
PPIO上线Prompt Cache:让模型调用更快、更省、更稳

在大模型推理场景中,响应速度直接影响用户体验和系统性能。传统推理服务需要每次都重新计算相同的文本片段,导致不必要的计算开销和延迟,PPIO 推出的 Prompt Cache(提示词缓存)有效解决了这一问题。
PPIO的 Prompt Cache 功能基于智能缓存策略,能够识别和缓存可重复使用的文本模式,并在后续请求中快速调用。这种技术不仅大幅提升了推理效率,更让长文本应用变得更加经济。
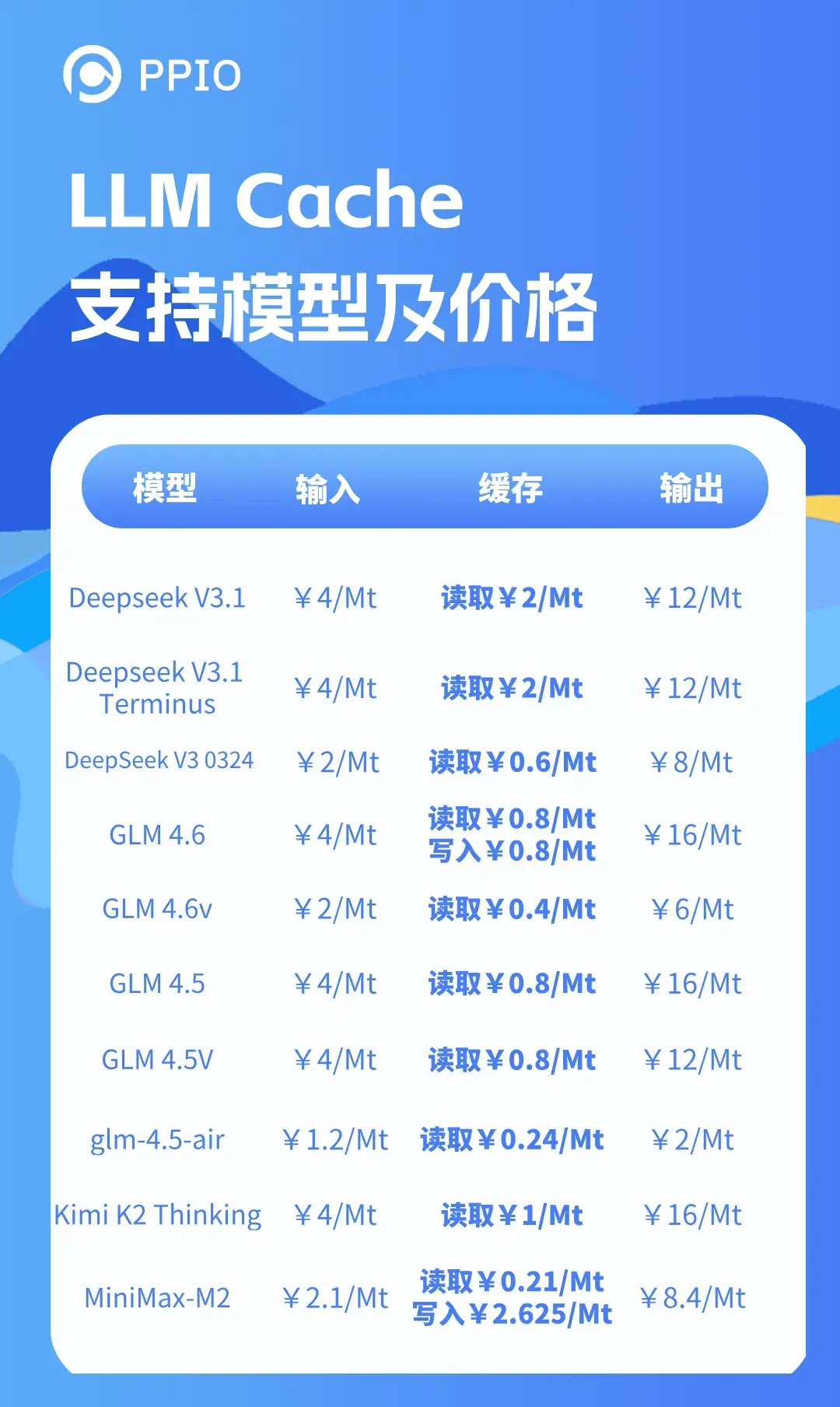
当前PPIO的 Prompt Cache 功能已支持以下主流大模型,前往PPIO官网即可体验。
- DeepSeek 系列:DeepSeek V3.1 / DeepSeek V3.1 Terminus / DeepSeek V3 0324
- GLM 系列:GLM-4.6 / GLM-4.6v / GLM-4.5 / GLM-4.5V / GLM-4.5-Air
- Moonshot 系列:Kimi K2 Thinking
- MiniMax 系列:MiniMax-M2
官网地址:
https://ppio.com/ai-computing/llm-api
# 01 Prompt Cache 技术原理
Prompt Cache 是一种专为优化大语言模型输入处理而设计的技术。其核心原理是在系统层面,将高频使用的提示词前缀(如系统 System Prompt、重复的文档内容或少样本示例)预先计算并存储其 KV Cache(键值缓存) 状态。
当后续请求包含相同或相似的前缀时,系统可以直接复用显存中已缓存的计算状态,无需从头开始进行 Attention 计算。
与传统缓存不同,Prompt Cache 工作在跨请求和跨会话层面。当用户提交包含长提示词的请求时,系统会将前缀结构化存储;一旦后续请求命中该前缀,模型仅需处理新增的动态内容,从而实现“跳跃式”生成。
主要应用场景
Prompt Cache 特别适用于存在大量“静态前缀”或“重复上下文”的业务场景。
- 多轮对话与客服系统:在保存大量历史对话记录的场景中,无需每次重复计算旧的对话内容。
- 长文档分析与问答:针对同一份法律合同、技术手册或财报进行多次提问时,文档内容只需计算一次即可被反复复用。
- 代码生成:在通过 Repo 级代码库进行上下文补全时,项目结构和依赖文件的上下文可被持久缓存。
- 结构化输出与角色扮演:复杂的 System Prompt 和 Few-Shot 示例(少样本提示)可以被完全缓存,无需每次消耗计算资源。
# 02 PPIO 的 Prompt Cache 服务
PPIO的 Prompt Cache 具备三大核心优势:
(1)显著降低推理成本
通过避免重复计算相同的提示词前缀,大幅减少 Token 相关的计算支出。在 PPIO 的定价体系中,缓存命中的 Token 读取费用低至正常输入价格的十分之一,通过高命中率策略,综合成本可降低 50% 以上。
(2)有效提升首字速度 (TTFT)
跳过对长前缀的重复编码处理,模型可以瞬间进入内容生成阶段。在长文本场景下,首字延迟可降低 80%,为用户提供极为流畅的交互体验。
(3)增强高并发稳定性
减少重复计算意味着降低了 GPU 的负载压力,从而提升了整体系统在高并发场景下的吞吐量与稳定性。
Prompt Cache 技术的普及,有效解决了当前大模型应用中“长文本贵、长文本慢”的核心痛点,为构建智能化、经济化的 AI 服务奠定了基础。
PPIO 一直致力于为用户提供更高效率、更低成本、更稳定可靠的算力与模型服务,通过持续优化 Prompt Cache 等关键技术能力,进一步提升模型服务性能,让大模型真正释放长期价值,驱动下一代应用创新。



