
PPIO 上线 DeepSeek-OCR-2 ,支持一键私有化部署

PPIO 算力市场首发上线了 DeepSeek-OCR-2 部署模板,为开发者提供开箱即用的模型服务。
DeepSeek-OCR-2 是 DeepSeek 团队最新发布的开源 OCR 模型。与传统 OCR 方案不同,该模型引入了 DeepEncoder V2 视觉编码器,并采用了“视觉因果流(Visual Causal Flow)”技术。这一架构改变使得模型能够基于语义逻辑理解文档结构,从而在处理多栏排版、复杂表格以及图文混排场景时表现出更高的准确性。
同时,DeepSeek-OCR-2 优化了视觉 Token 的压缩效率,在保持高精度的前提下显著降低了计算开销,非常适合作为多模态大模型的前端输入或用于高精度文档数字化任务。
现在,你可以通过 PPIO 算力市场的 DeepSeek-OCR-2 模板,将模型一键部署在 GPU 云服务器上。无需复杂的环境配置,只需简单几步,即可拥有私有化的 DeepSeek-OCR-2 模型,快速验证业务效果。
项目地址:https://ppio.com/gpu-instance/console/explore?selectTemplate=select
#01 GPU 实例+模板,一键部署 DeepSeek-OCR-2
step 1: 子模版市场选择对应模板,并使用此模板。
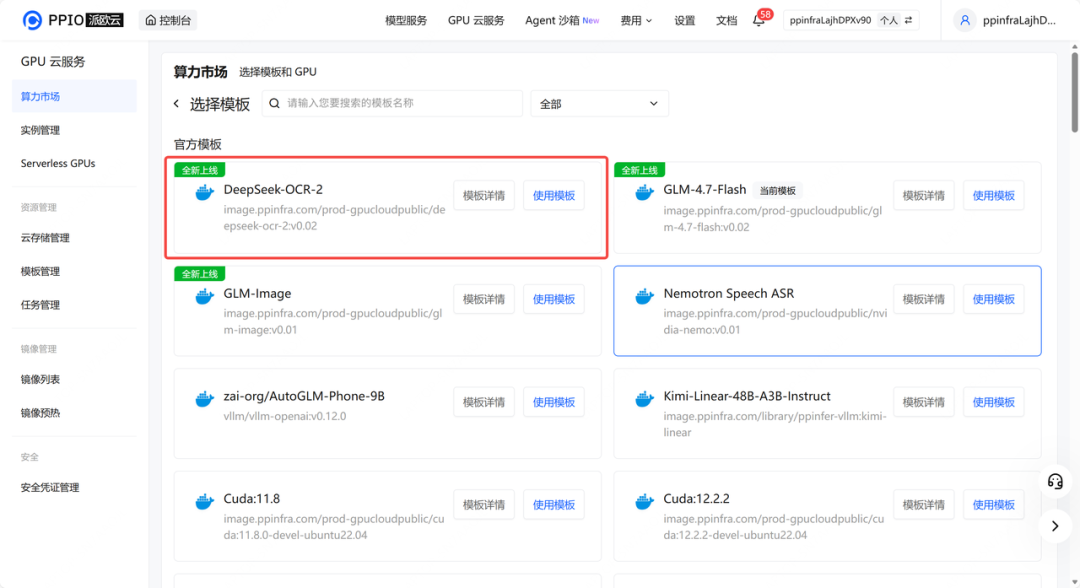
step 2: 按照所需配置点击部署。
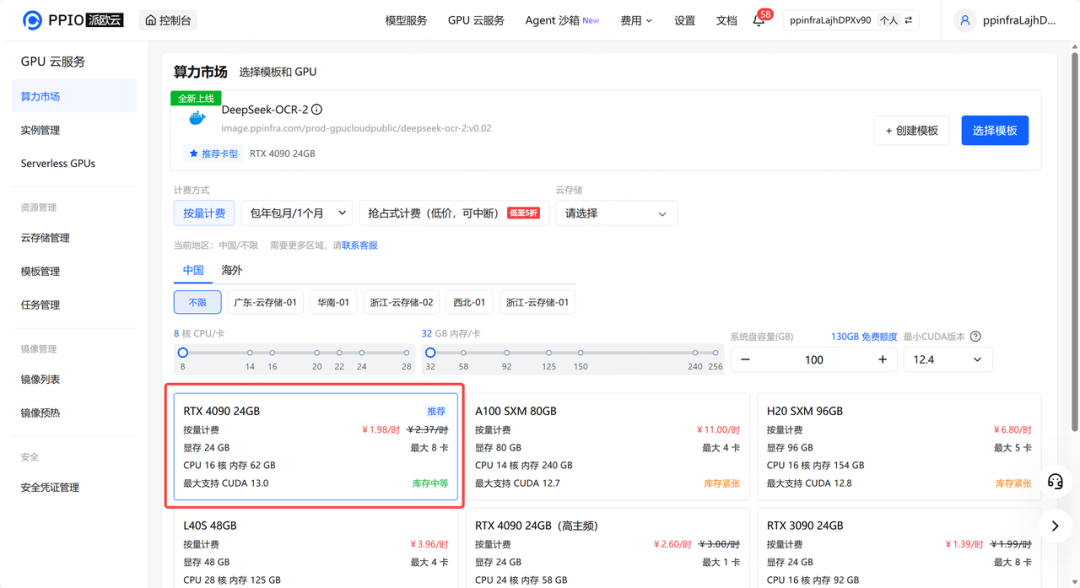
step 3: 检查磁盘大小等信息,确认无误后点击下一步。
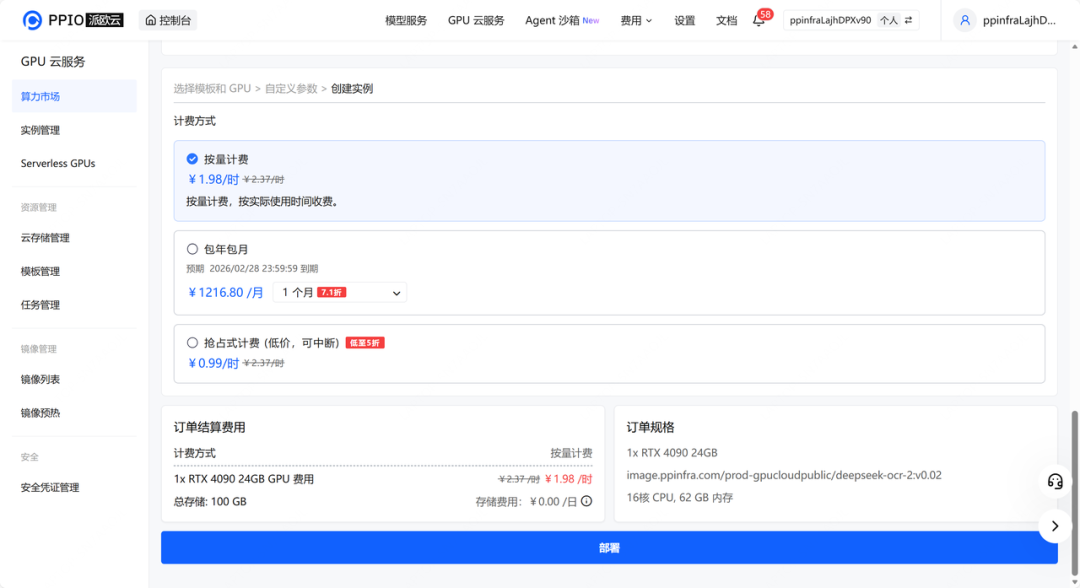
step 4: 稍等一会,实例创建需要一些时间。
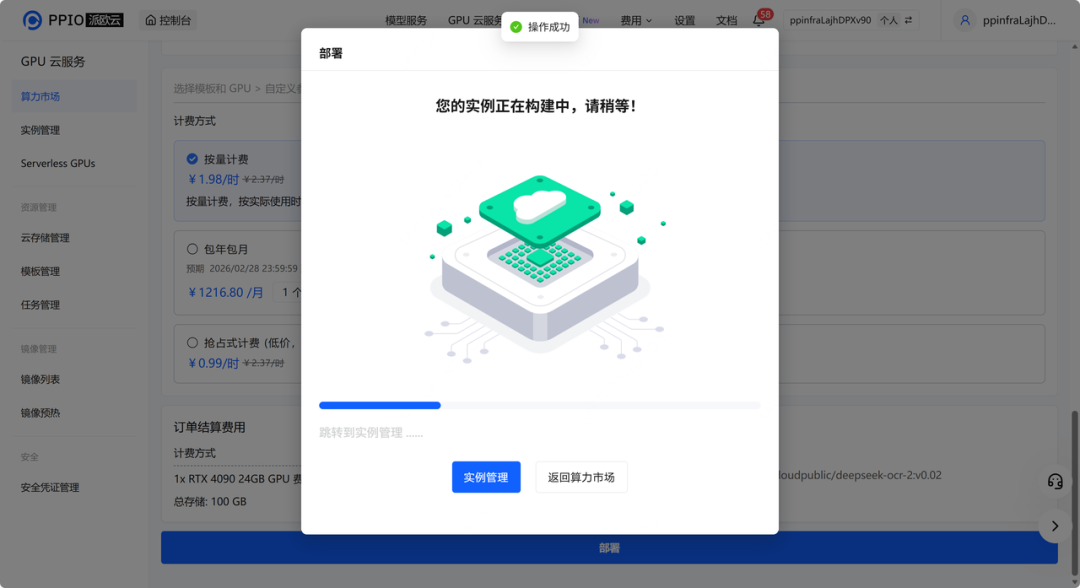
step 5: 在实例管理里可以查看到所创建的实例。

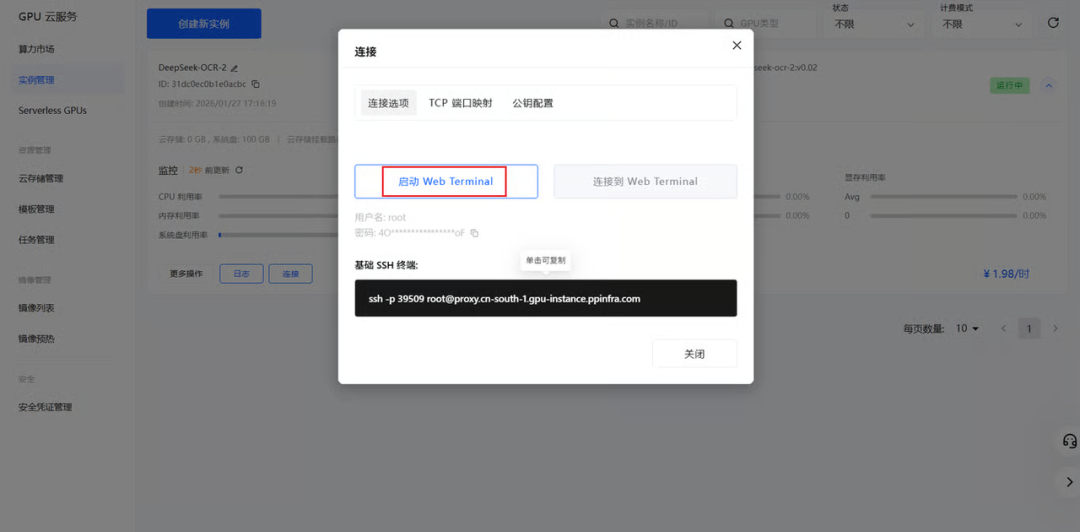
step 6: 点击启动 Web Terminal 选项,启动后点击连接选项即可连接到网页终端。
#02 如何使用
step 1:修改/vllm-workspace/DeepSeek-OCR-2/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm目录下 config.py配置
/your/image/path/ 需要处理的图片目录
/your/output/path/ 解析后输出的目录
step 2:在/vllm-workspace/DeepSeek-OCR-2/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm目录执行脚本
$ python3 run_dpsk_ocr2_image.py
INFO 01-27 00:38:17 [__init__.py:239] Automatically detected platform cuda.
INFO 01-27 00:38:21 [config.py:456] Overriding HF config with {'architectures': ['DeepseekOCR2ForCausalLM']}
INFO 01-27 00:38:22 [config.py:717] This model supports multiple tasks: {'embed', 'reward', 'generate', 'score', 'classify'}. Defaulting to 'generate'.
