A100 解析:为何它成为 AI 大模型时代的首选?

NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和 HPC 应用场景,在不同规模下实现出色的加速,有效助力更高性能的弹性数据中心。A100 采用 NVIDIA Ampere 架构,是 NVIDIA 数据中心平台的引擎。A100 的性能比上一代产品提升高达 20 倍,并可划分为七个 GPU 实例,以根据变化的需求进行动态调整。A100 提供 40GB 和 80GB 显存两种版本,A100 80GB 将 GPU 显存增加了一倍,并提供超快速的显存带宽(每秒超过 2 万亿字节 [TB/s]),可处理超大型模型和数据集。
英伟达 A100 显卡凭借其卓越的性能、高效能和广泛的应用场景,成为了数据中心和人工智能计算领域的佼佼者。无论是深度学习、科学计算还是大数据分析等领域,A100 显卡都能够为用户提供出色的计算能力和效率。
派欧算力云(www.paigpu.com)推出的 GPU 测评栏目正在连载中,基于实际生产中的业务场景,为大家带来不同 GPU 的性能测评,我们将专注于为大家带来最前沿、最深入的性能评测和行业动态。在这里,你将能第一时间了解到最新款 GPU 的性能表现。今天我们为大家带来的测评是 NVIDIA A100 Tensor Core GPU。
NVIDIA A100 规格参数
- 核心架构:Ampere,全球首款基于 7nm 工艺的数据中心 GPU 架构。
- CUDA 核心数:高达 6912 个,为深度学习等计算密集型任务提供强大的计算能力。
- Tensor Cores:432 个,支持 Tensor Float 32(TF32)和混合精度(FP16)计算,显著提升深度学习训练和推理的速度。
