
2025年Q3 tokens调用量趋势:国产开源模型“一超三强”

昨天,我们发布了 2025 年 Q3 海外大模型 tokens 调用量趋势。
海外 AI 推理市场由闭源模型厂商主导,Google、Anthropic、OpenAI 以及 xAI 四家闭源模型占据了60%-80% 的市场份额。
但在国内恰恰相反, DeepSeek 掀起的开源浪潮还在继续,Qwen、GLM、Kimi、百度、MiniMax 等模型公司纷纷拥抱开源。
今天,基于第三季度 PPIO 平台的开源模型调用量表现,我们总结出国内 AI 推理市场五大趋势。
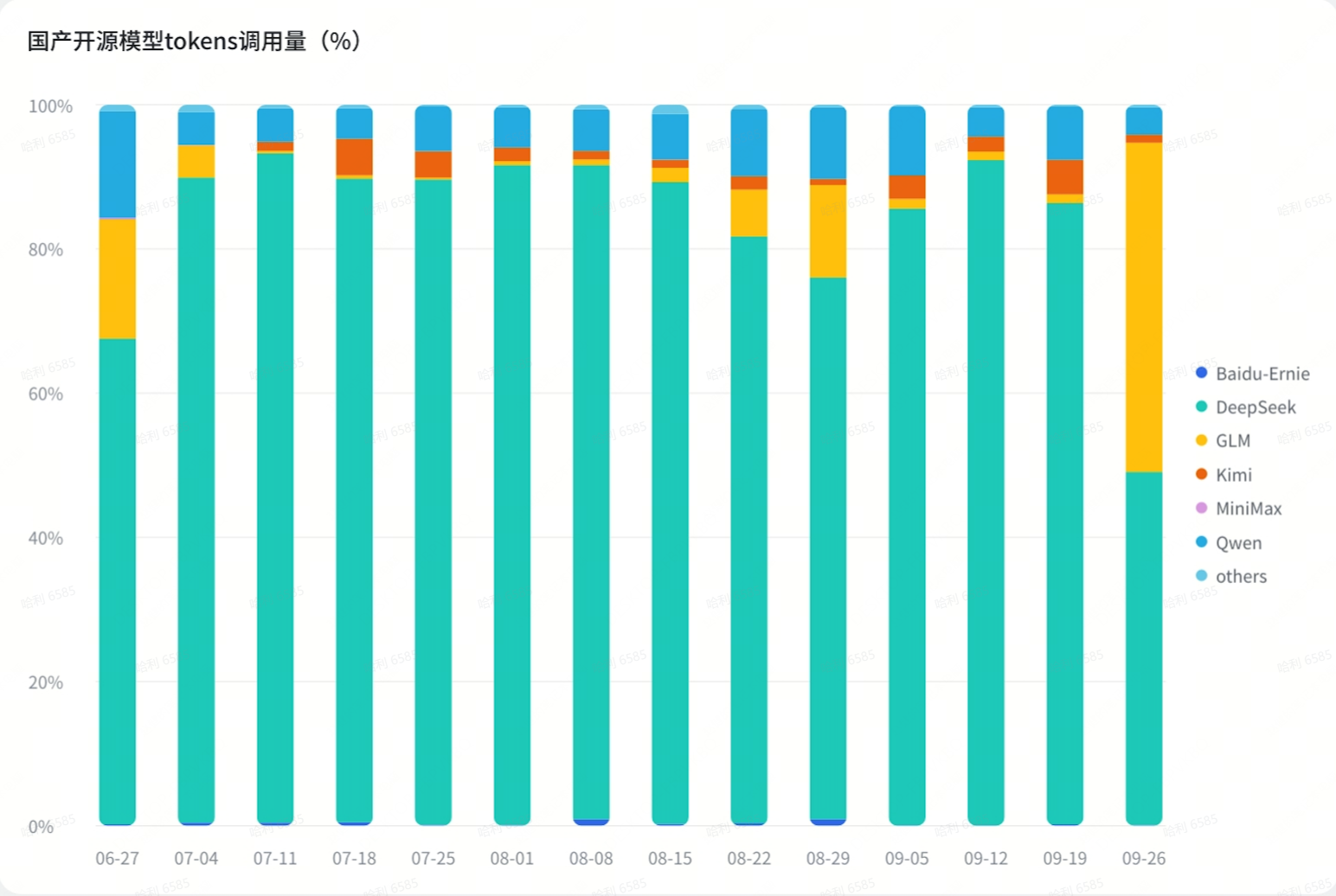
趋势一:国产开源模型“一超三强”
在第三季度,DeepSeek 仍然是用户调用量最大的开源模型,最高占据 90% 以上的市场份额,比上个季度进一步增长。
阿里 Qwen 系列在第三季度的大部分时间里都是用户调用量第二大的开源模型,且用量非常稳定,市场占有率在 5%-10% 左右。