INFO 01-27 00:38:22 [llm_engine.py:240] Initializing a V0 LLM engine (v0.8.5) with config: model='deepseek-ai/DeepSeek-OCR-2', speculative_config=None, tokenizer='deepseek-ai/DeepSeek-OCR-2', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=deepseek-ai/DeepSeek-OCR-2, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=None, chunked_prefill_enabled=False, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":256}, use_cached_outputs=False,
INFO 01-27 00:38:24 [cuda.py:292] Using Flash Attention backend.
INFO 01-27 00:38:24 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 01-27 00:38:24 [model_runner.py:1108] Starting to load model deepseek-ai/DeepSeek-OCR-2...
INFO 01-27 00:38:25 [config.py:3614] cudagraph sizes specified by model runner [1, 2, 4, 8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, 104, 112, 120, 128, 136, 144, 152, 160, 168, 176, 184, 192, 200, 208, 216, 224, 232, 240, 248, 256] is overridden by config [256, 128, 2, 1, 4, 136, 8, 144, 16, 152, 24, 160, 32, 168, 40, 176, 48, 184, 56, 192, 64, 200, 72, 208, 80, 216, 88, 120, 224, 96, 232, 104, 240, 112, 248]
INFO 01-27 00:38:26 [weight_utils.py:265] Using model weights format ['*.safetensors']
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 20.02it/s]
INFO 01-27 00:38:28 [loader.py:458] Loading weights took 1.26 seconds
INFO 01-27 00:38:28 [model_runner.py:1140] Model loading took 6.3336 GiB and 3.787022 seconds
Some kwargs in processor config are unused and will not have any effect: image_std, candidate_resolutions, downsample_ratio, mask_prompt, image_mean, sft_format, ignore_id, normalize, image_token, patch_size, add_special_token, pad_token.
WARNING 01-27 00:38:33 [fused_moe.py:668] Using default MoE config. Performance might be sub-optimal! Config file not found at /usr/local/lib/python3.12/dist-packages/vllm/model_executor/layers/fused_moe/configs/E=64,N=896,device_name=NVIDIA_GeForce_RTX_4090.json
INFO 01-27 00:38:33 [worker.py:287] Memory profiling takes 5.08 seconds
INFO 01-27 00:38:33 [worker.py:287] the current vLLM instance can use total_gpu_memory (23.53GiB) x gpu_memory_utilization (0.75) = 17.65GiB
INFO 01-27 00:38:33 [worker.py:287] model weights take 6.33GiB; non_torch_memory takes 0.08GiB; PyTorch activation peak memory takes 1.07GiB; the rest of the memory reserved for KV Cache is 10.16GiB.
INFO 01-27 00:38:34 [executor_base.py:112] # cuda blocks: 11100, # CPU blocks: 4369
INFO 01-27 00:38:34 [executor_base.py:117] Maximum concurrency for 8192 tokens per request: 21.68x
INFO 01-27 00:38:35 [model_runner.py:1450] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 100%|██████████████████████████████████████████████████████| 35/35 [00:08<00:00, 4.21it/s]
INFO 01-27 00:38:44 [model_runner.py:1592] Graph capturing finished in 8 secs, took 0.16 GiB
INFO 01-27 00:38:44 [llm_engine.py:437] init engine (profile, create kv cache, warmup model) took 15.32 seconds
INFO 01-27 00:38:44 [async_llm_engine.py:211] Added request request-1769503124.
Some kwargs in processor config are unused and will not have any effect: image_std, candidate_resolutions, downsample_ratio, mask_prompt, image_mean, sft_format, ignore_id, normalize, image_token, patch_size, add_special_token, pad_token.