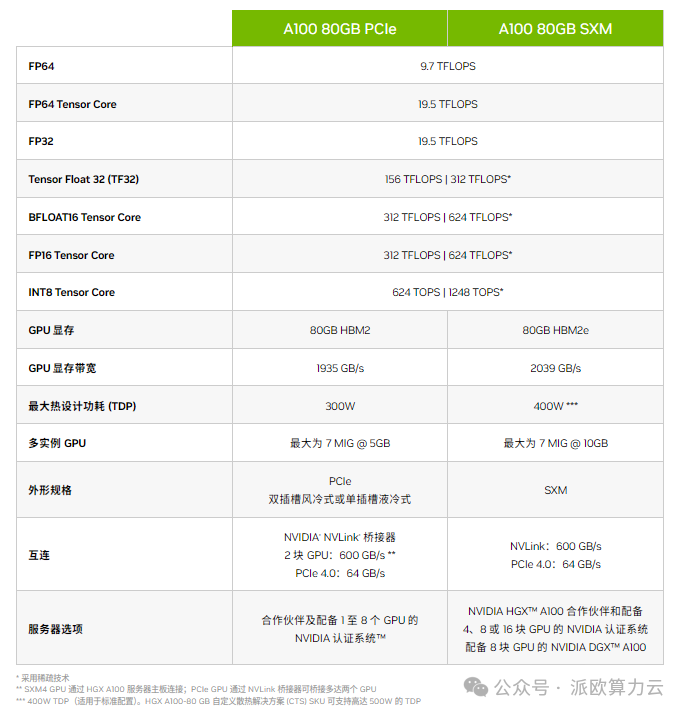
- 显存:提供 40GB、80GB 和 160GB 的 HBM2e 高速显存选项,内存带宽高达 2.5TB/s,满足大规模数据集和高性能计算的需求。
- 互联技术:支持第二代 NVIDIA NVLink 和 PCIe 4.0,实现高速的 GPU 到 GPU 和 GPU 到 CPU 的数据传输。
主要特性
A100 显卡在深度学习、科学计算等领域均表现出色,特别是在处理超大型模型和数据集时,能够显著提高计算速度和效率。A100 显卡支持多 GPU 集群配置,可动态划分为多个 GPU 实例,根据实际需求进行调整。同时,支持多种互联技术,方便与其他设备进行高速数据传输。A100 显卡兼容多种操作系统和深度学习框架,方便用户进行开发和部署。Ampere 架构针对 AI 推理进行了优化,提供了更高的计算密度和更低的延迟。
测试指标
长期以来,A100 都被认为是在大模型生产系统中的不二之选,基于此,派欧算力云对 Llama2 在 A100 上的表现进行了详细的测试。
我们以输入/输出长度作为变量,测试 Llama2 在 A100 平台运行时的延时与总吞吐量,以及 QPS 和耗时。
测试结果
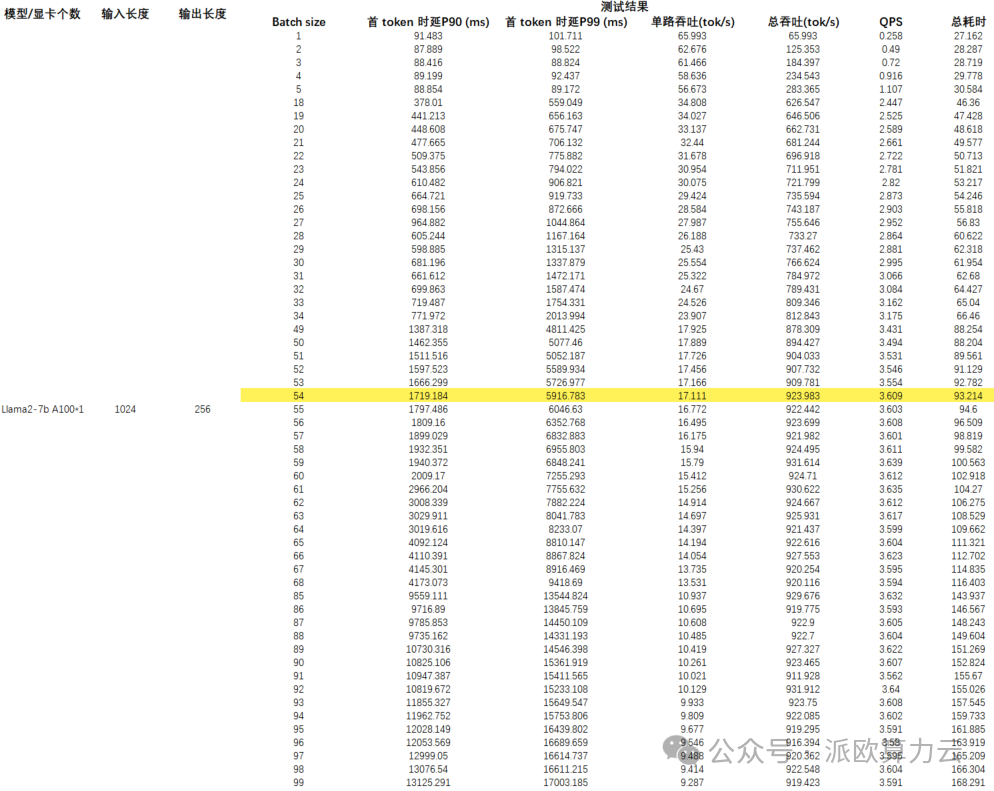
注:黄色部分为性能极限,在此基础上若再增加并发,吞吐量也不会提升。
总结
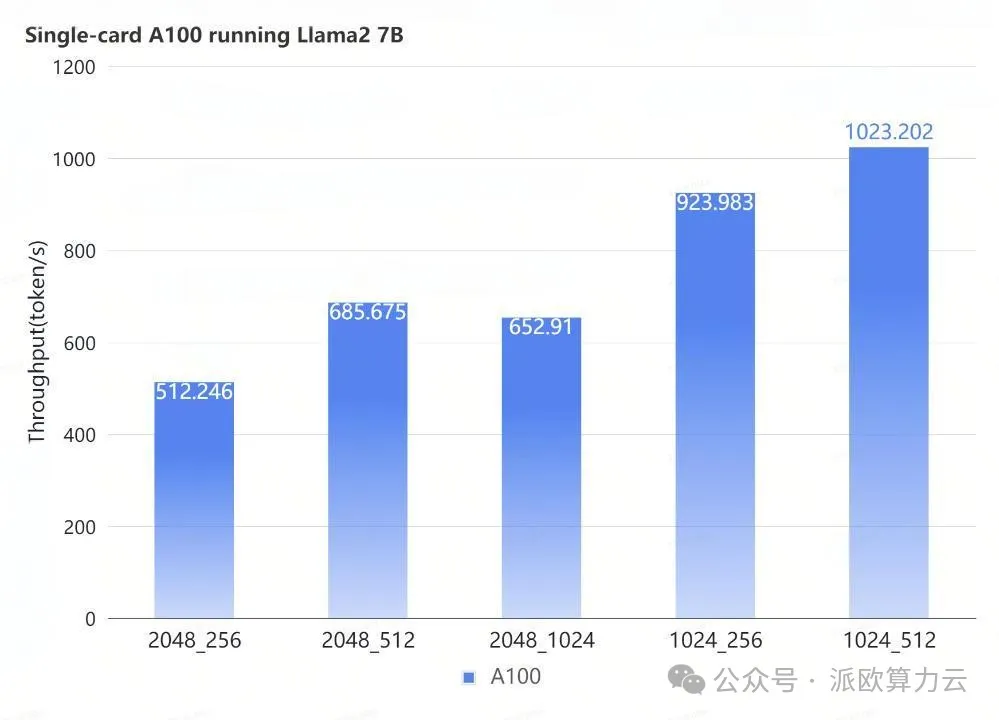
经过测试,我们将 Llama2 7B 在 A100 平台上的表现总结成这一张图。
可以看到在不同 IO 场景下,Llama2 QPS 的极限如何。