
当Agent计算规模扩大100倍,我们需要什么样的Agentic Infra?

近期,PPIO Sandbox(沙箱)发布了一个重要功能:沙箱克隆。
沙箱克隆旨在助力提高 Agent 的并行计算能力,也就是经典的“Scale up”规模扩展问题。
今年最流行的 Agent 产品是 Deep Research,它可以看作对单个研究问题持续追踪、推演、迭代直到形成洞察的长链路串行推理过程。
那么,如果将 Deep Research 的能力 Scale up 一百倍会发生什么?像 Manus 这样的 Agent 正在解决这类挑战,并将这种并行计算架构的 Agent 称之为 Wide Research。
从 Agent 的串行计算到并行计算,离不开“沙箱克隆”这一核心技术的助力,这是 PPIO 在 Agentic Infra 方向正在做的事情之一。
# 01
上下文窗口的根本性瓶颈
在介绍沙箱克隆之前,有必要先解释一下 Deep Research 产品做串行任务的瓶颈。
比如,大多数人都会遇到这样一个令人沮丧的现实,在多主题研究任务中,到第八或第九个项目时,AI 就开始编造内容。
是因为模型的上下文窗口太小吗?众所周知,模型的上下文窗口就是一个有限的记忆缓冲区,限制了模型在任何给定时刻可以主动处理的信息量,扩展上下文窗口就是扩展模型的记忆能力。最新的前沿大模型已经大大扩展了上下文窗口的边界,从 4K 到 32K、128K,甚至 1M+ tokens。
然而,更大的上下文窗口却并不能从根本上解决 Agent 的记忆瓶颈。Agent 的 Scale up,不仅仅是提示词工程问题,也不仅仅是模型的问题,而是一个架构约束——单线程、顺序处理的范式无法突破这种约束。
Manus 在近期的博客中解释了这一现象。模型的检索准确性会随着当前位置的距离而下降,即"迷失在中间"现象。上下文开头和结尾的信息比中间的信息更可靠地被回忆起来。即使是无限上下文,要求单个模型在数十个独立研究任务中保持一致的质量也会产生认知瓶颈。
其中原因跟后训练数据有关系。当前语言模型的后训练数据混合仍然主要由为聊天机器人式交互设计的相对较短的轨迹主导。因此,当消息内容的长度超过某个阈值时,模型自然会经历一种上下文长度压力,促使它加速总结或诉诸于不完整的表达形式,比如开始输出要点列表。
而且,处理更长的上下文也意味着成本是指数级的增长。
那么,要想应对大规模研究任务,应该如何处理?并行处理应运而生。
# 02
并行处理架构带来的Sandbox需求
日常办公中有一类场景天然适合并行计算架构,包括批量文档处理、多资产创意生成、大规模数据分析、复杂工作流分解等。这些任务的特点是,规模量大但任务类型相似,任务之间具有一定的独立性。
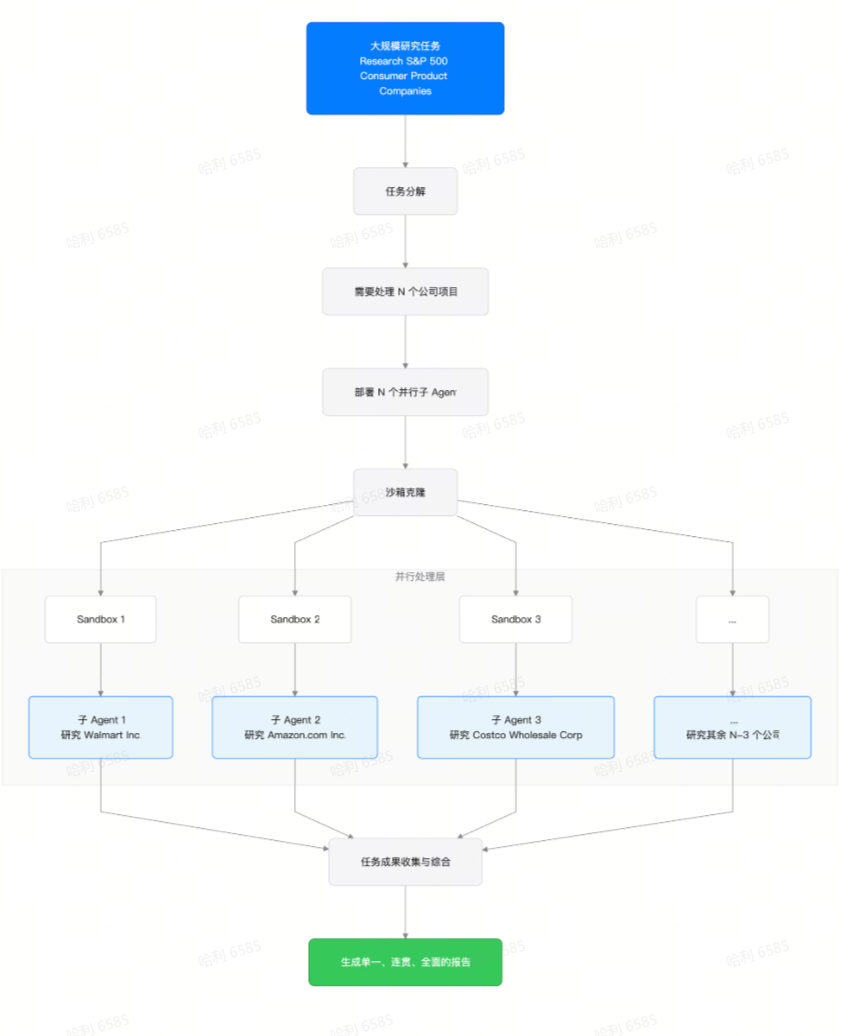
Agent 的并行计算不是要求一个处理器顺序处理 n 个项目,而是像影分身那样部署 n 个并行子Agent 同时处理 n 个项目,然后将子 Agent 的任务成果综合成一个单一的、连贯的、全面的报告。