<|ref|>text<|/ref|><|det|>[[163, 0, 456, 155]]<|/det|>
By the lottery jaunty, the chances of the lottery combinations to work out the chances of other prizes, but it all starts to get a bit fiddly, we'll move on to something else. (How to work out the other lottery chances is just one of the amazing features you'll find at: www.murderousmaths.co.uk)
<|ref|>sub_title<|/ref|><|det|>[[163, 168, 280, 199]]<|/det|>
## The disappearing sum
<|ref|>text<|/ref|><|det|>[[160, 189, 456, 402]]<|/det|>
It's Friday evening. The lovely Veronica Gummfloss has been out with the football team who have all escorted her safely back to her doorstep. It's that tender moment when each hopeful player closes his eyes and leans forward with quivering lips. Unfortunately Veronica's parents heard them clumping down the road and Veronica knows she only has time to kiss four out of the eleven of them if she's going to do it properly.
<|ref|>image<|/ref|><|det|>[[163, 408, 450, 666]]<|/det|>
<|ref|>text<|/ref|><|det|>[[154, 645, 450, 744]]<|/det|>
How many choices has she got? It's \( {}^{11}C_{4} \) which is \( {}^{11} \) but for goodness sake DON'T reach for the calculator! The most brilliant thing about perms and
<|ref|>text<|/ref|><|det|>[[500, 0, 808, 115]]<|/det|>
comes is that the answer can never be a fraction which means that EVERYTHING ON THE BOTTOM ALWAYS CANCELS OUT! It's probably the best fun you'll ever have with a pencil so here we go...
<|ref|>text<|/ref|><|det|>[[512, 111, 792, 188]]<|/det|>
\( 4! \times 7! \)
\( 11! = 11 \times 10 \times 9 \times 8 \times 7 \times 6 \times 5 \times 4 \times 3 \times 2 \times 1 \)
\( 4 \times 3 \times 2 \times 1 \times 7 \times 6 \times 5 \times 4 \times 4 \times 3 \times 2 \times 1 \)
<|ref|>text<|/ref|><|det|>[[499, 179, 804, 295]]<|/det|>
(Before we continue, grab this book and show somebody this sum. Rub their face on it if you need to and tell them that this is the sort of thing you do for fun without a calculator these days because you're so brilliant.)
<|ref|>text<|/ref|><|det|>[[499, 291, 803, 350]]<|/det|>
Off we go then. For starters we'll get rid of the 7! bit from top and bottom and get:
<|ref|>equation<|/ref|><|det|>[[612, 361, 696, 412]]<|/det|>
\[ 11\times10\times9\times8 \]
<|ref|>equation<|/ref|><|det|>[[614, 384, 691, 414]]<|/det|>
\[ 4\times3\times2\times1 \]
<|ref|>text<|/ref|><|det|>[[496, 424, 801, 525]]<|/det|>
Pow! That's already got rid of more than half the numbers. Next we'll see that the \( 4 \times 2 \) on the bottom cancels out the 8 on top (and we don't need that \( \times 1 \) " on the bottom either). We're left with...
<|ref|>equation<|/ref|><|det|>[[616, 541, 686, 592]]<|/det|>
\[ \frac{11\times10\times9}{3} \]
<|ref|>text<|/ref|><|det|>[[495, 604, 800, 655]]<|/det|>
Then the 3 on the bottom divides into the 9 on top leaving it as a 3 so all we've got now is:
<|ref|>text<|/ref|><|det|>[[555, 669, 739, 694]]<|/det|>
Veronica's choices = \( 11 \times 10 \times 3 \)
<|ref|>text<|/ref|><|det|>[[493, 714, 600, 741]]<|/det|>
Look! No bottom.INFO 01-27 00:38:48 [async_llm_engine.py:179] Finished request request-1769503124.
INFO 01-27 00:38:48 [async_llm_engine.py:65] Engine is gracefully shutting down.
===============save results:===============
image: 100%|███████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 26886.56it/s]
other: 100%|████████████████████████████████████████████████████████████████████████| 15/15 [00:00<00:00, 223101.28it/s]
[rank0]:[W127 00:38:49.576360410 ProcessGroupNCCL.cpp:1496] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator()) PPIO 的算力市场模板致力于帮助企业及个人开发者降低大模型私有化部署的门槛,无需繁琐的环境配置,即可实现高效、安全的模型落地。目前,PPIO算力市场已上线几十个私有化部署模板,除了 DeepSeek-OCR-2,你也可以将 AutoGLM-Phone-9B、 GLM-Image、PaddleOCR-VL 等模型快速进行私有化部署。



