
DeepSeek-V3最新论文重磅发布,PPIO已跑通所有核心推理加速技术

梁文锋署名论文最新发布,PPIO全链路推理加速技术率先跑通。
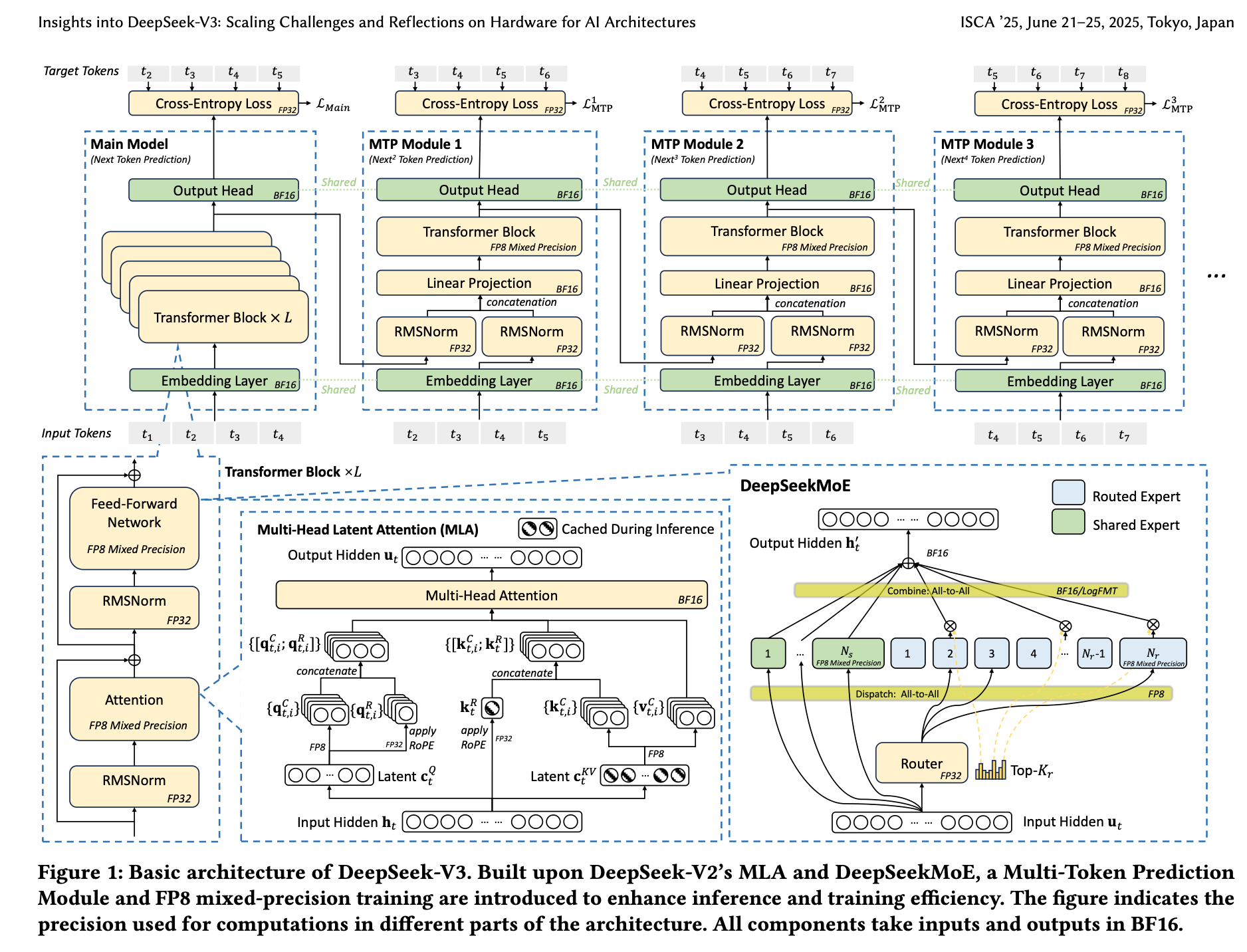
今天,DeepSeek官方发布了一篇重磅论文,由梁文锋亲自署名:《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》——《深入了解DeepSeek-V3:AI架构的硬件扩展挑战和思考》。
这篇论文并非DeepSeek-V3的详细架构与算法细节的重复,而是从硬件架构和模型设计的双重角度出发,探讨它们之间在实现大规模训练和推理的成本效益方面的复杂相互作用。
DeepSeek-V3的关键创新包括:
- 多头潜在注意力(MLA):通过压缩KV缓存来提高内存效率。
- 专家混合(MoE)架构:优化计算-通信权衡。
- FP8混合精度训练:充分利用硬件能力。
- 多平面网络拓扑:减少集群级网络开销。
这些创新旨在应对扩展LLM的三个核心挑战——内存效率、成本效益和推理速度,而这也是PPIO派欧云的推理加速优化方向。
作为一站式AIGC云服务平台,PPIO派欧云目前已经跑通了DeepSeek在开源周所发布的所有核心推理加速技术,包括PD分离,FlashMLA,DeepEP,DeepGEMM,EPLB,MicroBatch Overlap等。
以下是论文综述。
背景
近年来,大型语言模型(LLMs)在模型设计、计算能力和数据可用性的迭代进步推动下经历了快速的演变。2024年,像GPT4o、LLaMa-3、Claude 3.5 Sonnet、Grok-2、Qwen2.5、Gemini-2以及我们的DeepSeek-V3等突破性模型展示了显著的进步,进一步缩小了与AGI之间的差距。
正如Scaling Laws所展示的那样,增加模型大小、训练数据和计算资源可以显著提升模型性能,凸显了扩展性在提升人工智能能力中的关键作用。这些进展共同开启了一个时代,在这个时代中,扩大模型大小和计算能力被视为解锁更高智能水平的关键。最近的发展中,推理模型如OpenAI的o1/o3系列模型、DeepSeek-R1、Claude-3.7 Sonnet、Gemini 2.5 Pro、Seed1.5-Thinking和Qwen3不仅展示了大规模架构带来的好处,还展示了提高推理效率的必要性,特别是在处理更长的上下文和实现更深层次推理方面。
