
2025年Q3大模型tokens调用量观察:Grok逆袭,DeepSeek弥坚

2025 年第三季度,大模型市场又有哪些新的变化?
基于 OpenRouter 过去三个月的 tokens 调用数据,我们能看到总 token 使用量排名及趋势、不同大模型的市场份额占比、细分领域模型的应用偏好等趋势。
OpenRouter 的数据主要反映了海外闭源模型的调用量趋势。预告一下,下一篇我们将基于 PPIO 数据,分析国产开源模型在国内市场的调用量趋势。
# 01
Tokens 调用量高速增长,Grok 逆袭
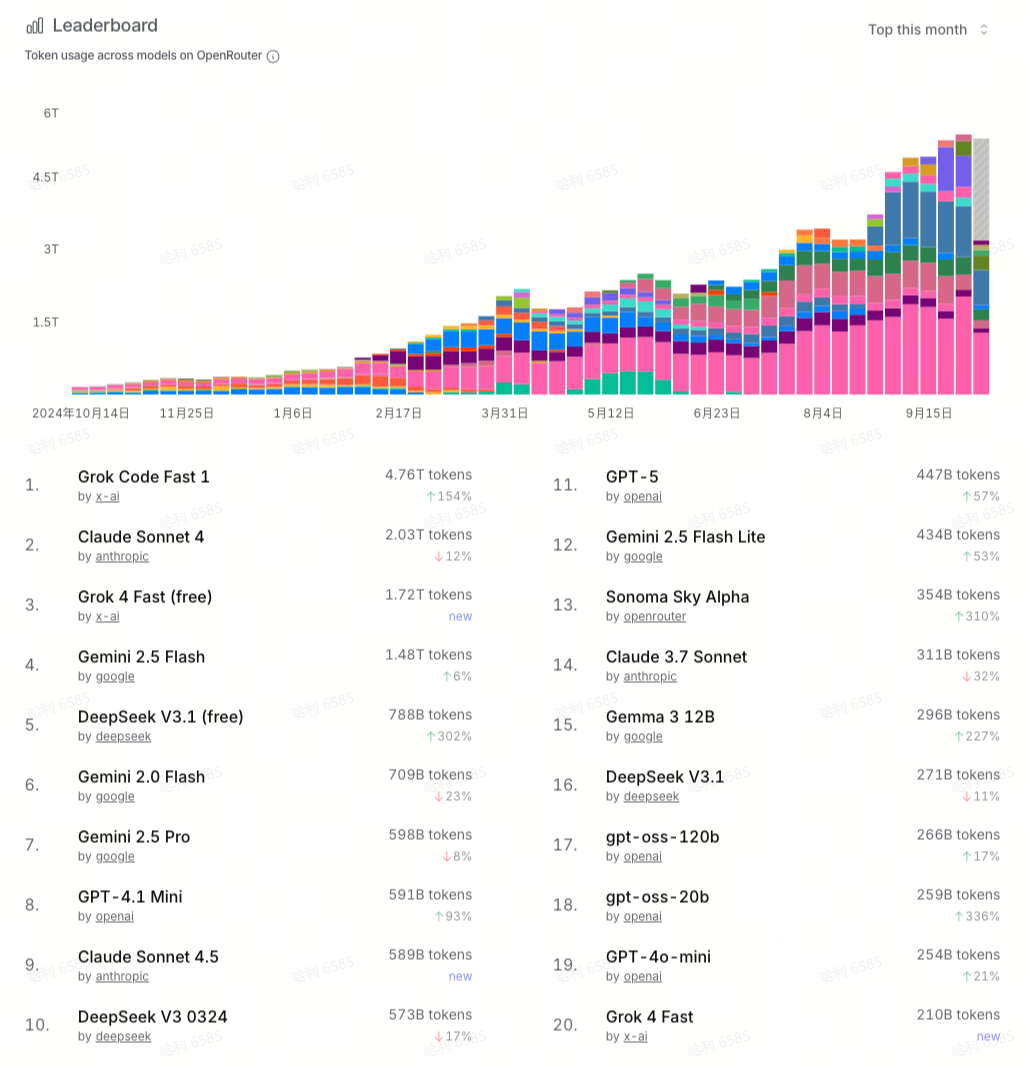
- 2025 年第三季度,OpenRouter 的 tokens 调用总量相比上个季度继续增长,9 月份每周平均消耗超过 4T tokens,大约是上个季度周消耗的两倍。也就是说,AI 推理市场仍在高速增长。
- 在 tokens 消耗前二十的模型中,Grok 是一个新面孔。今年上半年,Grok 系列模型表现平平,一直被归类于 Others。但在第三季度,Grok 系列迎来重大更新,xAI 先后在 7 月、8 月和 9 月发布了 Grok 4、Grok Code Fast 1 和 Grok 4 Fast,后两者分别跻身趋势排行榜的第一和第三。Grok Code Fast 1 的 tokens 调用量大约占每周总调用量的 1/5。