Q3 最大的变化在于,国产开源模型的选择更多样化了,其中智谱 GLM 和月之暗面 Kimi 最受用户欢迎。Kimi 大约能占据 2%-5% 的市场份额且用量稳定;GLM 的最高使用量一度超过 10%,但并不稳定,起伏波动较大。
总结来说,国产模型呈现出一超(DeepSeek )三强(Qwen、GLM、Kimi)局面。
趋势二:
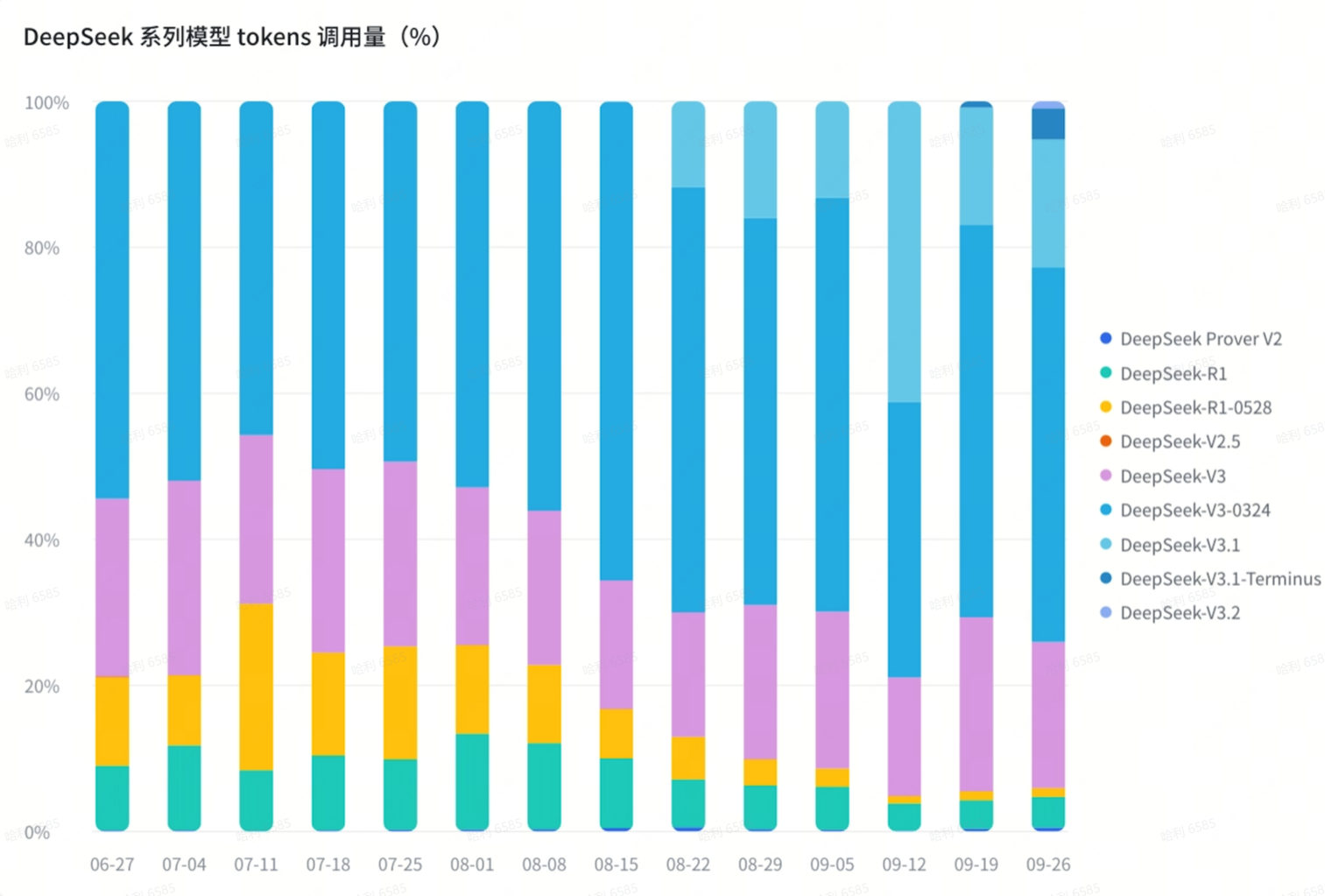
R1 推理模型热度下降,V3 基座模型更受欢迎
DeepSeek 有两大系列:基座模型 V3 系列和推理模型 R1 系列,两者的用量在 Q3 发生了显著的变化。
在Q3,推理模型 DeepSeek-R1 和 DeepSeek-R1-0528 的累计使用量占比逐渐减少,从最高时的超过 30% 下滑到 9 月底的 5% 左右;与之相反的是,基座模型 DeepSeek V3 以及后续更新的版本DeepSeek V3.1、DeepSeek-V3.1-Terminus 和 DeepSeek V3.2,使用量占比逐渐上升,最高累计占比 95% 左右。
这一现象说明了 DeepSeek V3 以及后续基座模型的更新版本,正在凭借更低的成本、更短的处理时间赢得更多的用户。
