 EP 则将这些专家子网络分配到多个计算设备上,从而显著提升大规模模型的计算效率。
四大主流分布式并行策略
目前,主流的分布式并行策略主要包括以下四种。
Data Parallelism (DP)
- 核心:复制模型副本,分割输入数据。
- 优势:实现简单,计算负载均衡。
- 限制:显存占用高,不适用于超大规模模型。
Tensor Parallelism (TP)
- 核心:矩阵维度切割,分布式存储参数。
- 优势:突破单卡显存限制。
- 限制:通信密集,需要高速互联。
Pipeline Parallelism (PP)
- 核心:模型分层流水作业。
- 优势:支持千亿级参数部署。
- 限制:存在计算间隙(流水线气泡)。
Expert Parallelism (EP)
- 核心:支持大参数的MoE模型高效推理和训练。
- 优势:有更好的模型切分灵活性,更加细粒度。
- 限制:只能在MoE模型上使用。
EP如何加速MoE模型推理?
EP 在大语言模型推理加速中的重要性源于其对 MoE 的高效切分能力。
当模型采用 MoE 结构且专家数量达到数百量级(如 320 个专家)时,EP 可将不同专家分配到独立计算节点,其并行粒度与专家数量直接匹配。
相比之下,TP 依赖 Attention 层的多头机制切分(例如典型 32 头配置),在扩展到 64 卡及以上规模时,因切分维度不足(32 < 64)难以充分利用硬件资源。
EP 通过专家维度的切分,TP一般按照 Attention Heads 的维度进行切分,切分出的数量只能是32的约数,使得超大规模集群(如 64+ 卡)的负载分配更均衡,从而实现更优的推理吞吐量。
DeepEP:专为 MoE 与 EP 定制的通信库
DeepEP 是一款专为 MoE 和 EP 定制的通信库,具备以下核心优势:
- 高效优化的 All-to-All 通信
DeepEP 提供了高效的 All-to-All 通信内核,能够显著减少数据传输的瓶颈,确保在分布式环境中不同专家之间的信息交换更加顺畅。
DeepEP 支持 NVLink 和 RDMA 技术,能够实现节点内和跨节点的高效通信。NVLink 提供了高达 160 GB/s 的带宽,而 RDMA 则支持跨节点的低延迟数据传输,满足大规模分布式训练的需求。
- 高吞吐量计算核心
针对训练和推理预填充阶段,DeepEP 提供了高吞吐量的计算核心,确保在大规模数据处理时能够保持高效的计算性能。
- 低延迟计算核心
对于推理解码阶段,DeepEP 提供了基于 RDMA / Infiniband 的低延迟计算核心,最大限度地减少了推理延迟,适合对延迟敏感的应用场景。
- 原生支持 FP8 数据分发
DeepEP 原生支持 FP8 数据分发,能够在保持精度的同时减少数据传输量,进一步提升了通信效率。
- 灵活控制 GPU 资源
DeepEP 提供了灵活的 GPU 资源调度机制,能够实现计算与通信的高效重叠,避免资源浪费,提升整体性能。
DeepEP的性能表现
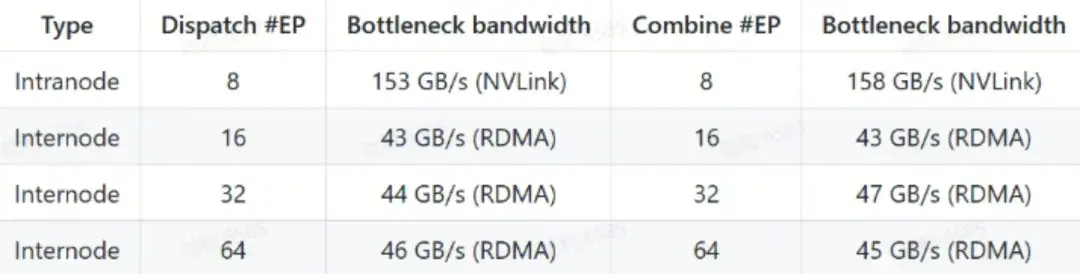
DeepEP 在节点内和跨节点通信中的性能表现显著,尤其在 NVLink 和 RDMA 混合架构下展现出高效的数据传输能力。DeepEP 在两种典型场景下的性能测试结果:
常规内核性能(NVLink 和 RDMA 转发)
- 测试环境:
- GPU:H800(NVLink 最大带宽约 160 GB/s)
- 网络:CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)
- 配置:遵循 DeepSeek-V3/R1 预训练设置(每批次 4096 tokens,隐藏层 7168,top-4 组,top-8 专家,FP8 分发和 BF16 聚合)
- 性能数据:
- 节点内通信接近 NVLink 最大带宽(160 GB/s),表现出极高的数据传输效率。
- 跨节点通信在 RDMA 网络下保持稳定带宽,满足大规模分布式训练需求。
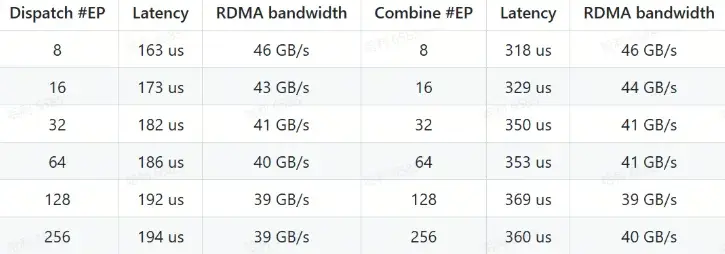
低延迟内核性能(纯 RDMA)
- 测试环境:
- GPU:H800
- 网络:CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)
- 配置:遵循典型 DeepSeek-V3/R1 生产环境设置(每批次 128 tokens,隐藏层 7168,top-8 专家,FP8 分发和 BF16 聚合)
- 性能数据:
- 低延迟内核在纯 RDMA 模式下实现了微秒级延迟,适合对延迟敏感的推理解码任务。
- 即使在高并行度(#EP=256)下,RDMA 带宽仍保持稳定,确保高效的数据传输。
DeepEP的应用场景
DeepEP 适用于多种 MoE 模型的训练和推理场景,特别是在大规模分布式训练中,DeepEP 能够显著提升通信效率,减少训练时间。
以下是 DeepEP 的主要应用场景:
- MoE 模型训练 DeepEP 的高吞吐量计算核心和高效的 All-to-All 通信机制,能够显著加速 MoE 模型的训练过程,尤其是在多机多 GPU 环境下。
- 推理预填充阶段在推理的预填充阶段,DeepEP 的高吞吐量计算核心能够快速处理大量数据,确保推理过程的高效性。
- 推理解码阶段对于推理解码阶段,DeepEP 的低延迟计算核心能够最大限度地减少推理延迟,适合对实时性要求较高的应用场景。
PPIO派欧云始终专注于探索多种并行策略,持续优化模型推理效率,旨在为客户提供更快的推理速度、更低的计算成本以及更高效的资源利用率。其中,TP(Tensor Parallelism)并行技术已在PPIO DeepSeek V3/R1 多机多卡推理服务中成功落地。这一技术为客户提供了高性价比的API调用服务,满足企业级AI应用的高并发、低延迟需求。