- DeepSeek 是开源模型阵营最后的荣光。DeepSeek 自发布以来长期排名 top10 甚至 top5 的位置,用户留存率极高。DeepSeek 在第三季度发布了 DeepSeek V3.1 和 DeepSeek V3.1 Terminus,前者排名第五。DeepSeek 在 9 月底发布 DeepSeek V3.2,API 价格大幅下降,但尚未进入 top20 的榜单。
- Anthropic 的模型呈现明显的“以新换旧”的趋势。Claude Sonnet 4 自发布以来逐渐替代 Claude Sonnet 3.7,在第三季度成为 Anthropic 的主力模型,每周的调用量大约稳定在 500B-600B 之间。在 9 月底,Claude Sonnet 4.5 发布,一举跃进排行榜的前十位,很有可能在第四季度替代 Claude Sonnet 4。
- Google 的模型呈现“多点开花”的趋势。在 7、8 两个月,Gemini 2.0 Flash、Gemini 2.5 Flash、Gemini 2.5 Pro 三款模型同时跻身 top10 榜单中。不过,Gemini 2.5 Pro 这款旗舰模型在 9 月份增长放缓,被其他模型挤出 top10 榜单。
- OpenAI 的模型并不能稳定地进入 top10 榜单,无论是 GPT-4o-mini、GPT-4.1 Mini 还是 GPT-5,都乏善可陈。
- OpenRouter 将 top10 之外的模型统一归到 Others。在第三季度,Others 模型的每周调用量激增到 1T-2T之间,相比上个季度增长了 1 倍左右,呈现百花齐放的态势。其中,阿里的 Qwen3-Coder-480B、Qwen3-30B 也短暂跻身 top10 榜单中,是 DeepSeek 之外第二款跻身该榜单的国产模型。
# 02 市场份额:马太效应明显
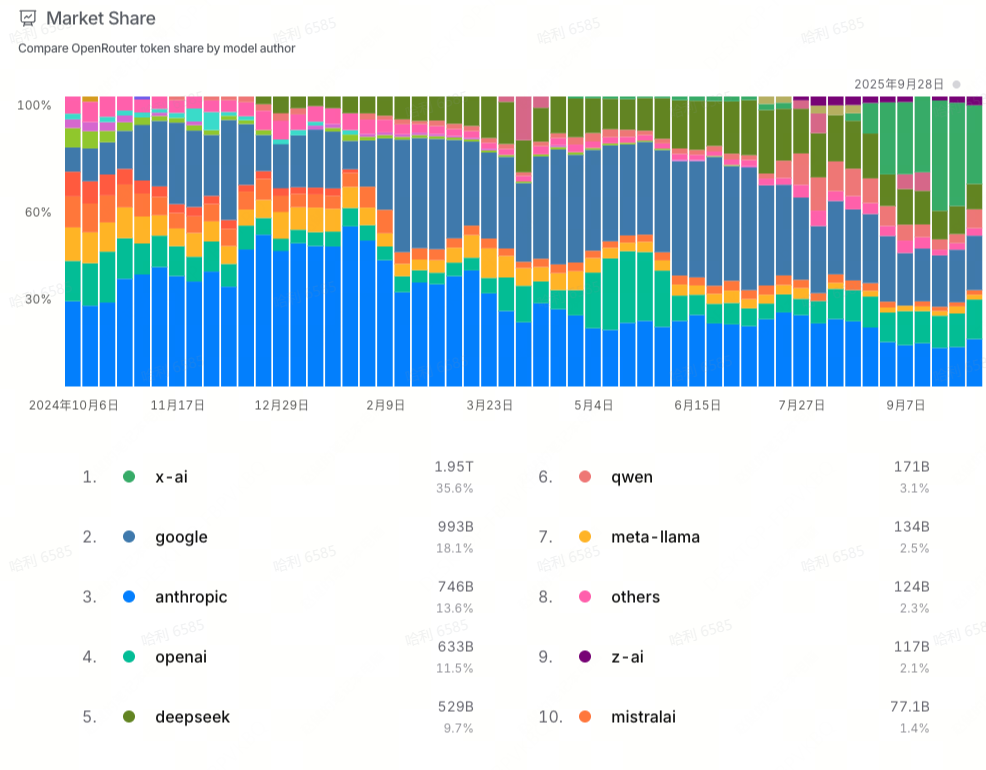
- 在 7、8 月份,Google、Anthropic 和 DeepSeek 三家牢牢占据市场份额的前三名,累计占据 60%-80% 的市场份额,呈现出马太格局。但到 9 月份,xAI 使用量飙升,市场份额最高占据近 40%,大大挤压了其他模型的市场份额。
- 在第三季度末尾,Google 的市场份额 从 7 月 份的 30% 左右下降到 18% 左右,Anthropic 的市场份额从 7 月份的 25% 下降到 13% 左右,DeepSeek 的市场份额则持续下滑,从 7 月初的 20% 左右下降到 10% 以下。