这些进展强调了实现更快、更高效推理的必要性,从而对计算资源提出了不断增加的需求。为了应对这些挑战,行业领导者如阿里巴巴、字节跳动、谷歌、xAI和Meta部署了巨大的训练集群,拥有数十万甚至数百万个GPU或TPU。尽管这些庞大的基础设施使得开发最先进的模型成为可能,但它们高昂的成本为较小的研究团队和组织设置了显著的障碍。
尽管存在这些障碍,像DeepSeek和Mistral这样的开源初创公司也在努力开发最先进的模型。其中,DeepSeek特别展示了有效的软硬件协同设计可以实现大型模型的成本效益训练,为较小的团队提供了公平的竞争环境。在此传统基础上,DeepSeek-V3成为了成本效益训练的新里程碑。
通过仅使用2048个NVIDIA H800 GPU,DeepSeek-V3实现了最先进的性能。这一成就与之前在Fire-Flyer AI-HPC的成本效益架构中展示的通过实用和可扩展的解决方案推进人工智能的承诺相一致。DeepSeek-V3的实践和见解展示了如何充分利用现有硬件资源,为更广泛的人工智能和高性能计算社区提供了宝贵的教训。
DeepSeek的设计原则
DeepSeek-V3的开发展示了如何采用硬件感知的方法来扩展大语言模型,其中每个设计决策都与硬件限制紧密对齐,以优化性能和成本效率。
DeepSeek-V3采用了在DeepSeek-V2中已被证明有效的DeepSeek-MoE和多头潜在注意力(MLA)架构。DeepSeek-MoE释放了MoE架构的潜力,而MLA则通过压缩键值(KV)缓存大幅减少了内存消耗。
此外,DeepSeek-V3引入了FP8混合精度训练,显著降低了计算成本,使大规模训练更加可行,且不降低模型质量。
为了提高推理速度,DeepSeek-V3集成了基于其多token预测模块的推测性解码,显著提高了生成速度。
除了模型架构之外,DeepSeek还通过部署多平面两层Fat-Tree网络来替换传统的三层Fat-Tree拓扑结构,探索了成本效益型的AI基础设施,降低了集群网络成本。
这些创新旨在应对扩展LLMs的三个核心挑战——内存效率、成本效益和推理速度。
DeepSeek-V3展示了硬件软件协同设计在推进大规模AI系统可扩展性、效率和可靠性方面的变革潜力。通过解决当前硬件架构的限制并提出切实可行的建议,为下一代AI优化硬件提供了路线图。随着AI工作负载的复杂性和规模持续增长,这些创新对于推动智能系统的发展至关重要。
PPIO也在致力于推动AI高性能推理,为企业及开发者提供高性能的API服务,目前已上线DeepSeek R1/V3、Llama、GLM、Qwen等系列模型,仅需一行代码即可调用。并且,PPIO通过2024年的实践,已经实现大模型推理的10倍+ 降本,实现推理效率与资源使用的动态平衡。