在 V3 系列中,DeepSeek-V3-0324 是使用量最大的模型,大约占比 50%-60%。DeepSeek-V3-0324 虽然是 DeepSeek-V3 的更新版本,但并没有完全取代 DeepSeek-V3,后者仍然维持了 20% 左右的占有率;与之相似的是,DeepSeek-V3.1 的发布也并未取代 DeepSeek-V3-0324,前者只占比 15% 左右。
在 9 月末,DeepSeek 重磅更新了引入线性注意力机制的 DeepSeek-V3.2-Exp,API 价格大幅下降。
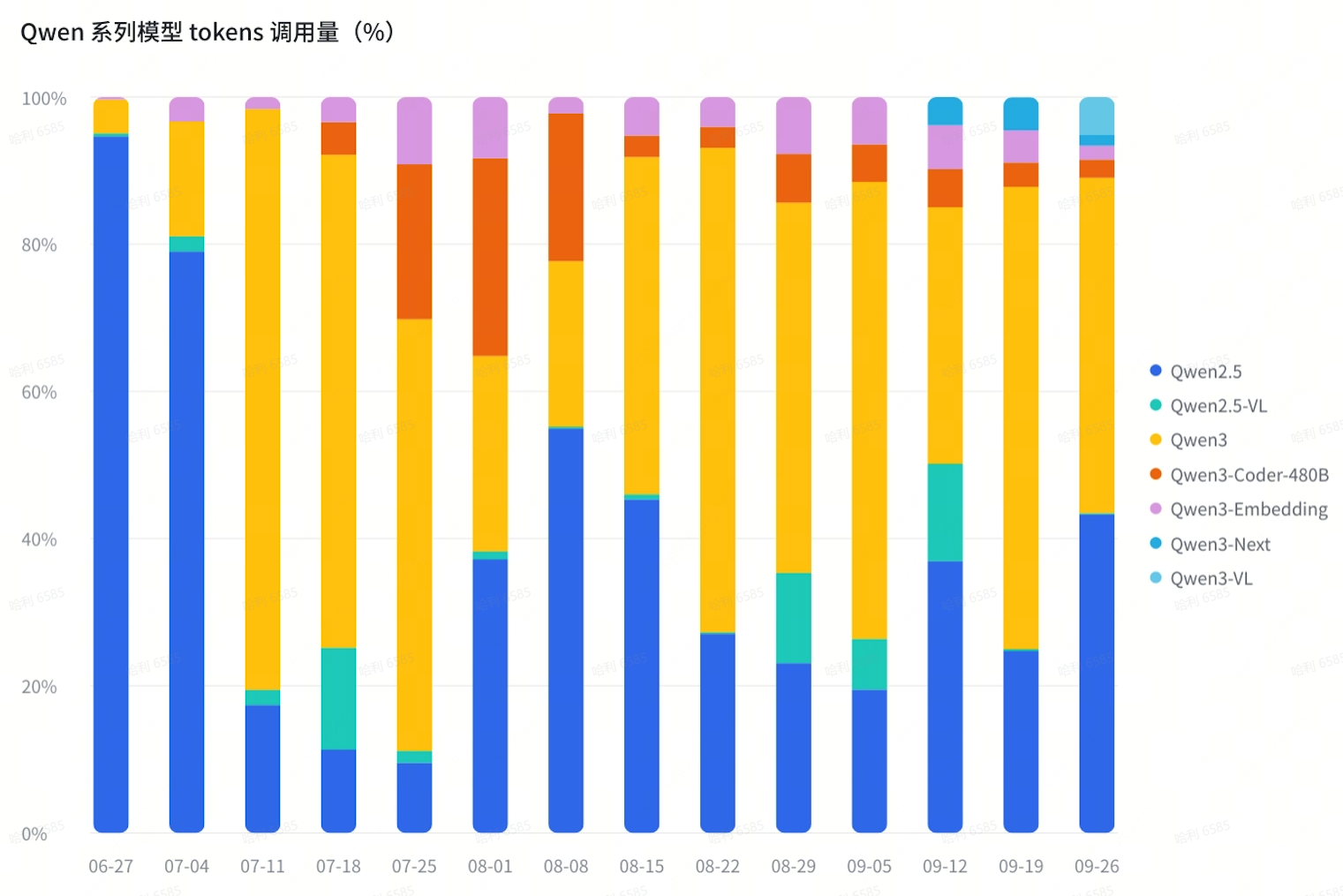
趋势三:Qwen “饱和式发布”
阿里 Qwen 系列采用“饱和式发布”策略,先后发布不同版本、不同尺寸、不同模态的模型,满足用户不同场景下的需求。
以 Qwen3 系列为例,分为稠密模型与 MoE 模型,稠密模型有 4B、8B、32B 等尺寸,MoE 模型有 30B、235B 等尺寸,以及采用了稀疏注意力架构的 Qwen3-Next 系列。此外,Qwen3 还包括视觉理解模型 VL 系列、编码模型 Qwen3-Coder、多模态模型 Omni、嵌入模型(Embedding)等。