- OpenAI 的市场份额在第三季度小幅增长,从 5% 左右增长到 10%,超越了 DeepSeek。
- 另外三家国产模型也曾进入市场份额的 top10。其中,阿里 Qwen 的市场份额在第三季度先增长后下滑,从 8 月初的 11% 下降到了 9 月底的 3%;智谱(z.ai)在第三季度发布 GLM-4.5,大约占据 2%-3% 的市场份额;月之暗面在第三季度期间发布 Kimi-K2 以及后续更新版本,一度占据 2%-3% 的市场份额,但在 9 月份未能进入 top10。
- Llama 和 Mistral 的市场份额在持续萎缩,两者都在 2% 左右。
- 上述模型之外的其他模型的累计市场份额也在持续降低,不足 5%,马太效应显著。
# 03 细分市场:Grok 力压 Claude
OpenRouter 将大模型应用场景分为编程、角色扮演、市场营销、市场营销/SEO、科技、科学、文本翻译、法律、金融、健康、趣闻、学术等领域,大部分场景的模型消耗集中在 Others。
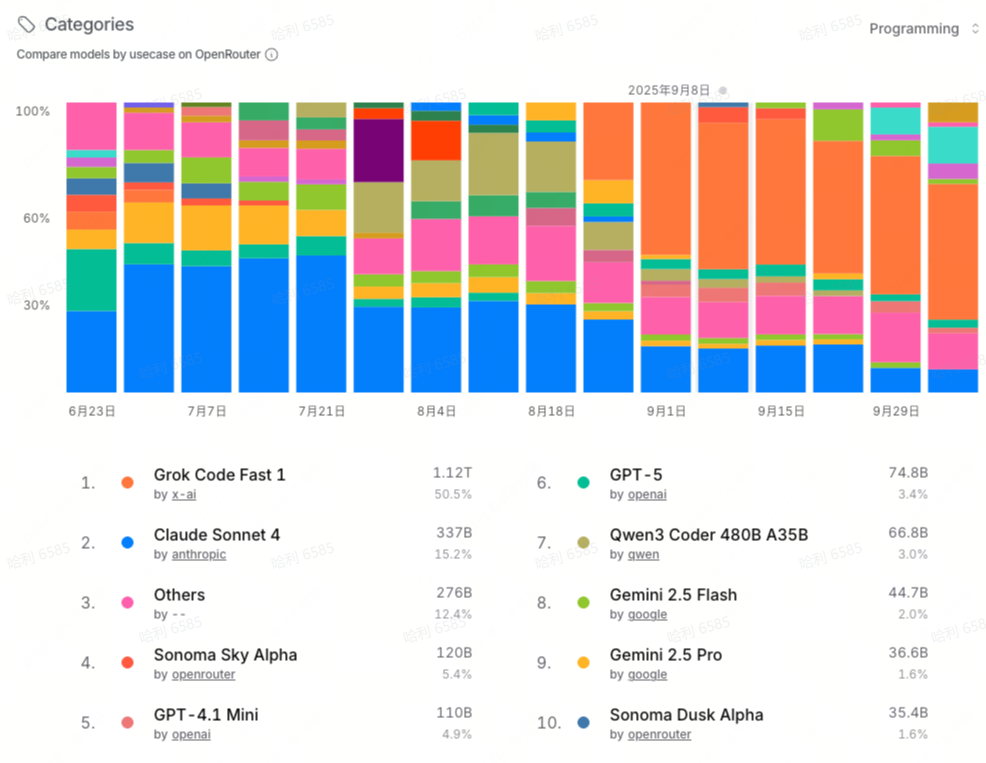