也就是说,如果需要处理 50 个项目,那就部署 50 个子 Agent ;如果要处理 500 个项目,那就部署 500 个。架构随任务大小线性扩展,而不是像基于上下文的方法那样呈指数级扩展。
最核心的变化在于,子 Agent 之间互相独立。每个子 Agent 都拥有完整的 Sandbox 运行环境,全新的、空的上下文窗口,以及完整的工具库和独立的互联网连接。
因为子 Agent 并行操作,分析 50 个项目所需的实际时间与分析 5 个项目大致相同。即使单个子 Agent 出现错误或幻觉也不会传播到其他子 Agent。这大大降低了整个 Agent 系统的幻觉。
我们知道,Agent 的运行离不开 Sandbox 环境,而现阶段的 Sandbox 通常服务于串行计算的 Agent 架构。当 Agent 架构开始从串行计算往并行计算发展的时候,Sandbox 也相应地需要满足并行计算的要求。
这一功能,就是沙箱克隆。
# 03
PPIO 上线“沙箱克隆”功能
PPIO 在今年7月正式发布 Sandbox 产品,已上线 Computer Use、Browser-use、Code Interpreter 等基础功能。
近期,PPIO 发布了沙箱实例自动暂停和恢复、沙箱克隆、沙箱闲时释放等功能的 Beta 版本。其中,沙箱克隆允许复制正在运行或处于暂停状态的沙箱实例,克隆出的沙箱和原沙箱的文件系统、内存状态保持一致。
借助 “沙箱克隆” 功能,Agent 实现了从 “深度单线探索”(Deep-Research)到 “广度并行探索”(Wide-Research)的架构转变:
- 多时间线探索架构:就像决策树一样,Agent 可以从同一个基准状态出发,创建多个独立的沙箱副本,每个副本探索一条不同的解决路径,互不干扰。
- 真正的并行计算能力:通过将大任务拆分成批量子任务,Agent 能够将计算能力扩展数十倍甚至上百倍,同时处理数十个、上百个探索分支。
- 零风险实验环境:克隆出的沙箱完全隔离,AI 可以在其中自由实验、测试各种可能性,而不会影响原始环境或开发者的主工作流程。
- 高效的资源利用:虽然可能同时启动多个沙箱实例,但通过动态管理和及时终止不再有价值的分支(沙箱实例),总体计算资源消耗可以保持在合理范围内。
这种能力使 Agent 能够突破当前的性能瓶颈,从提供理论建议转变为交付经过并行验证、实际测试的可靠方案,真正实现自主探索、迭代和解决复杂问题的能力。
关于更多沙箱克隆的信息,您可以到 PPIO 网站查看我们的开发者文档:
https://ppio.com/docs/sandbox/sandbox-clone
如果您正在探索并行计算的 Agent 架构,欢迎体验 PPIO 的沙箱克隆功能以及完整的 Agentic Infra 解决方案,您可以扫码以下二维码添加专属小助手进行进一步沟通。

参考文章:
Wide Research:超越上下文窗口