Qwen3 的语言模型使用量最大,占比在 45%-60% 左右;其次是代码模型 Qwen3-Coder-480B,使用量占比最高达 26%,最终回落到 5% 以下;其他新架构、新模态的使用量占比分别在 5% 左右。
Qwen-2.5 系列的语言模型并没有被淘汰,仍然保持了较高的使用占比,大约在 20%-40% 之间。
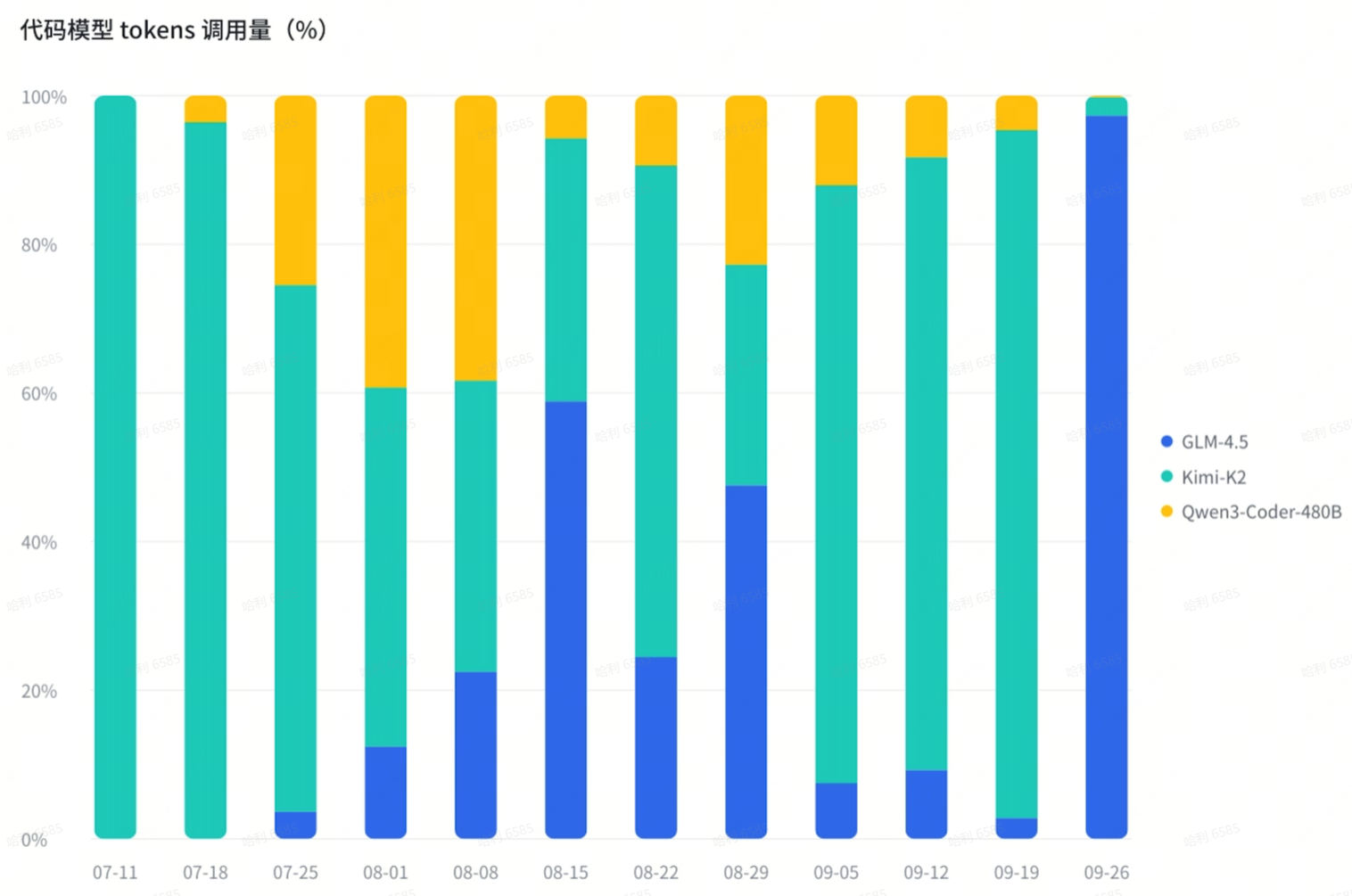
趋势四:国产模型齐发力代码编程
国产模型在 Q3 同时发力代码模型。在 DeepSeek V3 系列之外,Kimi-K2(及 Kimi-K2-0905)、Qwen3-Coder-480B 和 GLM-4.5 是其中的代表。
整体而言,三家代码模型的调用量波动较大,Kimi-K2 的使用量较高,最低时也在 30% 左右;Qwen3-Coder-480B 最高占比达到 40%,最低时仅为 5%;GLM-4.5 最高占比达到 95% 以上,但最低时仅为 3%。