- 编程是其中最核心的场景。Claude 4 曾长时间霸占榜首位置,是最受欢迎的编程模型,市场占有率最高达到 47%。但在 Grok Code Fast 1 发布后,后者取代 Claude 4 占据第一,市场占有率超过 50%。除了 Claude 4 和 Grok Code Fast 1,编程模型的最大使用量是“Others”,表明这是一个百花齐放的细分市场。
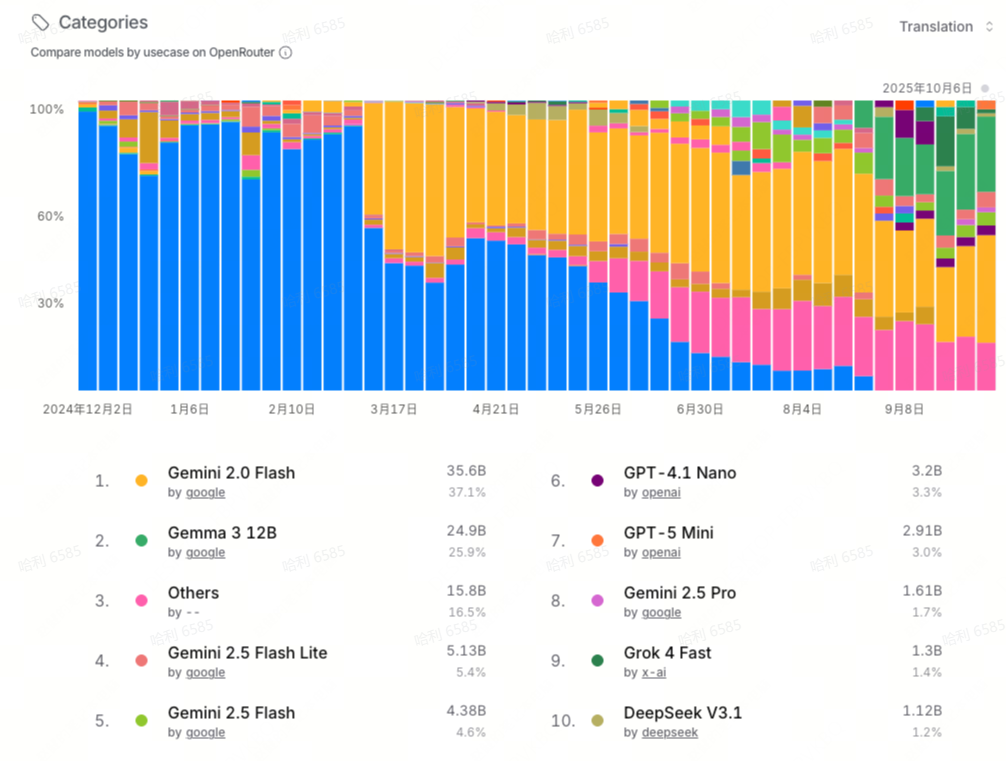
- 文本翻译领域几乎是 Google 的天下。从年初的 Gemini 1.5 Flash 8B,到后来的 Gemini 2.0 Flash,都牢牢占据榜首位置。主要原因是文本翻译用量较大,而 Google 的这两款 Flash 模型价格实惠且速度快。
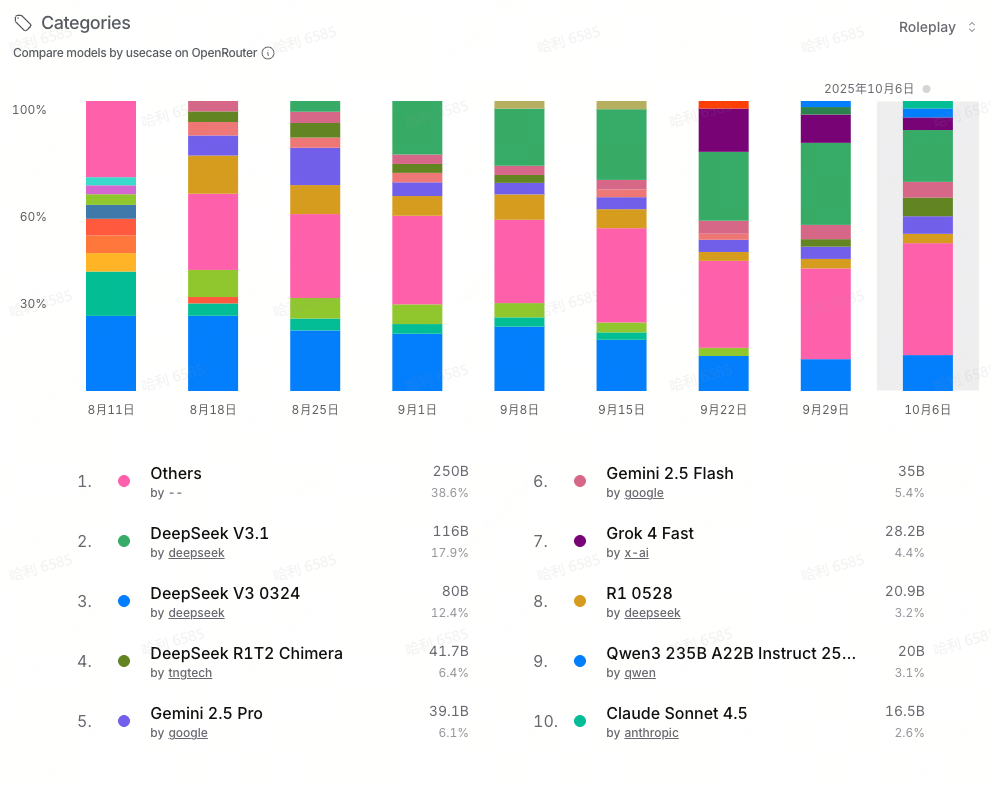
- 角色扮演领域是一个高速发展的市场,但该领域高度碎片化,Others 的市场份额占据第一。除此之外,DeepSeek V3 0324 长期占据领先位置,直到被最新发布的 DeepSeek V3.1 超越。
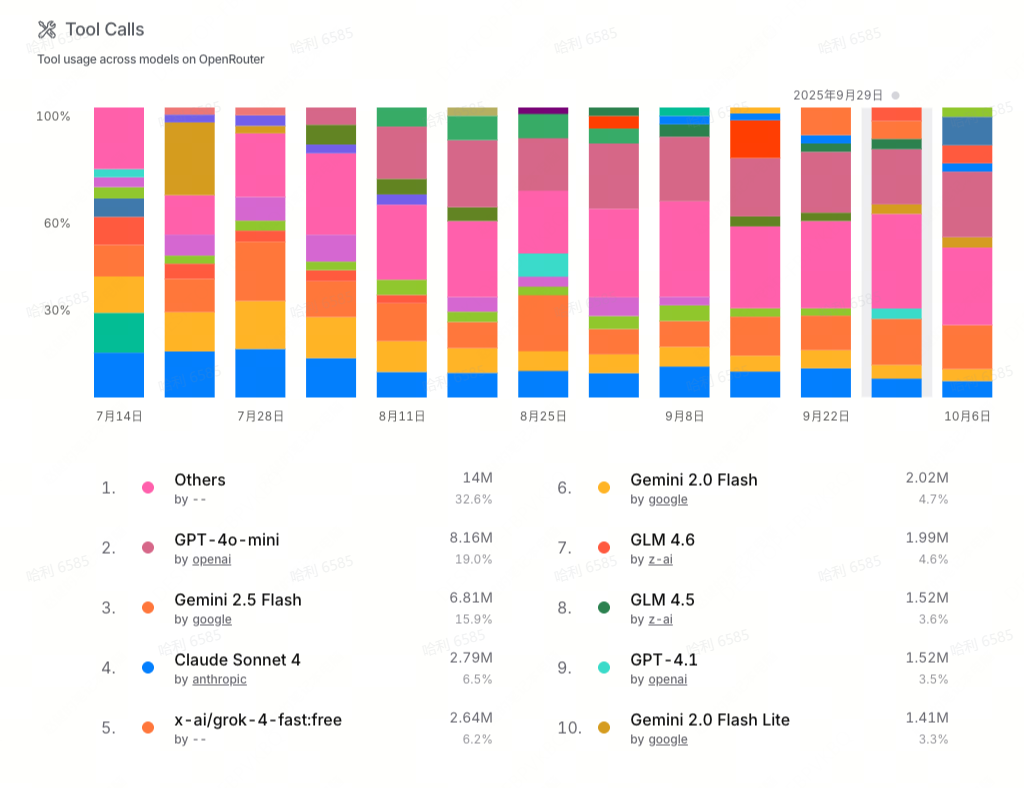
- 工具调用(Tool Call) 也是大模型的核心能力之一,它让大模型具备调用外部工具或函数的能力,在 Agent 场景不可或缺。目前前沿大模型基本都具备工具调用能力。虽然 GPT-4o-mini 在编程场景的调用量不如 Claude-4 或者 Grok-Code-Fast 1,但 GPT-4o-mini 的工具调用场景的使用量是最大的。
# 04 结语
基于以上数据,我们得出了几点最新的观察:
- 海外大模型市场被闭源模型统治,Google、Anthropic、OpenAI 以及 xAI 占据绝大部分市场份额,马太效应明显。
- DeepSeek 在开源模型领域一枝独秀、历久弥坚,用户留存率极高,但市场份额在第三季度末呈下滑趋势。
- Grok 凭借编程模型 Grok Code Fast 1 在第三季度迎来逆袭,上半年编程模型“一哥” Claude 的市场份额被严重挤压。
- OpenAI 在 API 调用市场(to B)并不强势,落后于Google 与 Anthropic。
- Google 在 API 调用市场非常强势。作为榜单中的唯一大厂,仍表现出了极强的灵活性与竞争力。
- DeepSeek 之外,阿里Qwen、智谱GLM、月之暗面Kimi三家国产模型各有亮眼表现,有望在 Q4 以及明年带来更多惊喜。
关于第三季度大模型调用量趋势,你还有哪些观点?欢迎在评论区补充。
如果你有大模型 API 或者 Sandbox、GPU 云等专属需求,可扫码联系我们 👇
现在用邀请码【24CGOJ】注册还可得 15 元代金券。