此前,我们曾专门测评四大国产代码模型的编程能力,点击查看:横向对比四款国产模型的编程能力:谁能替代Claude?
趋势五:多模态模型或是下一阶段的热点
除了大语言模型,多模态(视觉理解模型与视觉生成模型)也是非常值得关注的方向。
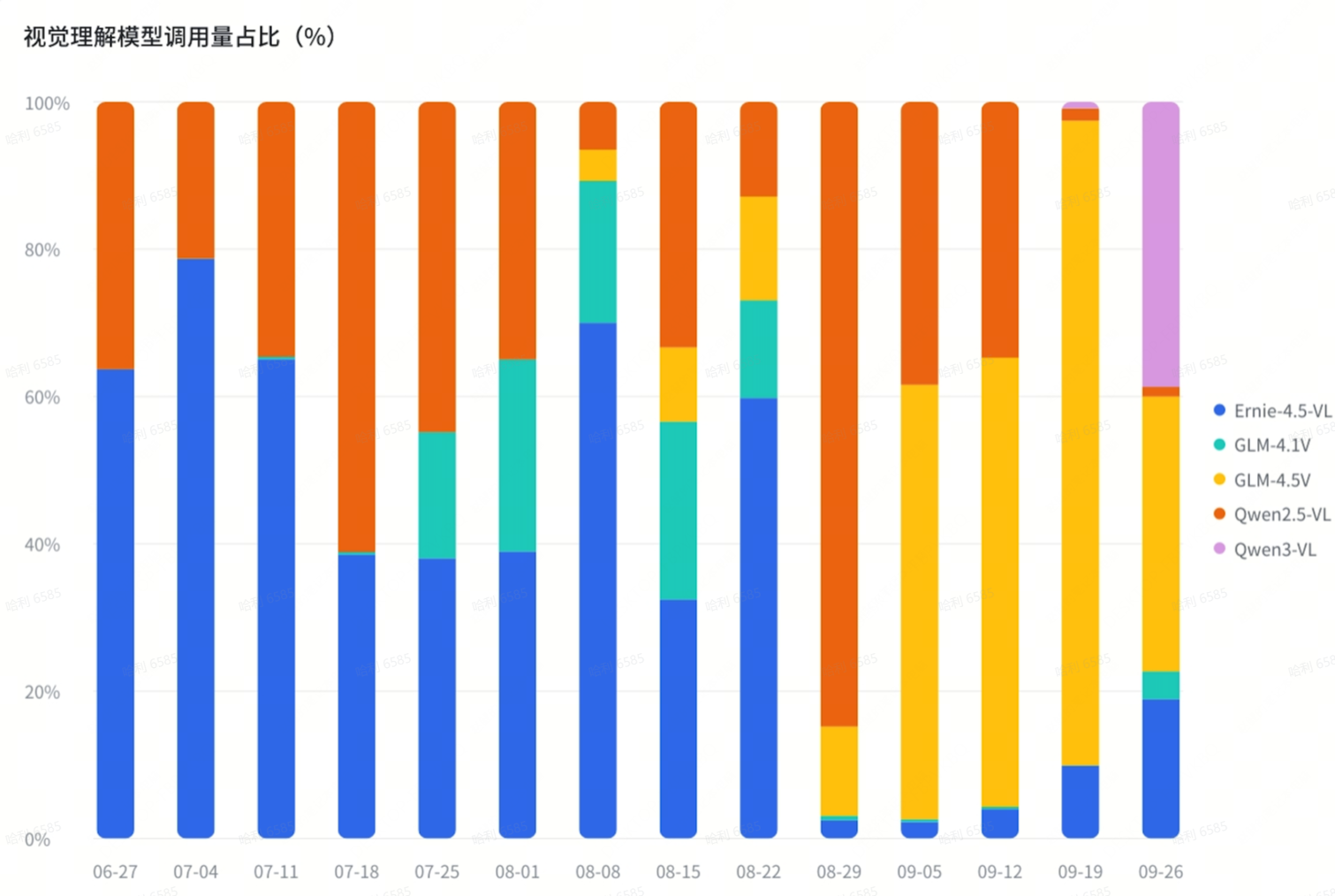
在视觉理解模型领域,阿里Qwen、百度Ernie 和智谱 GLM 三家你翻唱罢我登场。
7 月份,百度的 Ernie-4.5-VL 与阿里的 Qwen2.5-VL 分别占据半壁江山;
8 月份,GLM-4.1V 上线后占据大约 25% 的使用量;
9 月份,GLM-4.5V 上线后使用量高速增长,使用占比最高超过 85%;
9 月底,最新上线的 Qwen3-VL 很快占据了 38% 的使用量。
随着 Sora 2 的发布,多模态生成模型将大大推动内容生产力的变革。
在多模态生成模型领域,PPIO 先后上线了即梦文生图、Qwen-Image 等业内领先的文生图模型,以及产品评测(点击查看:PPIO上线Seedream 3.0和Qwen-Image:谁是更好的文生图模型?),以及 MiniMax Hailuo 02、Wan 2.2、Vidu 2.0、Seedance V1 Pro 等视频生成模型,更多模型也将陆续上线 PPIO 。
关于第三季度国产大模型调用量趋势,你还有哪些观察?欢迎在评论区补充。Q3 以及上半年 tokens 数据图表可以点击【阅读原文】下载原文档。
关于PPIO
PPIO 是中国领先的独立分布式云计算服务商,由 PPTV 创始人、前蓝驰创投投资合伙人姚欣和前 PPTV 首席架构师王闻宇于2018年联合创立,致力于为人工智能、智能体、实时音视频处理、具身智能等新一代场景,提供极致⾼性价⽐、超弹性、低延迟的⼀站式智算、模型及边缘计算服务。
根据 CIC (China lnsights Consultancy) 的资料,按2024年收入计,PPIO 是中国最大的独立边缘云公司,运营着中国最大的算力网络。按日均 tokens 消耗量计,在中国独立 AI 云公司中位列前二名。
现在用邀请码【24CGOJ】注册还可得 15 元代金券。
如果你有大模型 API 或者 Sandbox、GPU 云等专属需求,可扫码联系我们 👇




